

本文档由 AI 自动翻译。如有任何不准确之处,请参考 英文原版。你构建的每个 AI 应用都运行在模型之上。Dify Cloud 提供了热门模型,当你需要更多时,也可连接自己的供应商账户。 模型在整个工作空间内共享,因此团队所有人使用的都是同一批模型。
使用 AI 消息额度调用模型
Dify Cloud 为你提供 AI 消息额度,用于调用一组热门供应商的模型,因此无需自己的 API 密钥即可开始。 从 集成 > 模型供应商(或 Marketplace)安装其中一个供应商,其模型即可使用。每次 AI 回复都会消耗你的 AI 消息额度。 一次 AI 回复即一次模型调用(一次输入和一次输出),无论消耗多少 token,都计为一次回复。一次回复消耗的额度取决于模型,模型越大消耗越多。 哪些供应商受 AI 消息额度支持、以及各模型的额度消耗,详见 Dify 定价页面。在受支持的供应商上使用你自己的账户
当你需要更高的速率限制,或希望通过自己的供应商账户计费时,可在受支持的供应商上添加自己的 API 密钥。- 在 集成 > 模型供应商 中安装该供应商(如尚未安装)。
- 点击其卡片上的 设置,然后填入 API 密钥及其他必要信息。Dify 会先验证密钥,再将该供应商投入使用。
连接 AI 消息额度不支持的供应商
若要使用 AI 消息额度不支持的供应商,需先安装它并通过你自己的账户运行。AI 消息额度不适用于这类供应商。- 在 集成 > 模型供应商 中浏览 安装模型供应商 区域,或打开 Marketplace 查看完整列表。
- 安装该供应商,点击 设置,填入 API 密钥及其他必要信息。
添加自定义模型
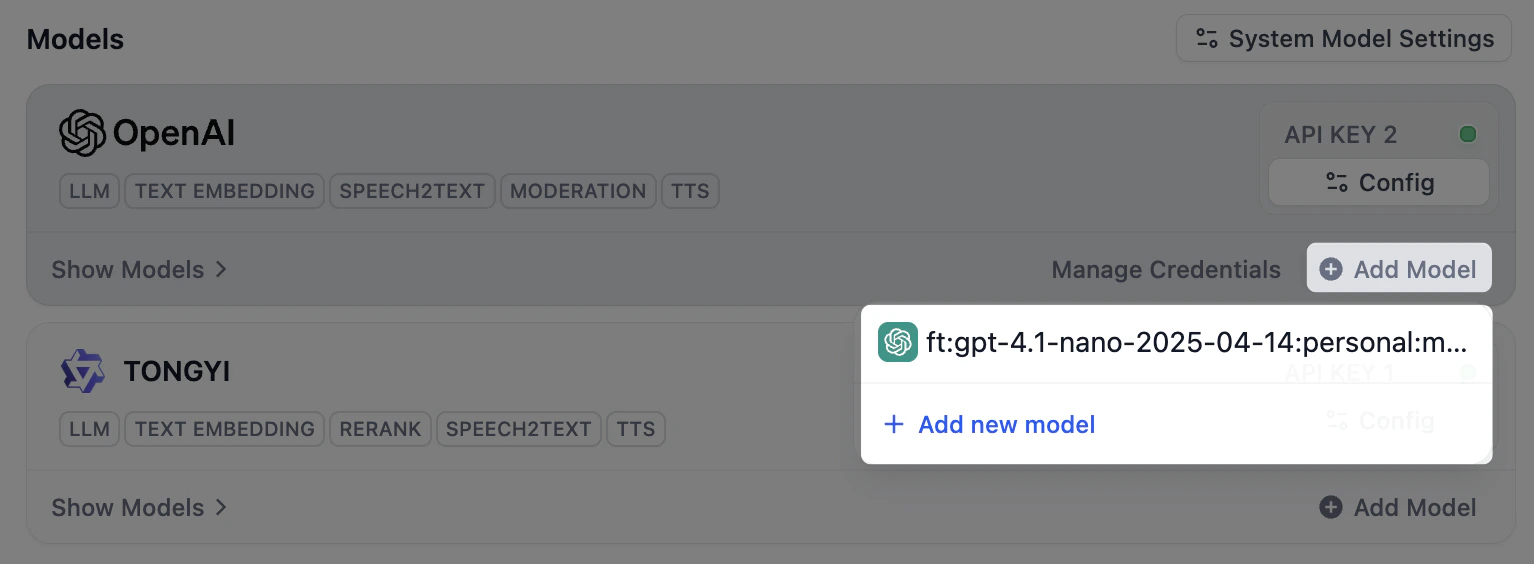
授权某个供应商后,它的模型即可使用,因此只有当你需要的模型不在列表中时,才需手动添加,例如新发布或微调的模型。 点击供应商卡片上的 添加模型,为模型填写名称和凭据。只提供固定一组模型的供应商不会显示此选项。若添加的模型名称和类型与已有模型完全相同,Dify 会将新密钥附加到该模型上,而不会创建重复的模型。
管理密钥
当你想隔离开发与生产环境,或在多个账户间分摊用量时,可为一个供应商添加多个密钥。-
对于供应商自带的模型,点击其卡片上的 配置,管理这些模型共享的密钥。
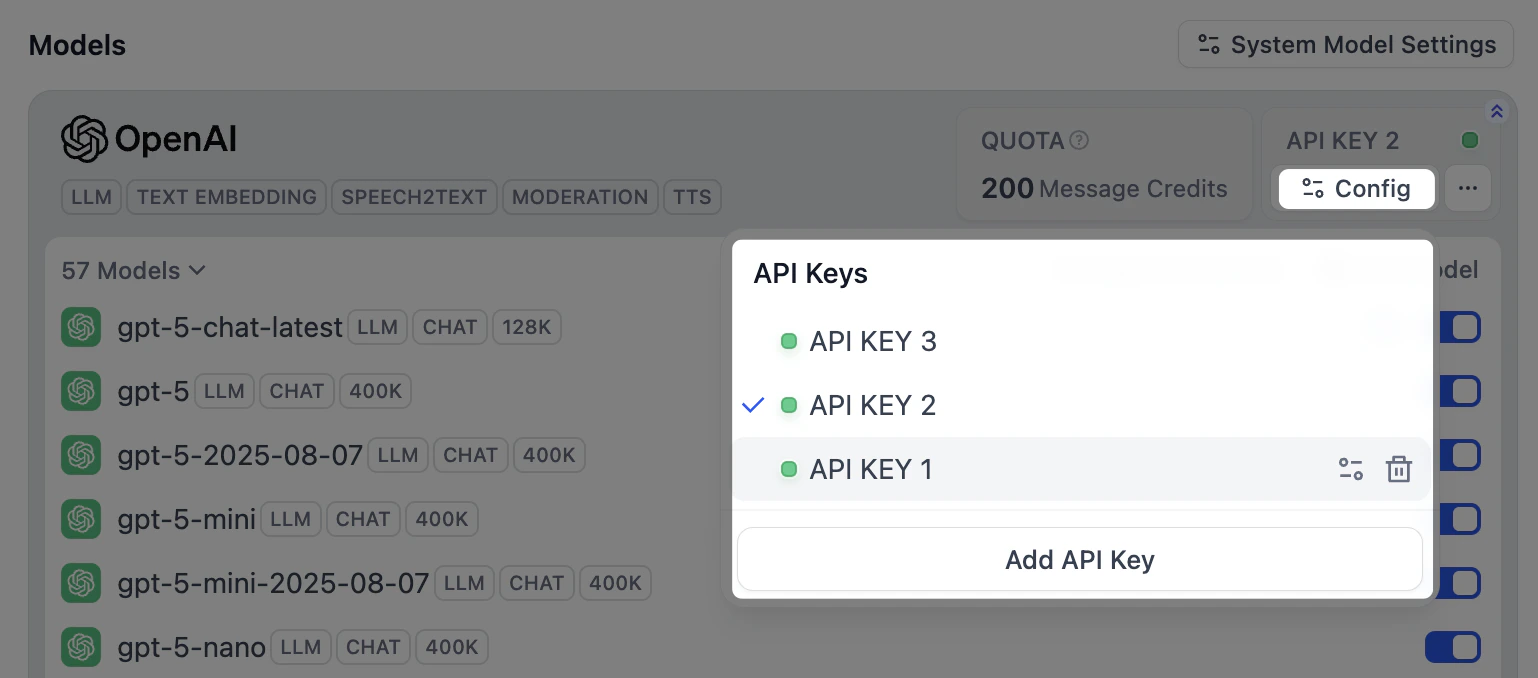
-
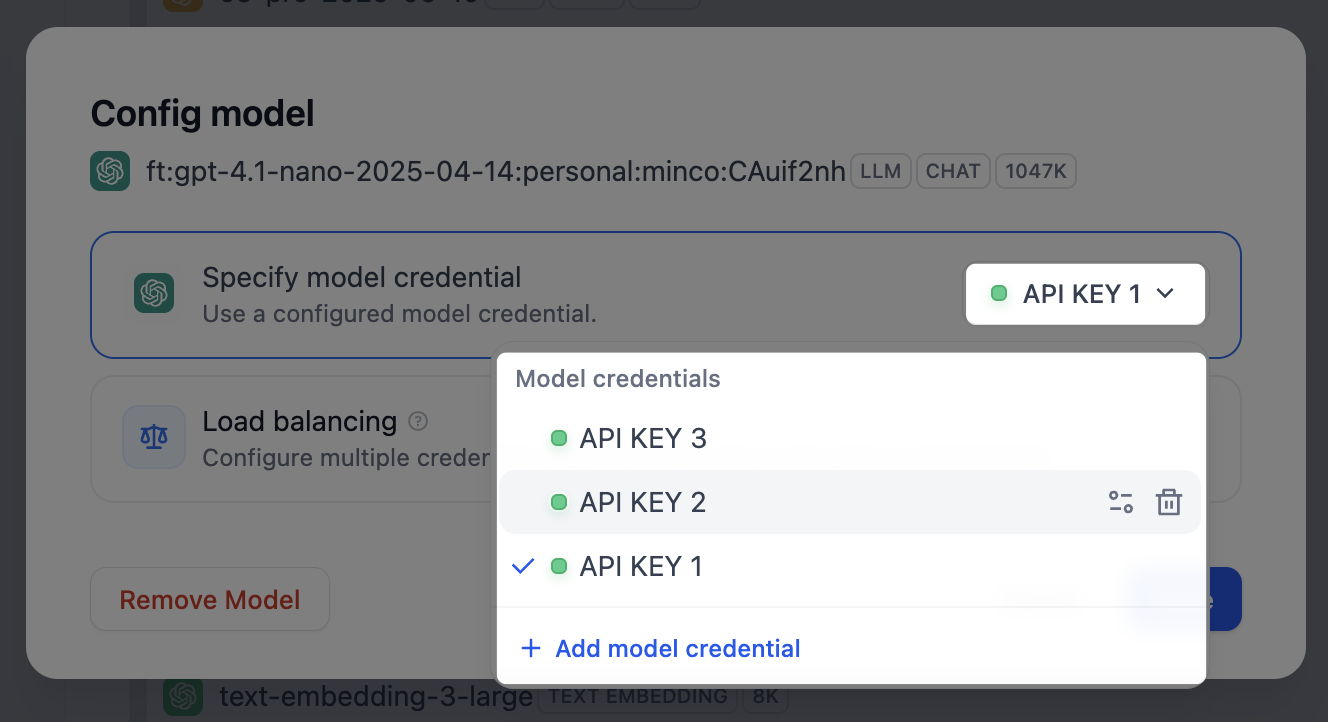
对于你添加的自定义模型,点击该模型的 配置,管理它自己的密钥。
点击供应商卡片上的 管理凭据,可在同一处查看所有自定义模型的密钥。

 即使移除模型后,密钥仍保留在此处,方便你日后重新添加该模型而无需再次录入。
即使移除模型后,密钥仍保留在此处,方便你日后重新添加该模型而无需再次录入。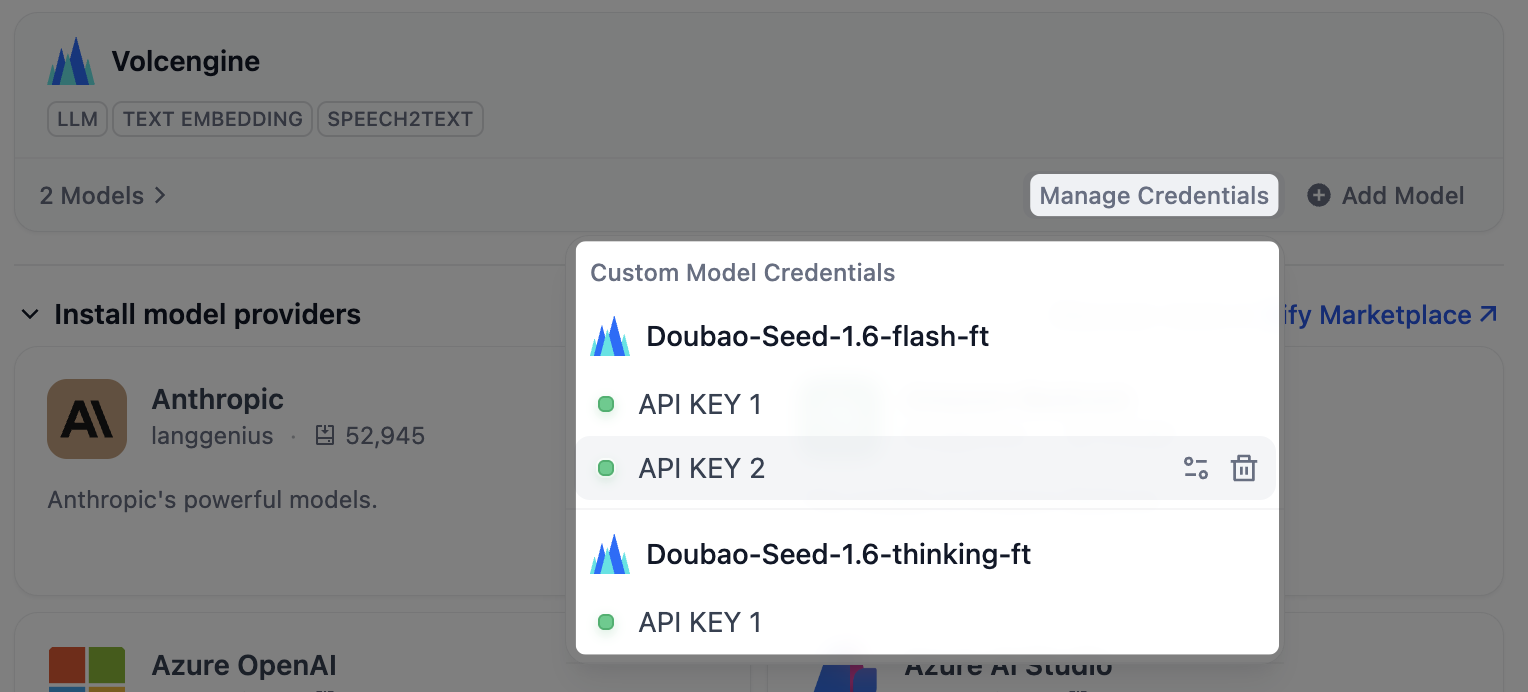
选择应用默认使用的模型
未指定模型的应用和节点会回退到工作空间默认值。点击右上角的 默认模型,为每项任务分别设置:- 系统推理模型:常规 LLM 任务的默认模型。
- Embedding 模型:用于知识库内容的索引和检索。
- Rerank 模型:按相关性对检索结果重新排序。
- 语音转文本模型:将音频转换为文本。
- 文本转语音模型:将文本转换为音频。
通过负载均衡将请求分散到多个密钥 Professional Team
当一个密钥同时处理大量请求时,可能触发供应商的速率限制并开始失败。 使用负载均衡,可将同一模型的请求分散到多个密钥,让任何单个密钥都不会成为瓶颈。Dify 会依次轮询这些密钥,并让触发限制的密钥休息一分钟后再重试。- 在列表中找到目标模型,点击 配置,选择 负载均衡。
-
点击 添加凭据,将密钥加入池中。
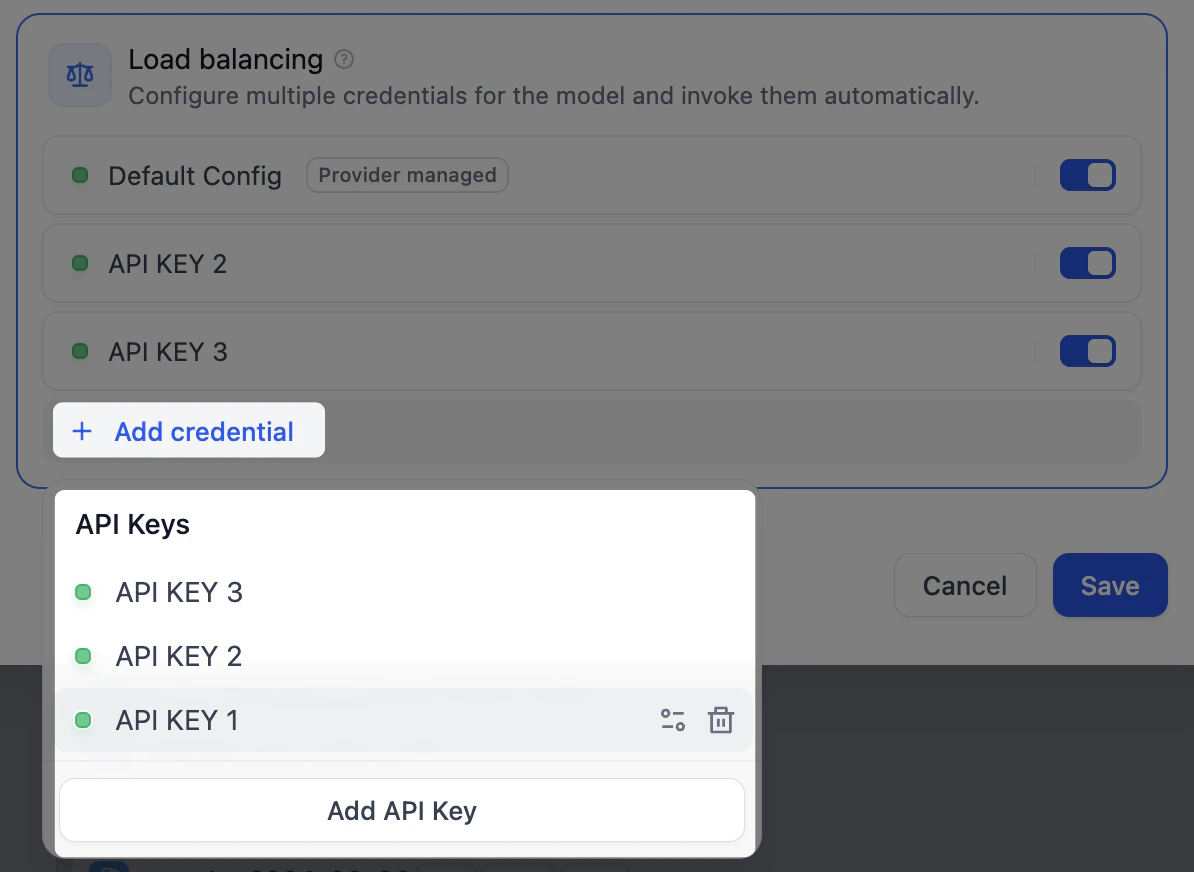
- 启用至少两个密钥,然后点击 保存。使用负载均衡的模型会在列表中显示标识。
你可随时切换回单个密钥,负载均衡的配置会保留以备后用。