

このドキュメントは AI によって自動翻訳されています。不正確な部分がある場合は、英語版 を参照してください。質問分類器ノードは、ユーザー入力をインテリジェントに分類して、会話を異なるワークフローパスにルーティングします。複雑な条件ロジックを構築する代わりに、クラスを定義すると、大規模言語モデルがセマンティック理解に基づいて最適なものを判断します。
設定
入力とモデルの設定
入力変数 - 分類する内容を選択します。通常はユーザーの質問に対してsys.query を使用しますが、上流のワークフローノードからの任意のテキスト変数も使用できます。
モデル選択 - 分類用の大規模言語モデルを選択します。単純なクラスには高速なモデルで十分ですが、微妙な区別にはより高性能なモデルが適しています。
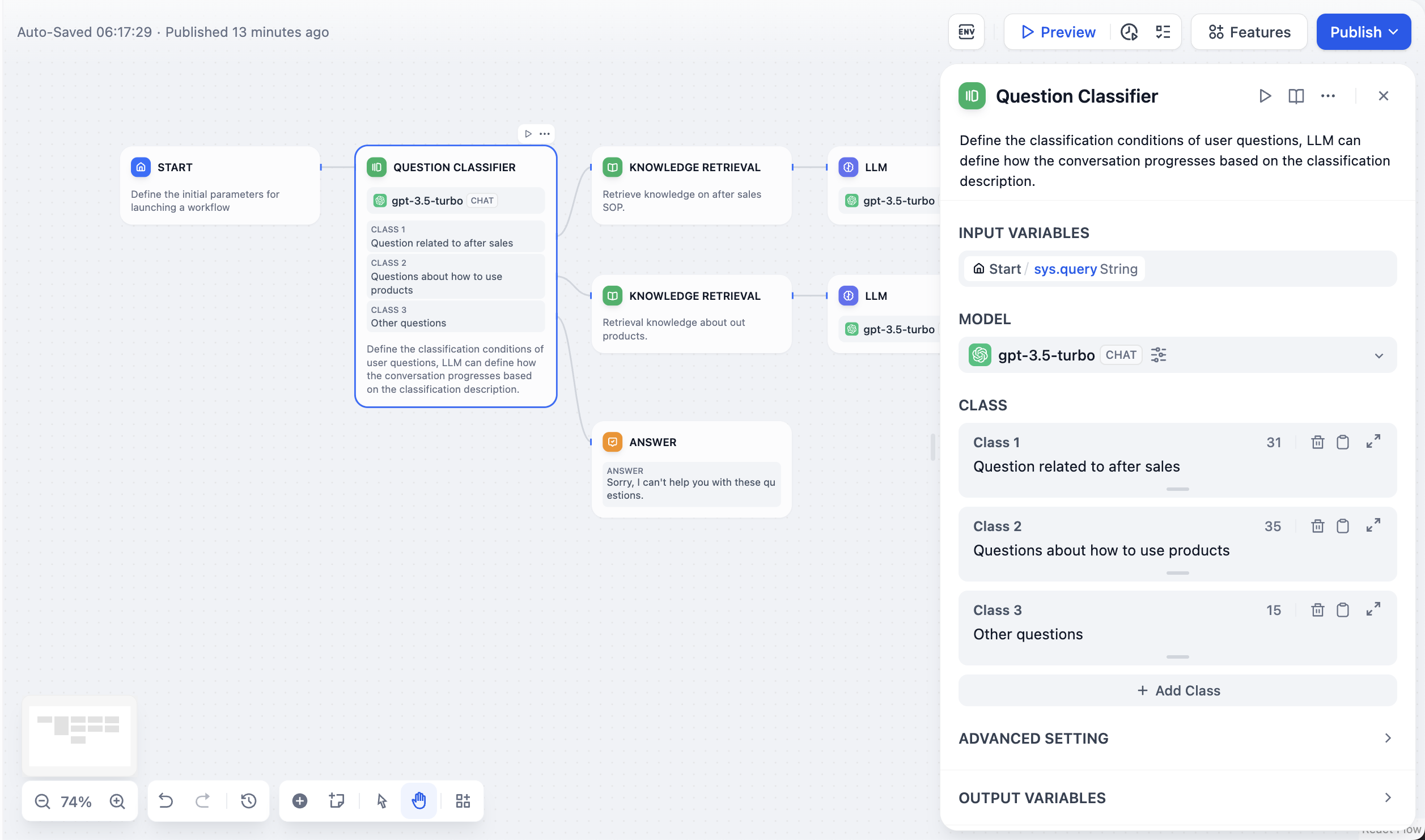
クラスの定義
各クラスには独立した 2 つのテキストがあります:-
クラス説明(エディタ本文)は、モデルが分岐を選ぶ際に参照する内容です。
クラスに属する内容を正確に区別できる説明を記述します。クラスが重なる場合は、「〜に関するもの」「〜を除く」などの境界フレーズが判断の助けになります。下流では
class_nameとして出力されます。 -
クラスタイトル(エディタ上部の小見出し)は、キャンバスに表示されるラベルです。
デフォルトの クラス N タイトルをダブルクリックして名前を変更できます。下流では
class_labelとして出力されます。
分類例
以下は、カスタマーサービスシナリオでの質問分類器の使用例です: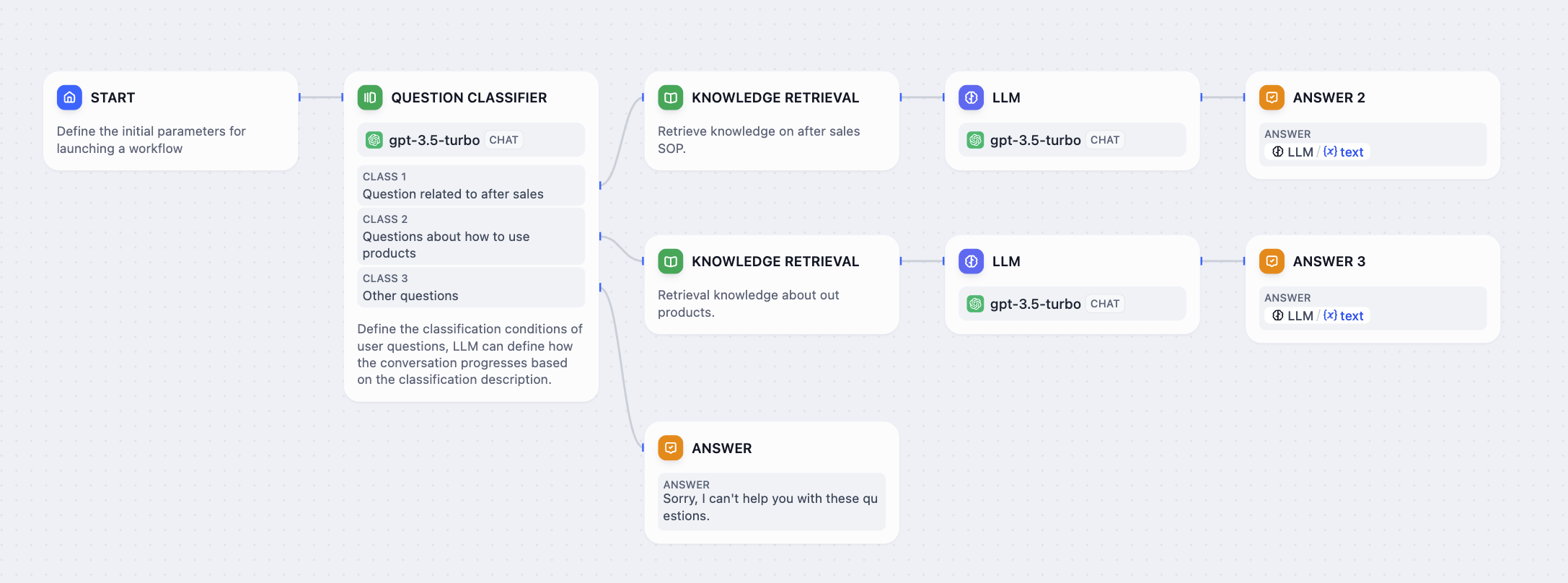
カスタマーサービス分類ワークフロー
- アフターサービス - 保証請求、返品、修理、購入後サポート
- 製品使用 - セットアップ手順、トラブルシューティング、機能説明
- その他の質問 - 上記のクラスに該当しない一般的な問い合わせ
- 「iPhone 14 で連絡先を設定する方法は?」 → 製品使用
- 「購入品の保証期間はどのくらいですか?」 → アフターサービス
- 「今日の天気はどうですか?」 → その他の質問