

检索增强生成 / RAG
解决幻觉的这套方法,叫做 RAG (Retrieval-Augmented Generation),中文名称是检索增强生成。简单来说,RAG 就是让 AI 从凭空想象变成了有据可查,这是构建专业 AI 应用最核心的技术之一。而它的名字已经包含了这三个步骤。 1. 检索(Retrieval)- 找菜谱 根据用户的提问,从知识库中检索(查询)出最相关的信息片段。这就好比听到菜名宫保鸡丁,你先去找到这道菜的菜谱。 2. 增强(Augmented)- 拿到菜谱和准备食材 将检索到的信息片段(上下文),与用户的原始问题一起,组合并转换成给大型语言模型一个更新且更丰富的提示词(Prompt)。你可以理解为把这份菜谱放在手边,方便你随时查阅,同时准备好对应的食材。 3. 生成(Generation)- 烹饪 大语言模型根据这个包含上下文的新提示词(Prompt),生成一个有事实依据的和更准确的回答。你按照菜谱上的步骤,完成烹饪宫保鸡丁。知识检索 (Knowledge Retrieval) 节点
这就像是给 AI 邮件助理旁边,放了一些资料。它会先根据用户的问题,在这本小抄里查找最相关的那几页,然后把找到的内容连同用户的问题一起进行思考。 在接下来的动手实践中,我们将使用知识库检索节点,给我们的 AI 邮件助理一些官方的小抄,让它在回答之前有据可查。动手实践 1:创建知识库
进入知识库
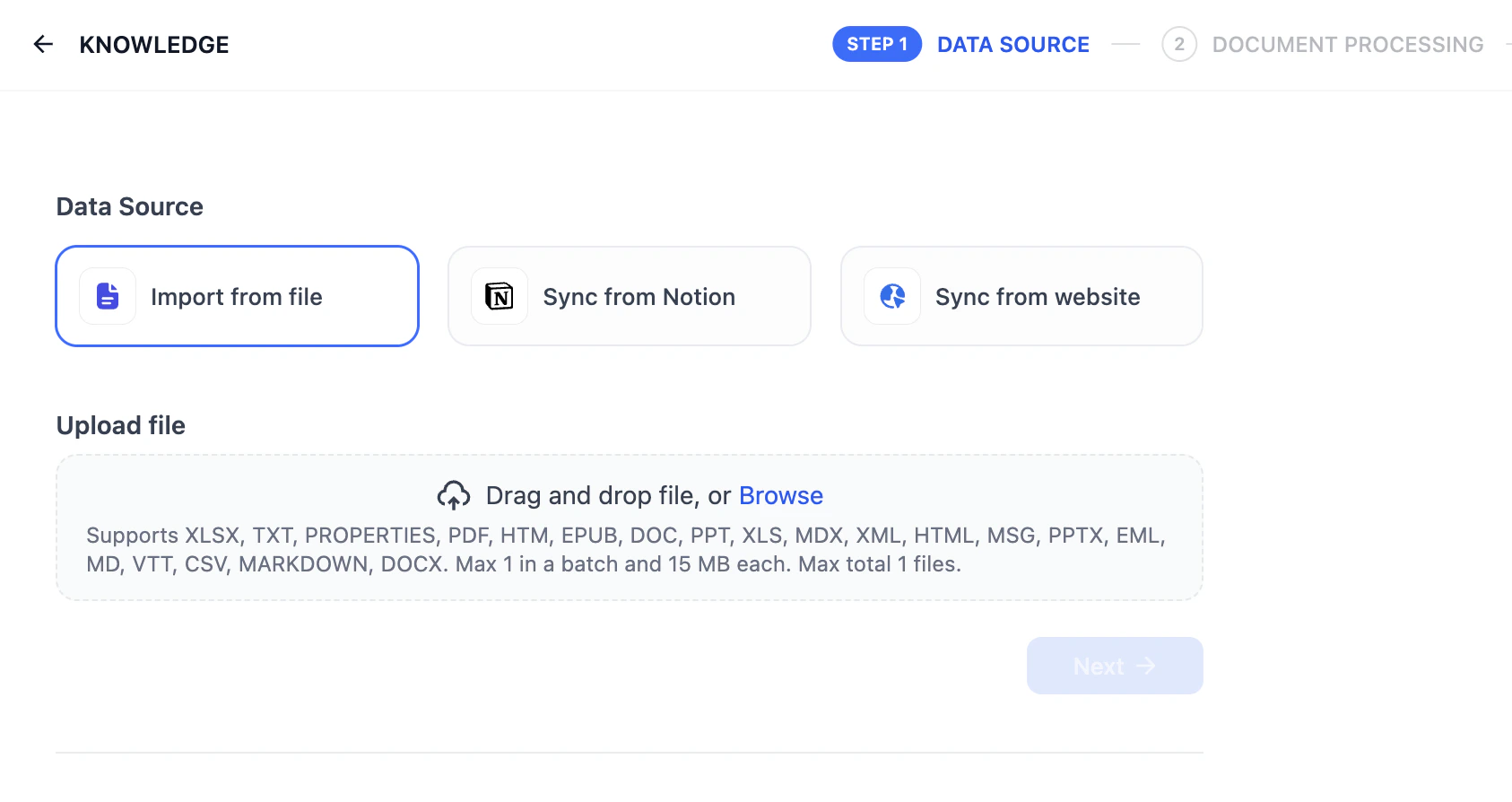
点击顶部的知识库,在左侧点击创建知识库。
文本分段与清洗
你可以把这里当作一个文本预处理的步骤。因为 AI 在检索信息时,直接阅读一整篇长文档效率很低。所以在这个页面,Dify 会自动帮你把文档切成更小的、逻辑连贯的段落(就像把一本书拆分成一张张知识卡片),并去掉一些不必要的格式,方便后续的检索和理解。分段设置此处自动将你的长文本切分成更易于检索的小段落。我们保持选择通用模式即可。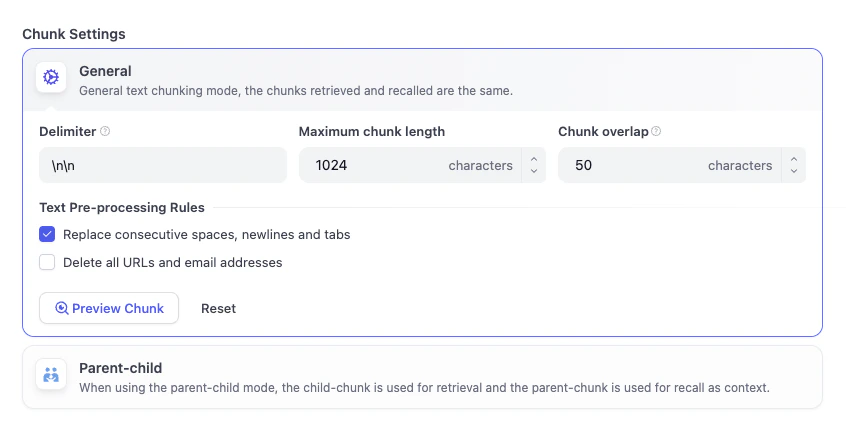

- 高质量:会消耗 Token 调用 AI 模型来处理文本,让检索结果更精准。
- 经济:不消耗 Token,但会牺牲一定的准确性。
检索设置
文档处理完成后,我们需要对召回设置进行最后一次检查。在这里,你可以配置 Dify 查找信息的方式。在经济模式下,检索设置仅支持倒排索引。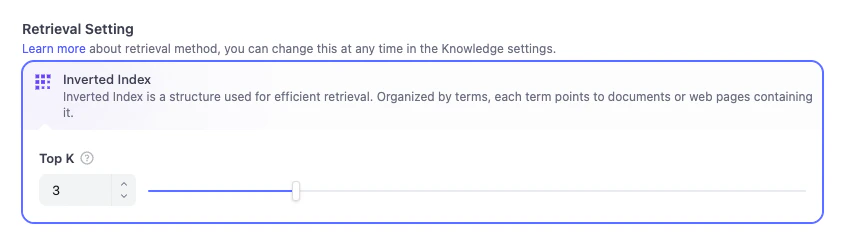
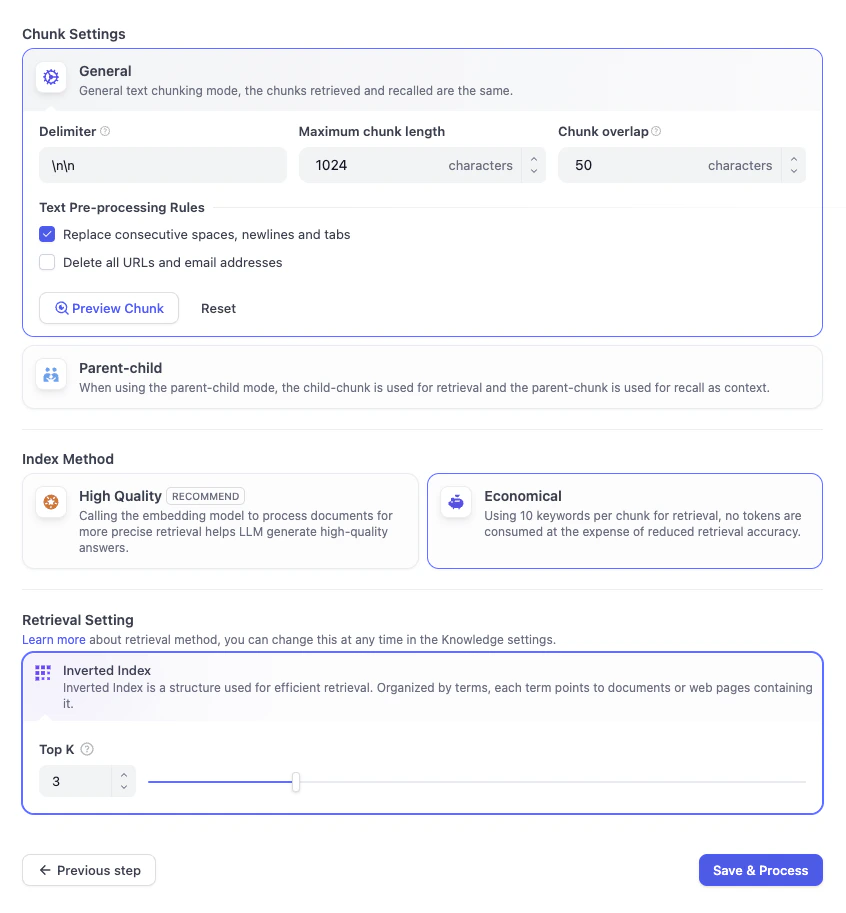
- 倒排索引 这是 Dify 使用的默认结构。可以把它想象成实体书背面的索引页——它列出了关键术语,并准确告诉 Dify 这些术语出现在哪些页面上。这让 Dify 能够根据关键词立即跳转到正确的知识卡片,而不是从头到尾阅读整本书。
- Top K 你会看到一个设置为 3 的滑动条。这告诉 Dify:当用户提出问题时,从手册中找出前 3 张最相关的知识卡片展示给 AI。如果你将其设置得更高,AI 会获得更多的上下文参考,但如果设置得过高,过量的信息可能会让 AI 难以处理。
太棒了!你已经成功创建了第一个知识库。接下来我们将使用知识库升级我们的 AI 邮件助理。
动手实践 2:添加知识检索节点
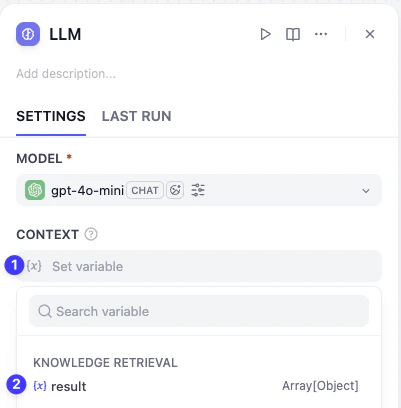
这样,邮件助理就会以客户的邮件原文作为关键词,去知识库中检索最相关的答案了。
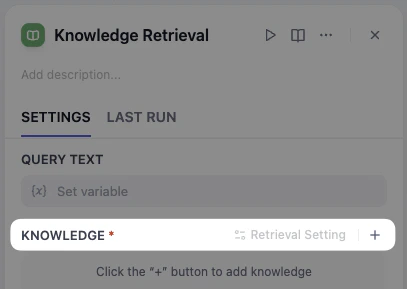
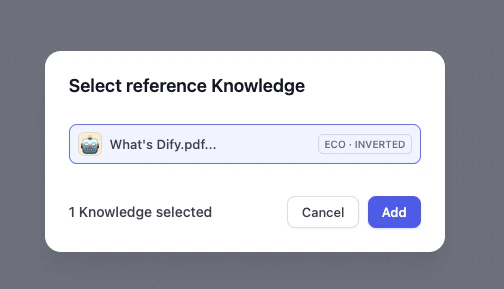
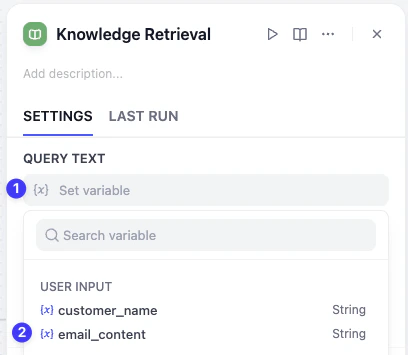
动手实践 3:升级 AI 邮件助理
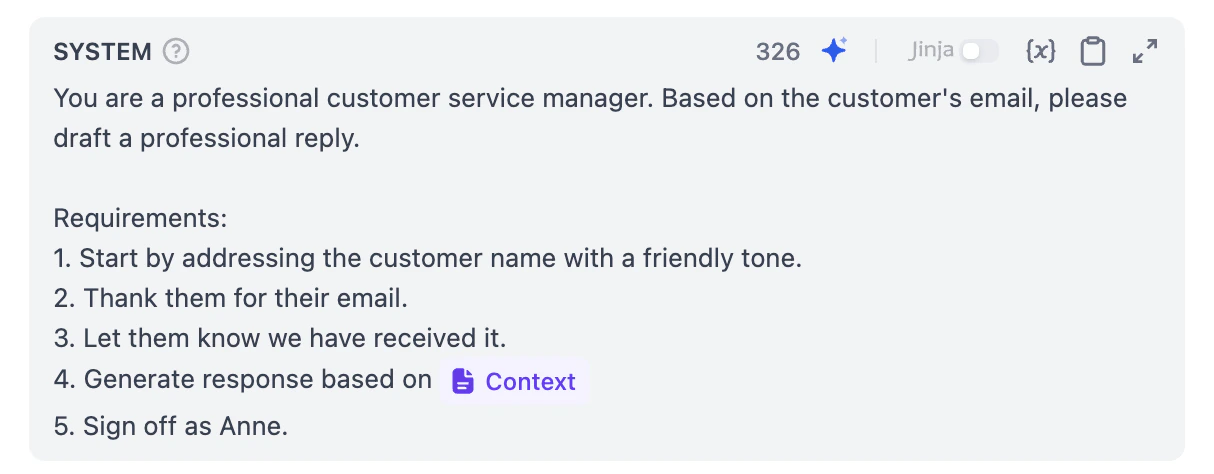
上下文已经准备好了,我们还需要在提示词(Prompt)里告诉大型语言模型先阅读这份资料,再生成邮件回复。
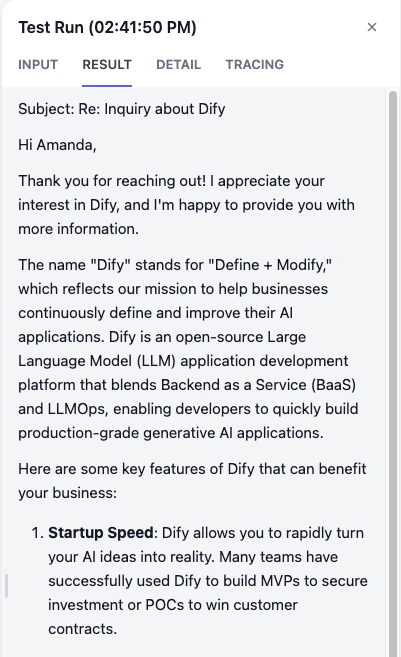
太棒了! 你已经完成了本次课程中最具挑战性的一步。你的邮件助理现在不仅拥有了大脑,更拥有了一本可以随时查阅的小抄。让我们来看看效果如何吧。
你可以直接使用下方的邮件示例,点击运行进行测试。
小挑战
- 在刚才的工作流中,如果用户的提问超出了知识库的内容,该如何应对这样的情况?
- 在你自己的工作或学习中,有哪些信息可以被制作成知识库?
- 探索文本分段与清洗页面中,分段设置和检索设置、索引方式和默认配置的三者关系。