

模型接入
接入 LiteLLM 代理的模型
LiteLLM Proxy 是一个代理服务器,支持以下功能:
成功后,代理将在 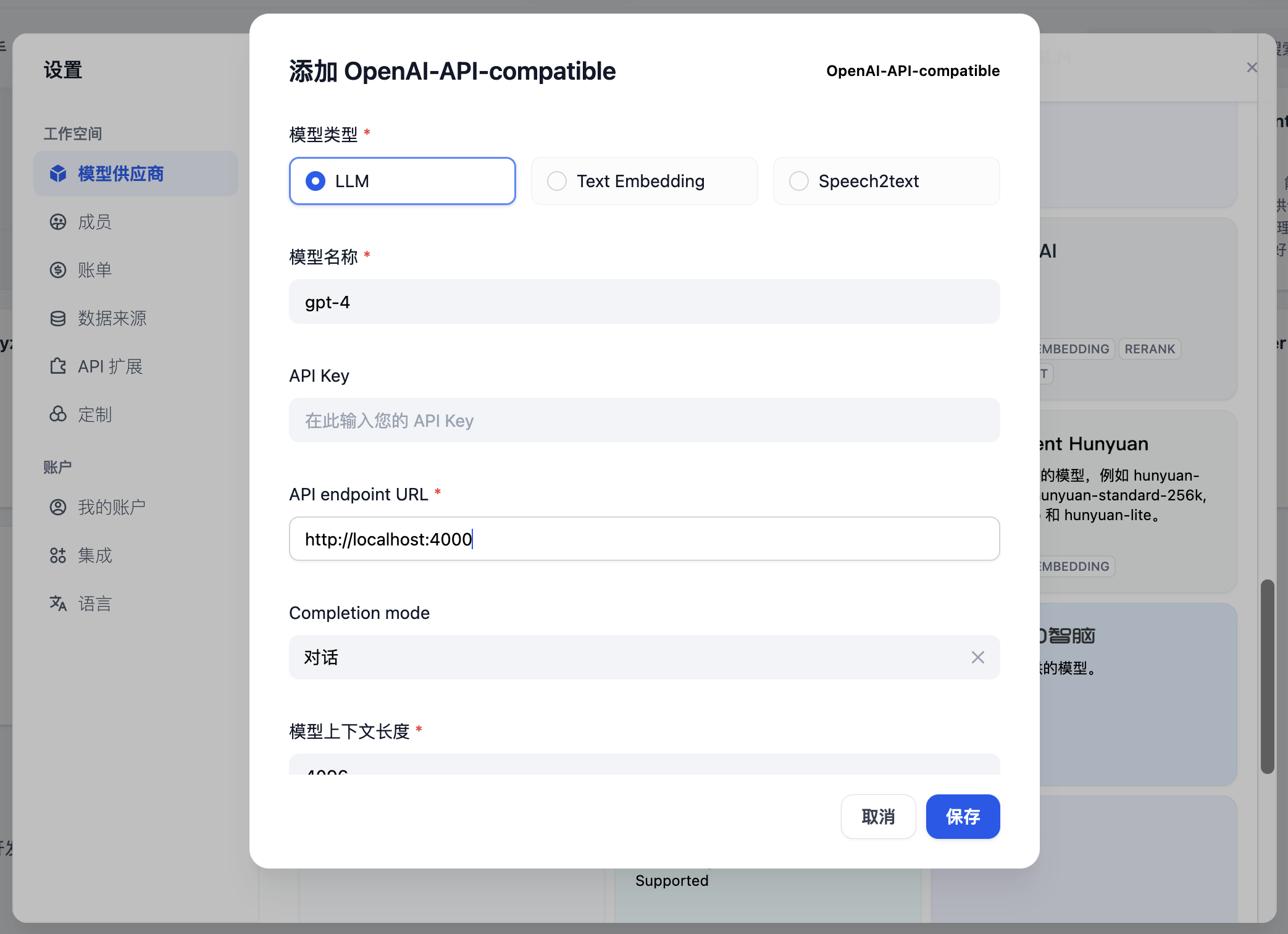
编辑此页面 | 提交问题
- 支持 OpenAI 格式调用 100 多种 LLMs ,包括 OpenAI、Azure、Vertex 和 Bedrock 等。
- 设置 API Key 、预算、速率限制并跟踪使用情况。
快速集成
步骤 1. 启动 LiteLLM Proxy 服务器
LiteLLM 需要一个包含所有定义模型的配置文件,命名为litellm_config.yaml。
如何设置 LiteLLM 配置的详细文档 - 点击这里
步骤 2. 启动 LiteLLM 代理
http://localhost:4000 上运行。
步骤 3. 在 Dify 中集成 LiteLLM Proxy
在设置 > 模型供应商 > OpenAI-API-compatible 中填写:
- 模型名称: gpt-4
- API endpoint URL:
http://localhost:4000- 输入 LiteLLM 服务可访问的基础 URL。
- Completion mode: 对话
- 模型上下文长度: 4096
- 模型的最大上下文长度。如果不确定,使用默认值 4096。
- 最大 Token 上限: 4096
- 模型返回的最大 Token 数量。如果没有特定要求,可以与模型上下文长度一致。
- 支持视觉:
- 如果模型支持图像理解(多模态),如 gpt4-o,请勾选此选项。
保存,在确认无误后即可在应用程序中使用该模型。
嵌入模型的集成方法与 LLM 类似,只需将模型类型更改为文本嵌入。
更多信息
有关 LiteLLM 的更多信息,请参阅:
编辑此页面 | 提交问题