

このドキュメントは AI によって自動翻訳されています。不正確な部分がある場合は、英語版 を参照してください。コードノードは、カスタム Python または JavaScript を実行して、ワークフロー内で複雑なデータ変換、計算、ロジックを処理します。事前設定されたノードが特定の処理ニーズに十分でない場合に使用してください。
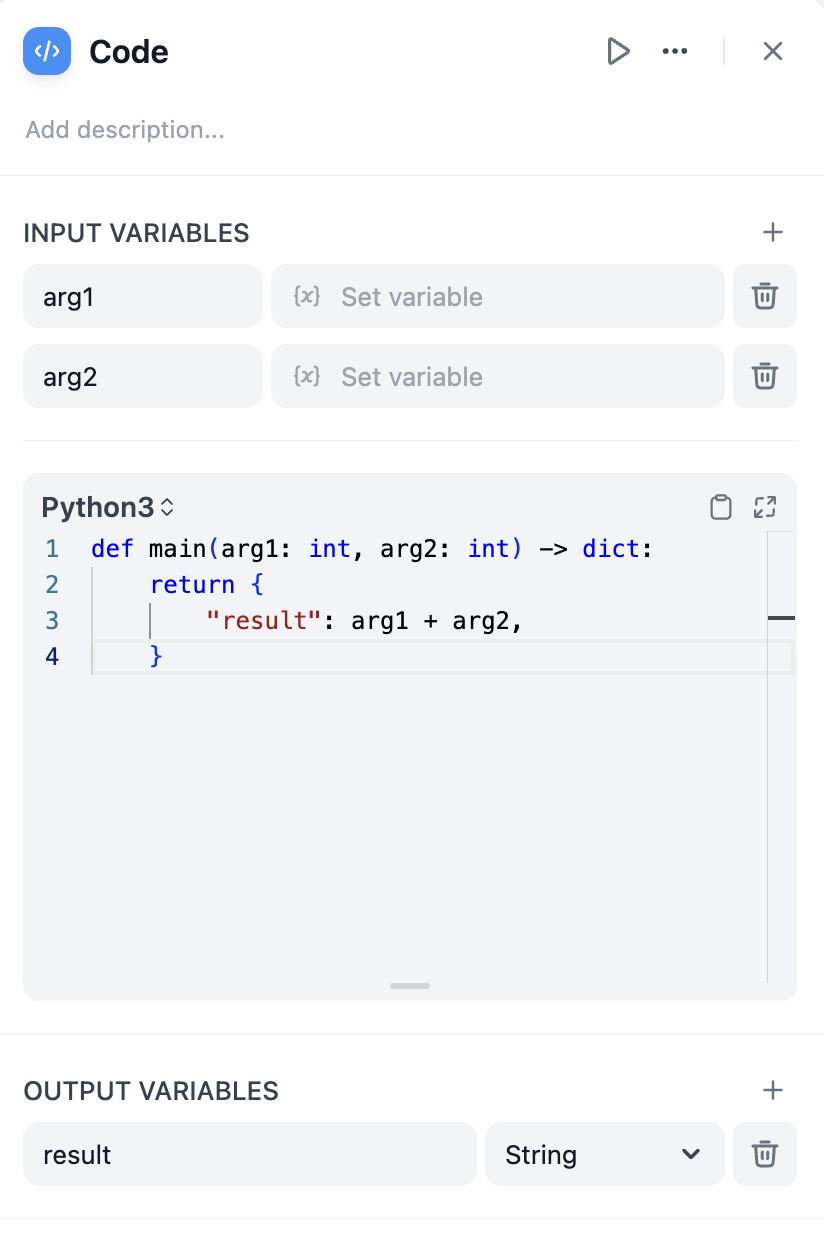
コードノード設定インターフェース
設定
入力変数 を定義してワークフロー内の他のノードからデータにアクセスし、これらの変数をコード内で参照します。関数は、宣言した出力変数 を含む辞書を返す必要があります。言語サポート
ニーズと習熟度に基づいて、Python と JavaScript から選択できます。どちらの言語も、データ処理用の一般的なライブラリにアクセス可能な安全なサンドボックス内で実行されます。- Python
- JavaScript
Python には
json、math、datetime、reなどの標準ライブラリが含まれています。データ分析、数学的演算、テキスト処理に最適です。エラーハンドリングと再試行
失敗したコード実行に対する自動再試行動作を設定し、コードがエラーに遭遇した場合のフォールバック戦略を定義します。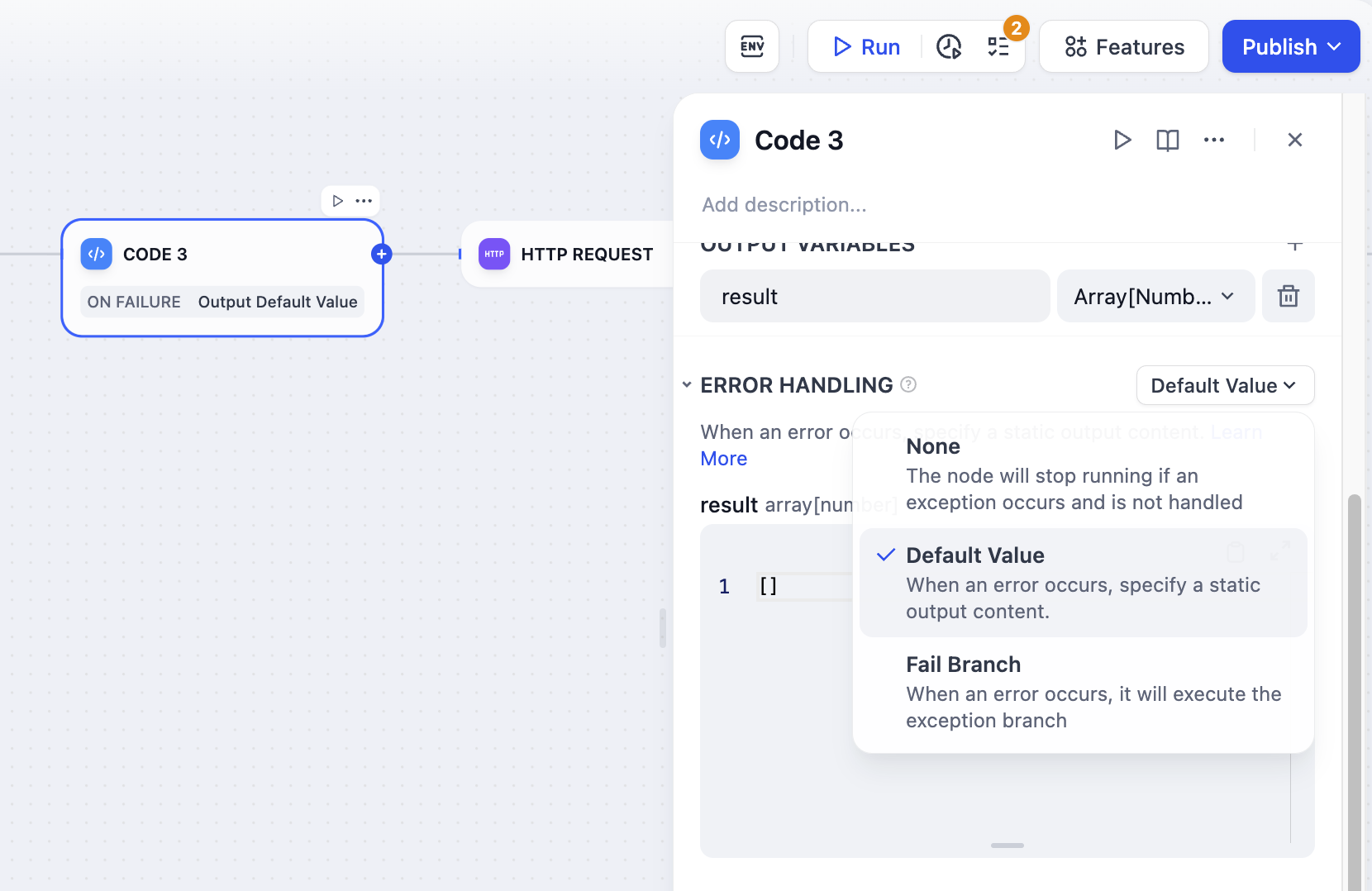
エラーハンドリング設定オプション
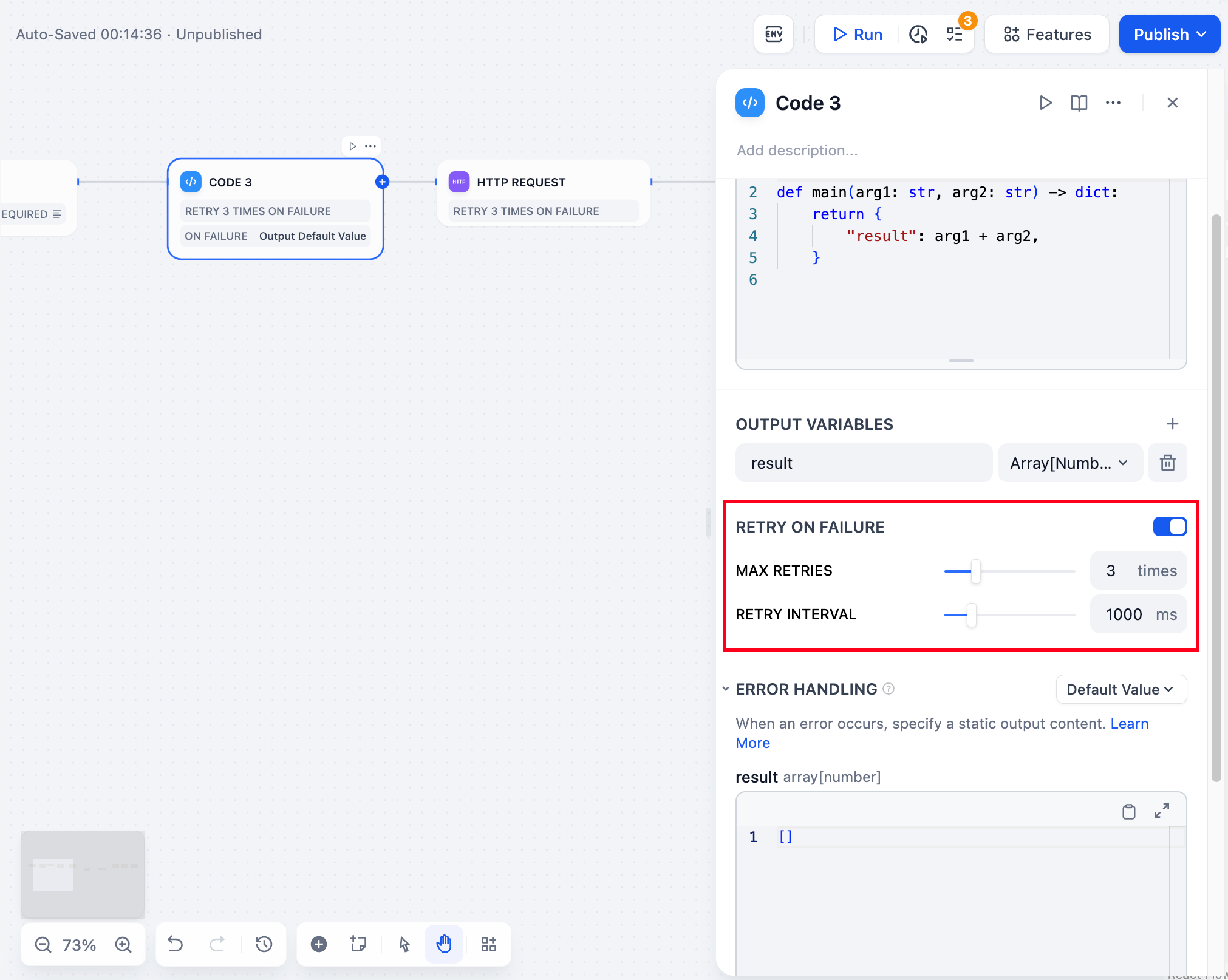
再試行設定インターフェース
出力制限
出力が次のノードに渡される前に、Dify は出力が大きすぎないかを確認します。- 文字列:最大 400,000 文字。
- 数値:整数は最大 19 桁、小数は最大 20 桁。
- オブジェクトと配列:ネストは最大 5 レベル。