

このドキュメントは AI によって自動翻訳されています。不正確な部分がある場合は、英語版 を参照してください。LLM ノードは大規模言語モデルを呼び出してテキスト、画像、ドキュメントを処理します。設定されたモデルにプロンプトを送信し、その応答を取得します。構造化出力、コンテキスト管理、マルチモーダル入力をサポートしています。
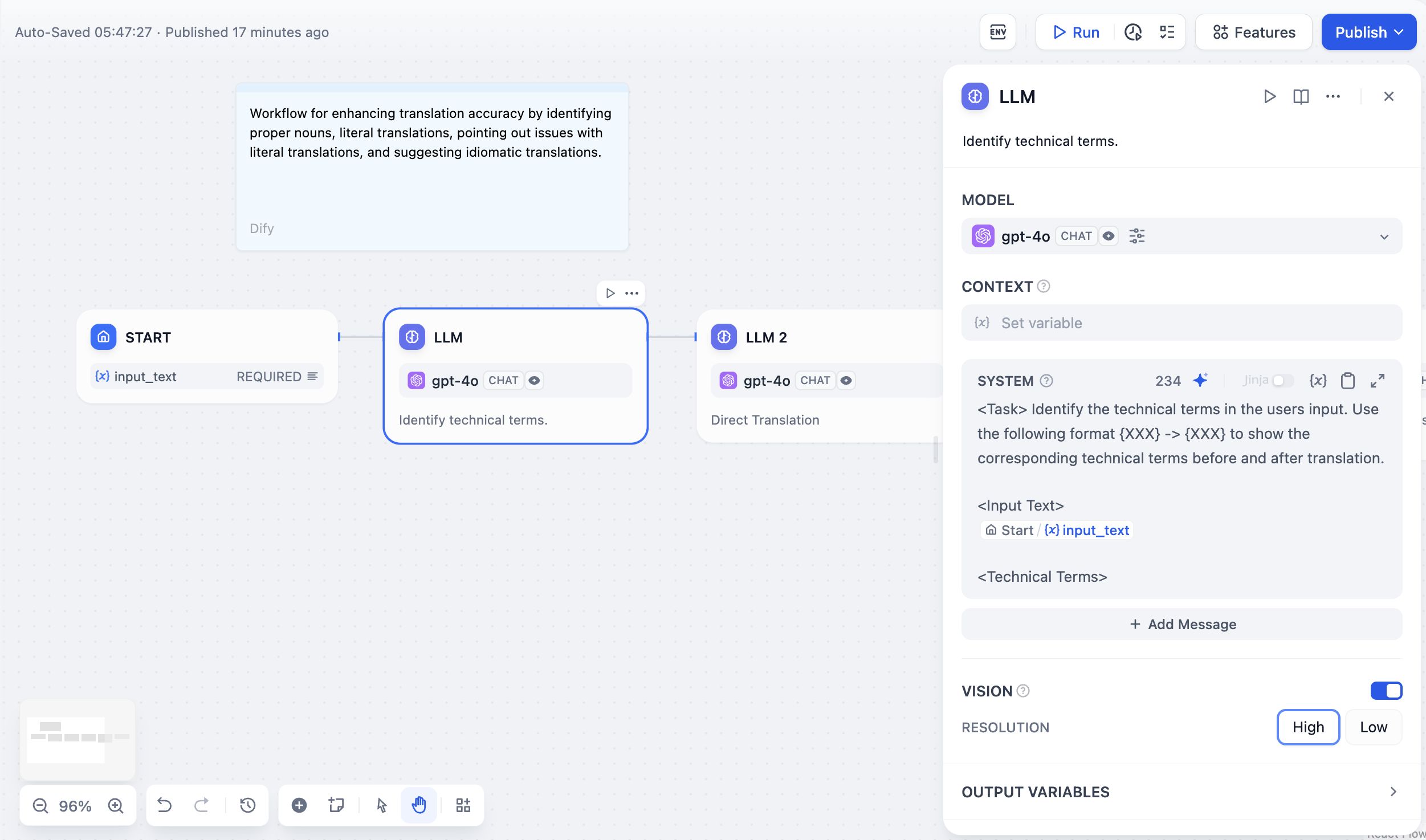
LLMノード設定インターフェース
LLM ノードを使用する前に、統合 > モデルプロバイダー で少なくとも 1 つのモデルプロバイダーを設定してください。
モデル選択とパラメータ
設定したモデルプロバイダーから任意のモデルを選択できます。異なるモデルはそれぞれ異なるタスクに適しています。GPT-4 と Claude 3.5 は複雑な推論を得意としますがコストが高く、GPT-3.5 Turbo は機能と価格のバランスが取れています。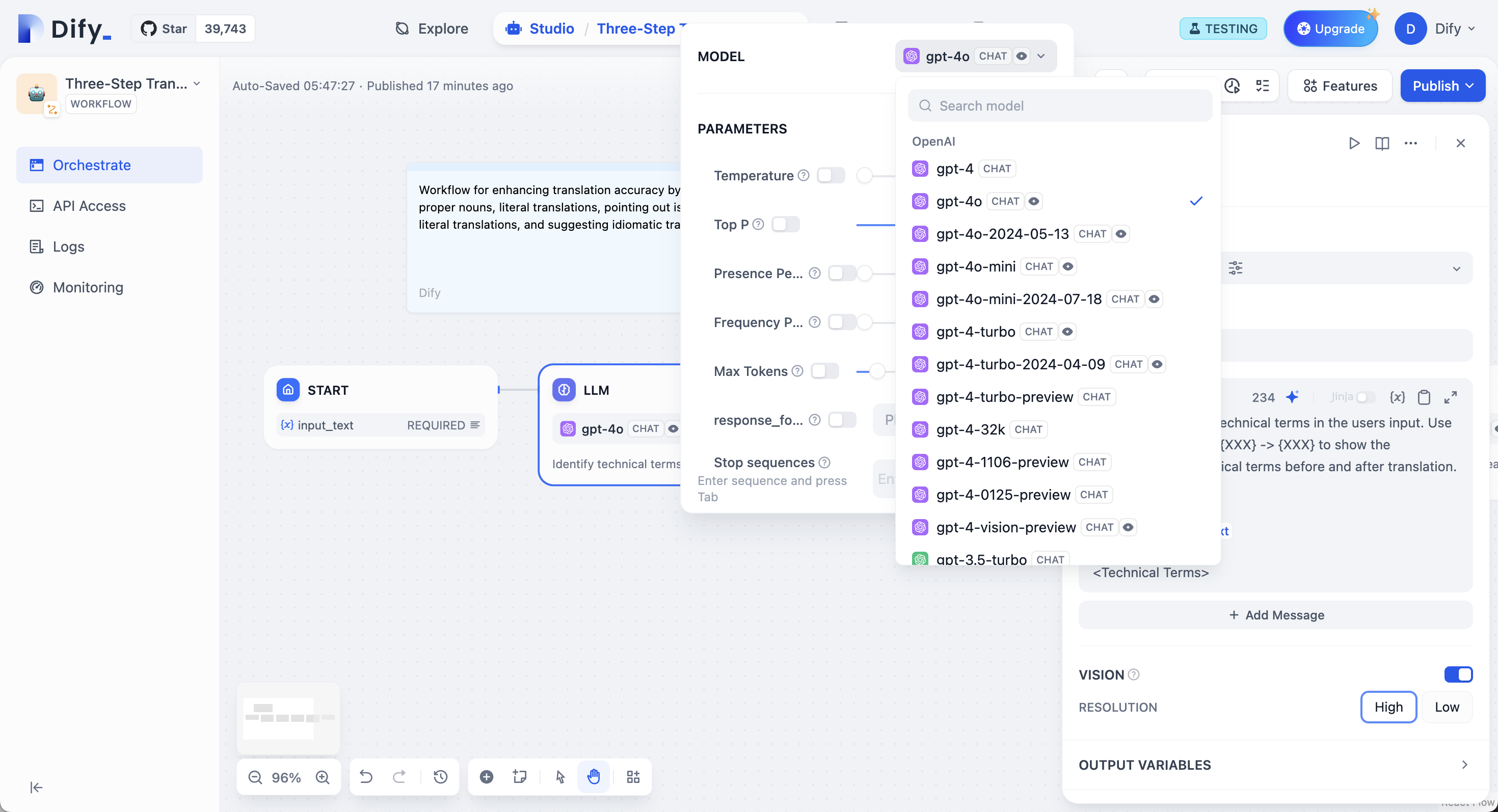
モデル選択とパラメータ設定
プロンプト設定
インターフェースはモデルタイプに基づいて適応します。チャットモデルではメッセージロール(システム は動作用、ユーザー は入力用、アシスタント は例用)を使用し、補完モデルでは単純なテキスト継続を使用します。 プロンプト内でワークフロー変数を二重中括弧で参照します:{{variable_name}}。変数はモデルに到達する前に実際の値で置き換えられます。
コンテキスト変数
コンテキスト変数はソース帰属を保持しながら外部知識を注入します。これにより、大規模言語モデルがあなたの特定のドキュメントを使用して質問に答える RAG アプリケーションが可能になります。
RAGアプリケーションでのコンテキスト変数の使用
構造化出力
プログラムで使用するために、JSON などの特定のデータ形式での応答をモデルに強制します。3 つの方法で設定できます:- ビジュアルエディター
- JSONスキーマ
- AI生成
シンプルな構造のためのユーザーフレンドリーなインターフェース。名前とタイプでフィールドを追加し、必須フィールドをマークし、説明を設定します。エディターは自動的に JSON スキーマを生成します。
メモリとファイル処理
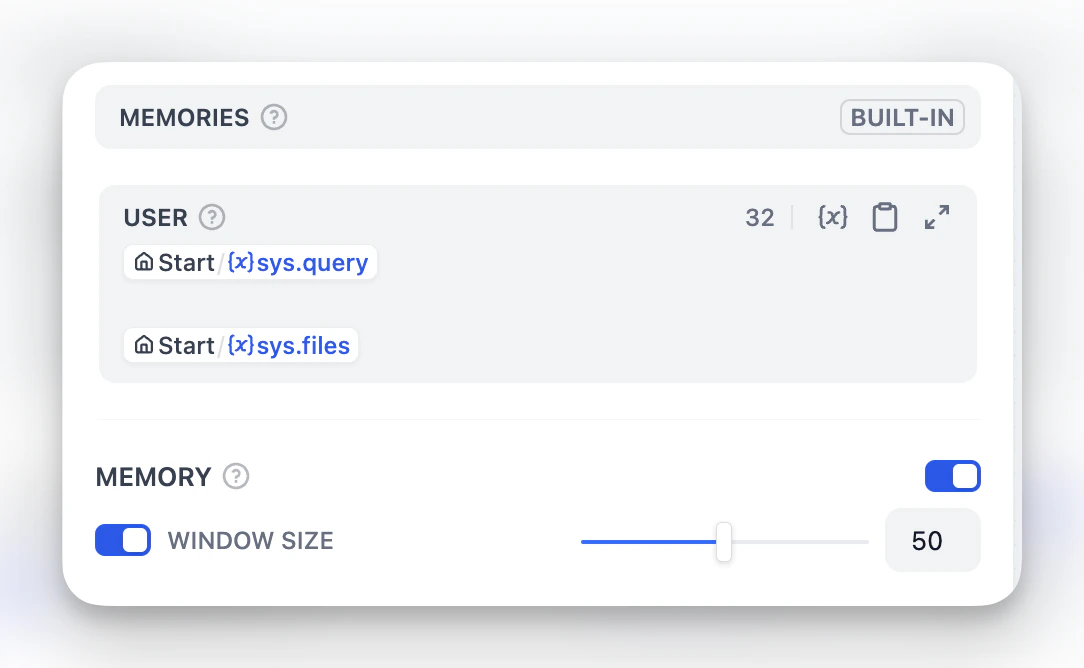
USERテンプレートを編集することで、ユーザープロンプトに入力される内容をカスタマイズできます。メモリはノード固有であり、異なる会話間では持続しません。
ファイル処理 では、マルチモーダルモデル用にプロンプトにファイル変数を追加します。GPT-4V は画像を、Claude は PDF を直接処理しますが、他のモデルでは前処理が必要な場合があります。
ビジョン機能設定
画像を処理する際、詳細レベルを制御できます:- 高詳細 - 複雑な画像でより良い精度を提供しますが、より多くのトークンを使用します
- 低詳細 - シンプルな画像でより少ないトークンでより高速な処理
userinput.filesで、ユーザー入力ノードからファイルを自動的に取得します。
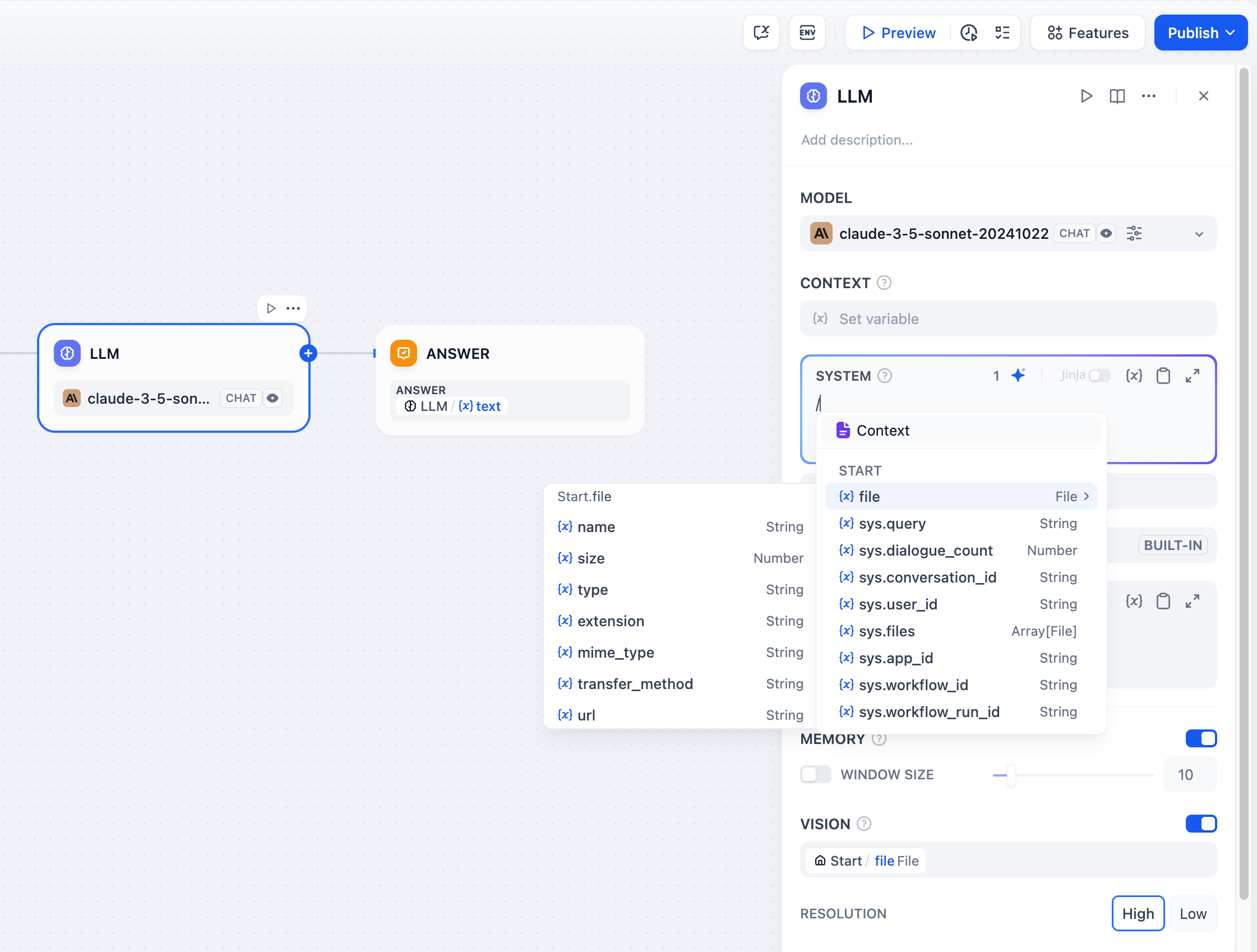
マルチモーダル大規模言語モデルでのファイル処理
Jinja2 テンプレートサポート
LLM プロンプトは高度な変数処理のために Jinja2 テンプレートをサポートしています。Jinja2 モード(edition_type: "jinja2")を使用すると、次のことができます:
ストリーミング出力
LLM ノードはデフォルトでストリーミング出力をサポートしています。各テキストチャンクはRunStreamChunkEventとして生成され、リアルタイムの応答表示が可能になります。ファイル出力(画像、ドキュメント)はストリーミング中に自動的に処理され保存されます。
回答からの推論の分離
一部の推論モデルは、思考を<think>...</think> タグで囲みます。デフォルトでは、これらのタグは text 出力に含まれるため、推論は回答とともに下流のノードへ流れます。
推論タグの分離を有効にする トグルをオンにすると、text 出力には回答のみが残り、思考は独立した reasoning_content 出力変数に格納されます。トグルがオフの場合、reasoning_content は空のままです。
API 呼び出しでは、このトグルは reasoning_format パラメータとして現れます。トグルがオンのとき、reasoning_format は separated になります。すると、ストリーミング API クライアントは推論を回答ストリームとは別の reasoning_chunk イベントとして受け取ります。イベントの詳細は チャットメッセージを送信 と ワークフローを実行 を参照してください。
この設定は、推論を
<think> タグで囲むモデルにのみ影響します。