

模型接入
整合通过 GPUStack 部署的本地模型
GPUStack 是一个用于运行 AI 模型的开源 GPU 集群管理器。
Dify 支持与 GPUStack 集成,用于本地部署大语言模型推理、嵌入和重排序能力。
然后你可以按照终端的输出说明访问 GPUStack 界面。
 更多关于 GPUStack 的信息,请参考 GitHub 仓库。
更多关于 GPUStack 的信息,请参考 GitHub 仓库。
编辑此页面 | 提交问题
部署 GPUStack
你可以参考官方文档进行部署,或按照以下步骤快速集成:Linux 或 MacOS
GPUStack 提供了一个脚本,可以将其作为服务安装在基于 systemd 或 launchd 的系统上。要使用此方法安装 GPUStack,只需运行:Windows
以管理员身份运行 PowerShell(避免使用 PowerShell ISE),然后运行以下命令安装 GPUStack:部署模型
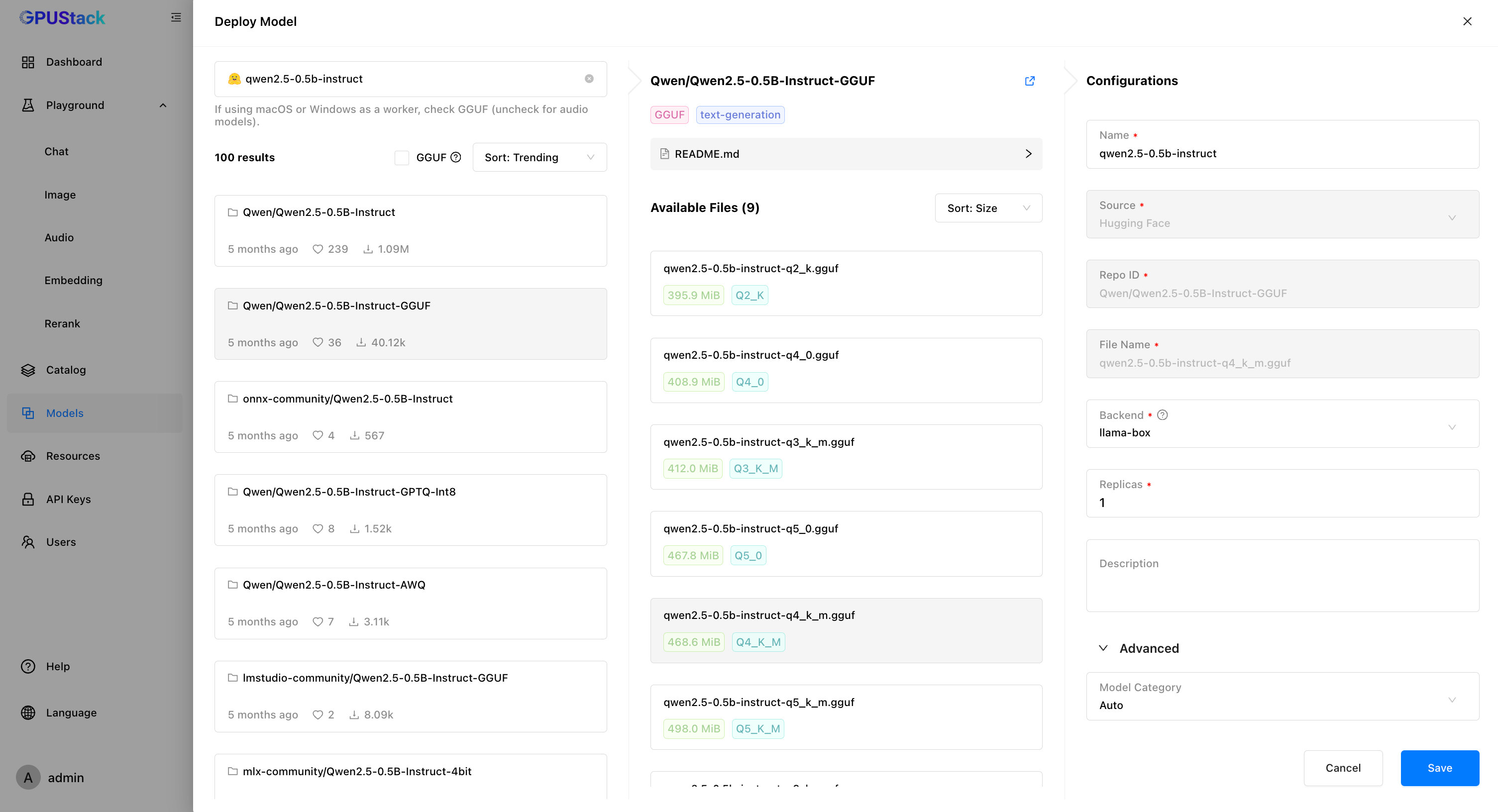
以某个托管在 GPUStack 的大语言模型为例:-
在 GPUStack 界面中,进入”模型”页面并点击”部署模型”,从下拉菜单中选择
Hugging Face。 -
使用左上角的搜索栏搜索模型名称
Qwen/Qwen2.5-0.5B-Instruct-GGUF。 -
点击
保存以部署模型。
创建 API 密钥
- 进入”API 密钥”页面并点击”新建 API 密钥”。
-
填写名称,然后点击
保存。 - 复制 API 密钥并保存以供后续使用。
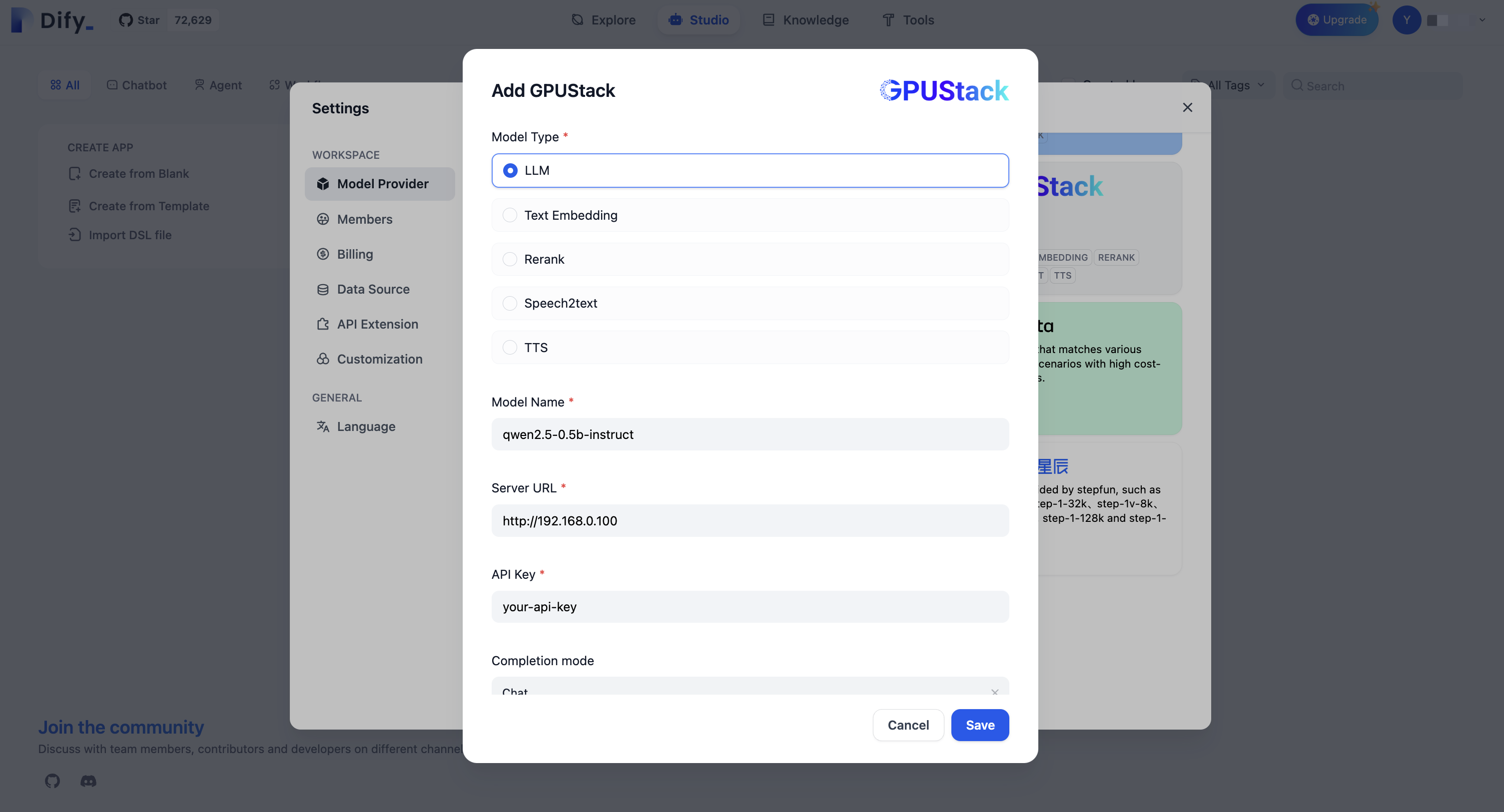
将 GPUStack 集成到 Dify
-
进入
设置 > 模型供应商 > GPUStack并填写:-
模型类型:
LLM -
模型名称:
qwen2.5-0.5b-instruct -
服务器 URL:
http://your-gpustack-server-ip -
API 密钥:
输入你从前面步骤复制的 API 密钥
-
模型类型:
更多关于 GPUStack 的信息,请参考 GitHub 仓库。
编辑此页面 | 提交问题