

Documentation Index
Fetch the complete documentation index at: https://docs.dify.ai/llms.txt
Use this file to discover all available pages before exploring further.
⚠️ このドキュメントは AI によって自動翻訳されています。不正確な部分がある場合は、英語版 を参照してください。
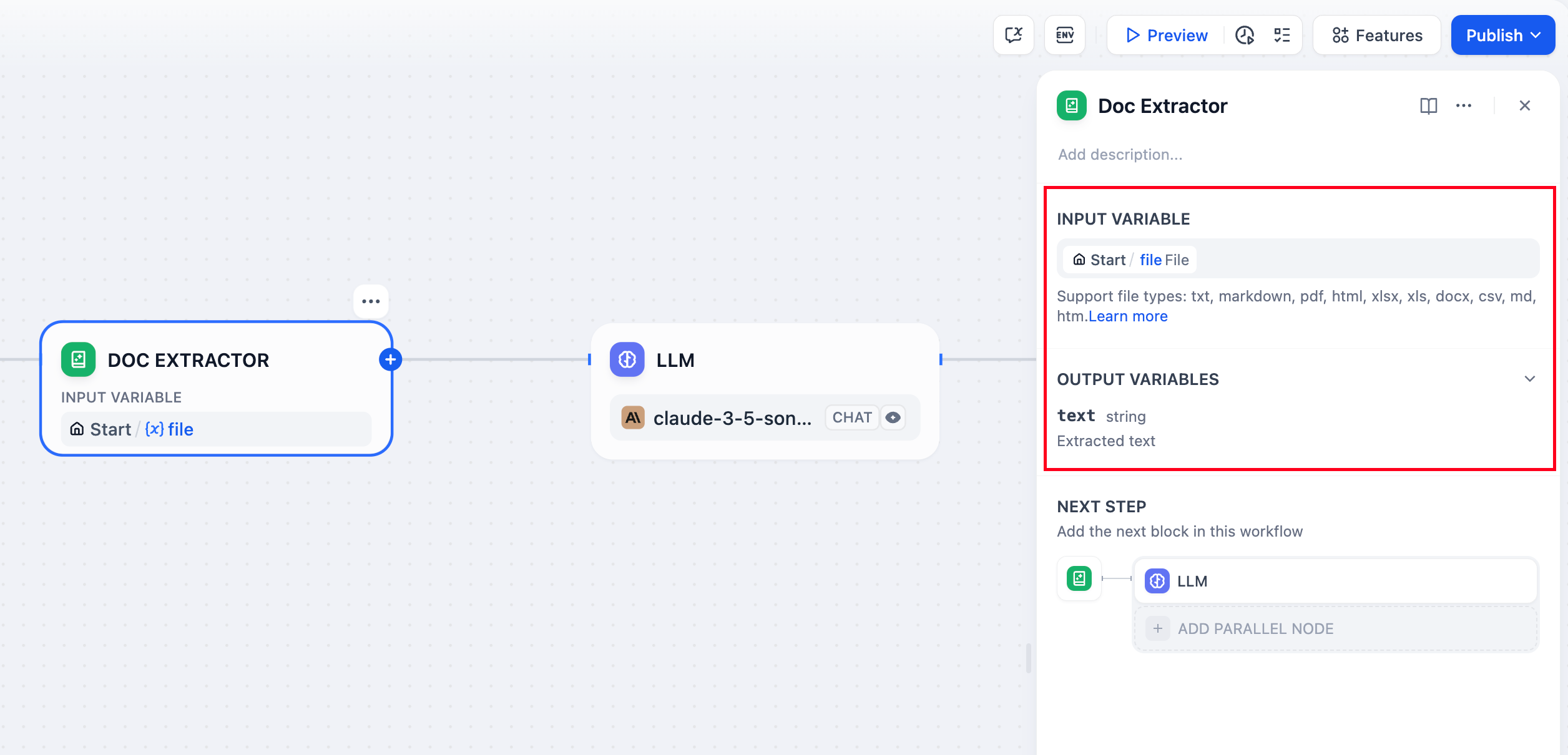
サポートされているファイル形式
このノードは、ほとんどのテキストベースのドキュメント形式を処理できます: テキストドキュメント - 直接テキストコンテンツを含むTXT、Markdown、HTMLファイル Officeドキュメント - Microsoft Wordおよび互換アプリケーションのDOCXファイル PDFドキュメント - pypdfium2を使用した正確なテキスト抽出によるテキストベースのPDF Officeファイル - DOCファイルはUnstructured APIが必要、DOCXファイルはテーブル抽出がMarkdown形式に変換された直接解析をサポート スプレッドシート - Excel(.xls/.xlsx)およびCSVファイルをMarkdownテーブルに変換 プレゼンテーション - PowerPoint(.ppt/.pptx)ファイルをUnstructured API経由で処理 メール形式 - メールコンテンツ抽出のためのEMLおよびMSGファイル 特殊形式 - EPUB書籍、VTT字幕、JSON/YAMLデータ、およびPropertiesファイル 画像、音声、動画などの主にバイナリコンテンツを含むファイルは、特殊な処理ツールや外部サービスが必要です。入力と出力
入力設定
以下のいずれかを受け入れるようにノードを設定します: 単一ファイル入力(通常はStartノードからのファイル変数) 複数ファイルバッチドキュメント処理用の配列として出力構造
ノードは抽出されたテキストコンテンツを出力します:- 単一ファイル入力は抽出されたテキストを含む
stringを生成 - 複数ファイル入力は各ファイルのコンテンツを含む
array[string]を生成
textという名前で、下流処理用の生のテキストコンテンツが含まれています。
実装例
ドキュメントエクストラクターを使用した完全なドキュメントQ&Aワークフローの例です: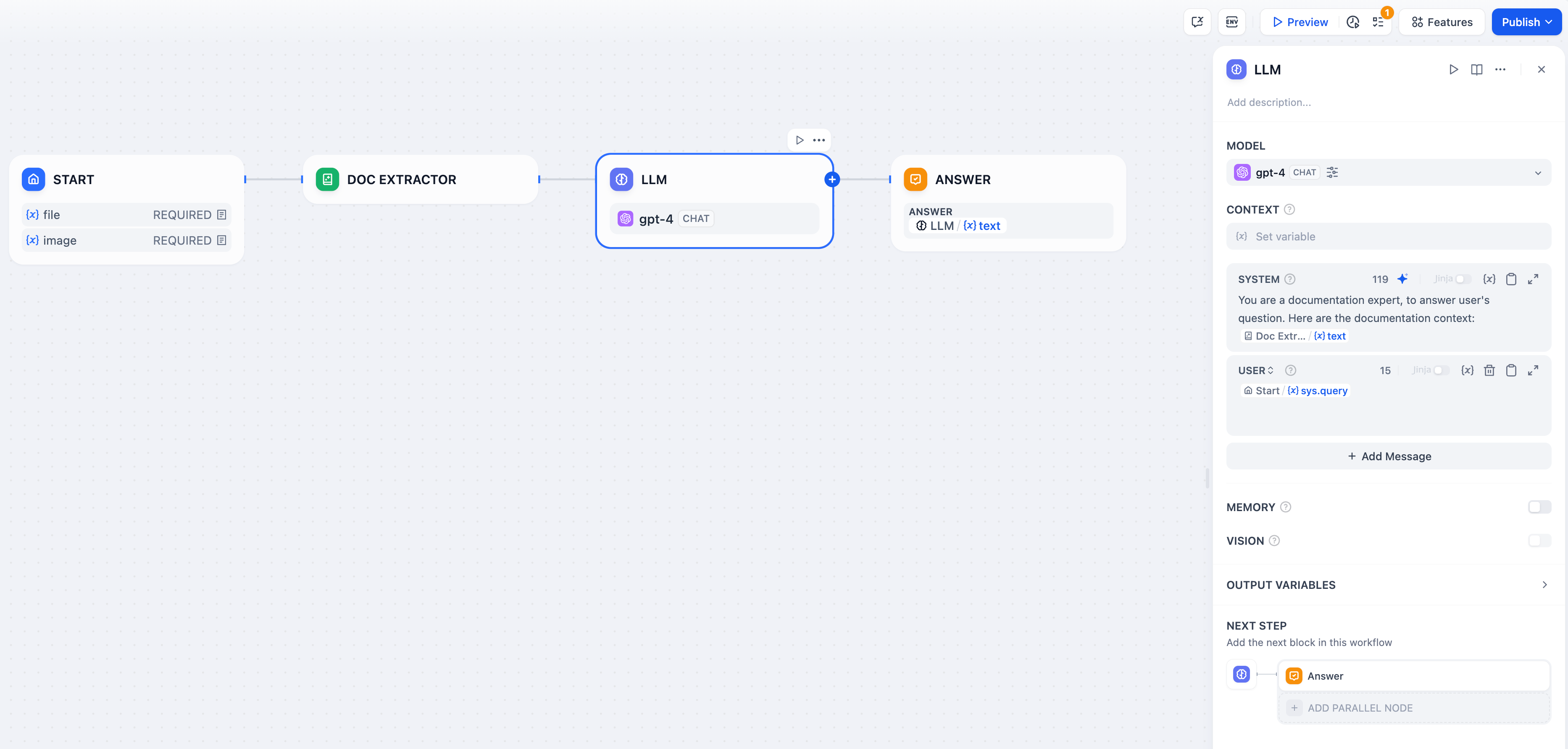
ワークフローセットアップ
ファイルアップロード設定 - ユーザーからのドキュメントアップロードを受け入れるために、Startノードでファイル入力を有効にします。 テキスト抽出 - ドキュメントエクストラクターを接続して、アップロードされたファイルを処理し、テキストコンテンツを抽出します。 AI処理 - 抽出されたテキストを大規模言語モデルのプロンプトで分析、要約、または質問応答に使用します。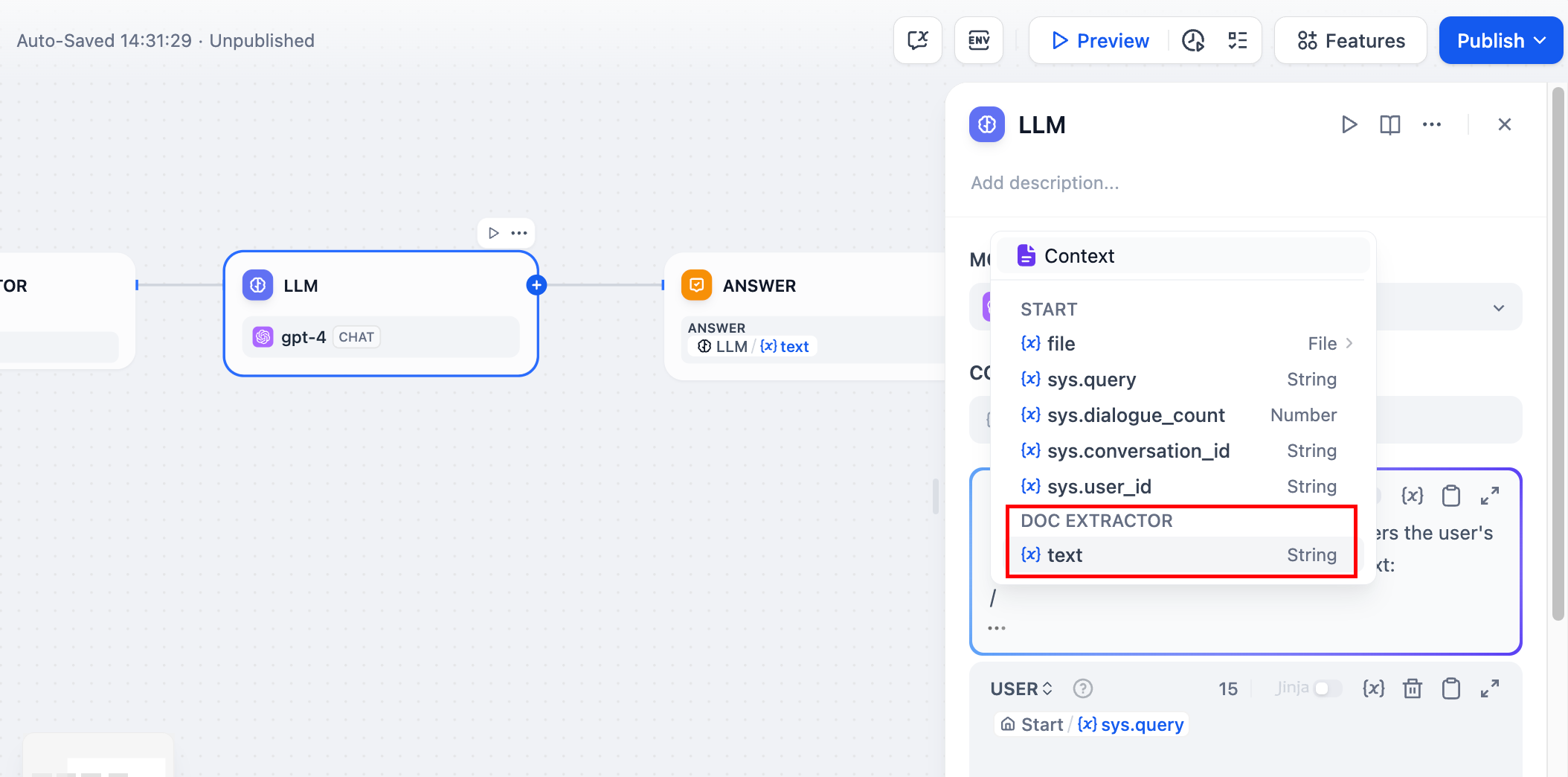
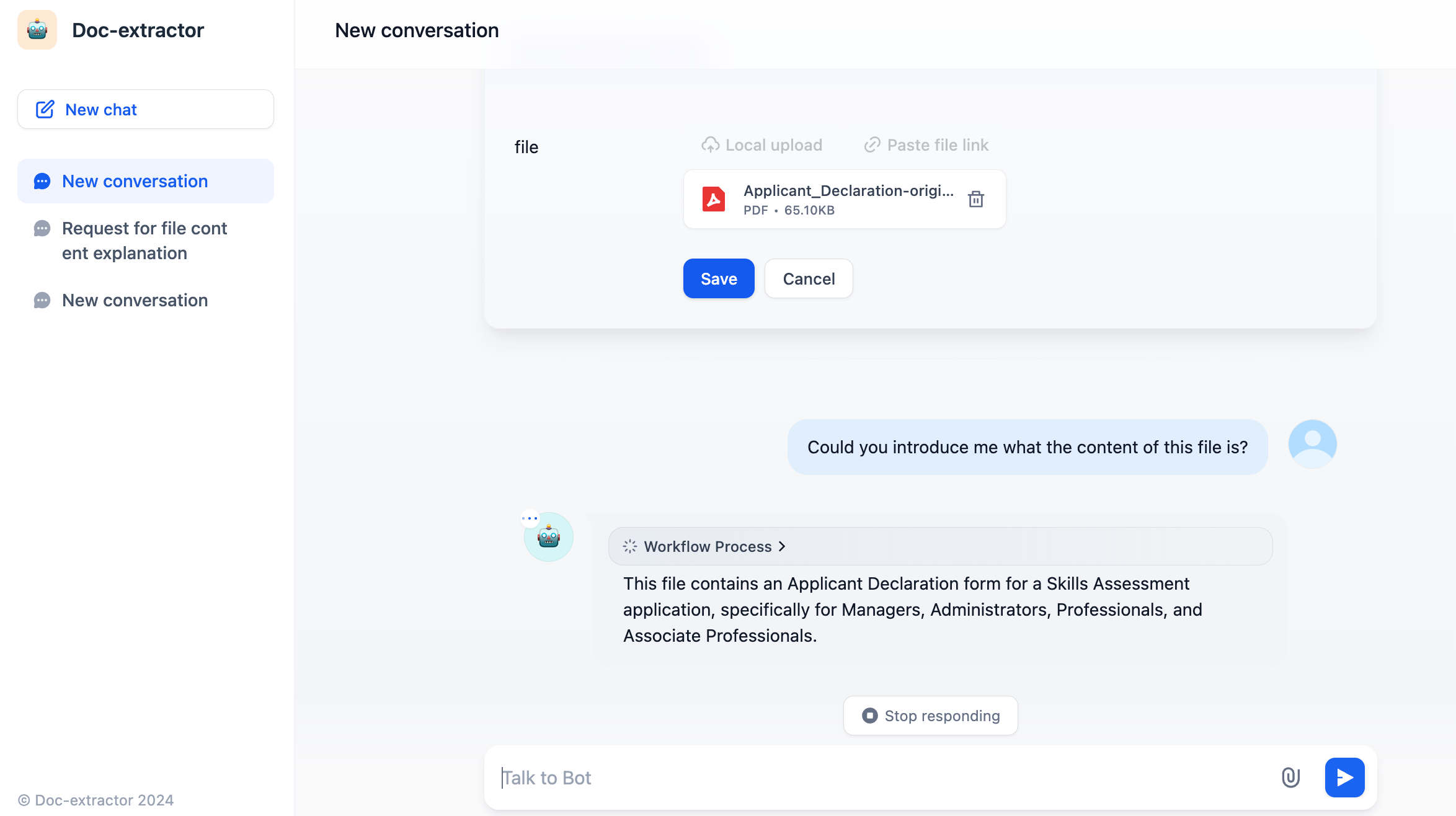
一般的な使用例
ドキュメントQ&Aアプリケーション - ユーザーがドキュメントをアップロードして、そのコンテンツについて質問できるChatPDFスタイルのアプリを構築。 コンテンツ分析 - 契約書、レポート、研究論文を処理して重要な情報と洞察を抽出。 バッチドキュメント処理 - 複数のドキュメントから同時にテキストを抽出して、分析、インデックス化、または移行を実行。 ドキュメント変換 - さまざまなドキュメント形式をプレーンテキストに変換してさらなる処理や保存に使用。処理の考慮事項
ドキュメントエクストラクターは、異なるファイル形式に最適化された特殊な解析ライブラリを使用します。可能な限りテキスト構造と書式を保持し、抽出されたコンテンツを大規模言語モデル処理により有用にします。ファイル形式処理
エンコーディング検出 - chardetライブラリを使用してファイルエンコーディングを自動検出し、テキストベースファイルのUTF-8フォールバック テーブル変換 - ExcelとCSVデータをMarkdownテーブルに変換してより良い大規模言語モデル理解を実現 ドキュメント構造 - DOCXファイルは適切なテーブル-Markdown変換により段落とテーブルの順序を維持 複数行コンテンツ - VTT字幕ファイルは同一話者による連続した発話を結合外部依存関係
一部のファイル形式にはUNSTRUCTURED_API_URLおよびUNSTRUCTURED_API_KEYで設定されたUnstructured APIサービスが必要です:
- DOCファイル(レガシーWordドキュメント)
- PowerPointプレゼンテーション(API処理を使用する場合)
- EPUB書籍(API処理を使用する場合)