

⚠️ 本文档由 AI 自动翻译。如有任何不准确之处,请参考 英文原版。
系统供应商 vs 自定义供应商
系统供应商由Dify管理。你无需设置即可立即访问模型,通过Dify订阅计费,并在新模型可用时自动更新。最适合快速入门。 自定义供应商使用你自己的API密钥直接访问模型供应商,如OpenAI、Anthropic或Google。你获得完全控制权、直接计费,通常还有更高的速率限制。最适合生产应用程序。 你可以同时使用两种方式——系统供应商用于原型设计,自定义供应商用于生产。配置自定义供应商
只有工作区管理员和所有者才能配置模型供应商。整个过程在各供应商之间是一致的:支持的供应商
大型语言模型:- OpenAI (GPT-4, GPT-3.5-turbo)
- Anthropic (Claude)
- Google (Gemini)
- Cohere
- 通过Ollama的本地模型
- OpenAI Embeddings
- Cohere Embeddings
- Azure OpenAI
- 本地文本嵌入模型
- 图像生成 (DALL-E, Stable Diffusion)
- 语音 (Whisper, ElevenLabs)
- 内容审核API
供应商配置示例
- OpenAI
- Anthropic
- 本地 (Ollama)
必需:来自OpenAI平台的API密钥可选:用于Azure OpenAI或代理的自定义基础URL,用于组织范围使用的组织ID可用模型:GPT-4、GPT-3.5-turbo、DALL-E、Whisper、文本嵌入
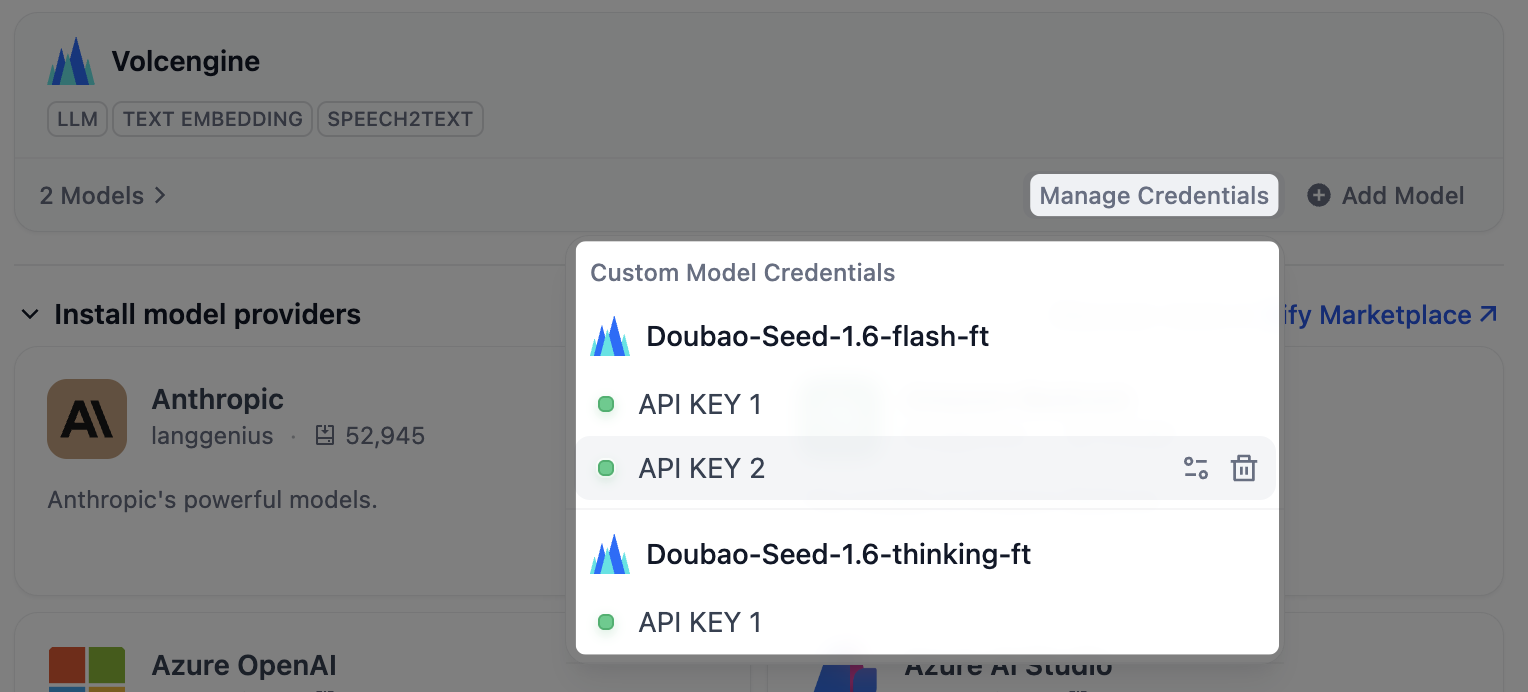
管理模型凭据
为模型供应商的预定义模型和自定义模型添加多个凭据,并轻松进行切换、删除、修改等操作。 在以下场景中,推荐添加多个模型凭据:- 环境隔离:为开发、测试、生产等不同环境配置独立的模型凭据。例如,在开发环境中选择有速率限制的凭据用于功能调试,在生产环境中选择性能稳定、配额充足的付费凭据以保障服务质量。
- 成本优化:通过添加和切换来自不同账户或模型供应商的多个凭据,最大限度地利用免费或低成本额度,降低应用开发与运营成本。
- 模型实验:在模型微调或迭代过程中,可能会产出多个模型版本。通过添加不同模型版本的凭据,快速切换并测试其应用效果。
- 预定义模型
- 自定义模型
安装模型供应商并配置首个凭据后,点击供应商面板右上角的 配置,可进行以下操作: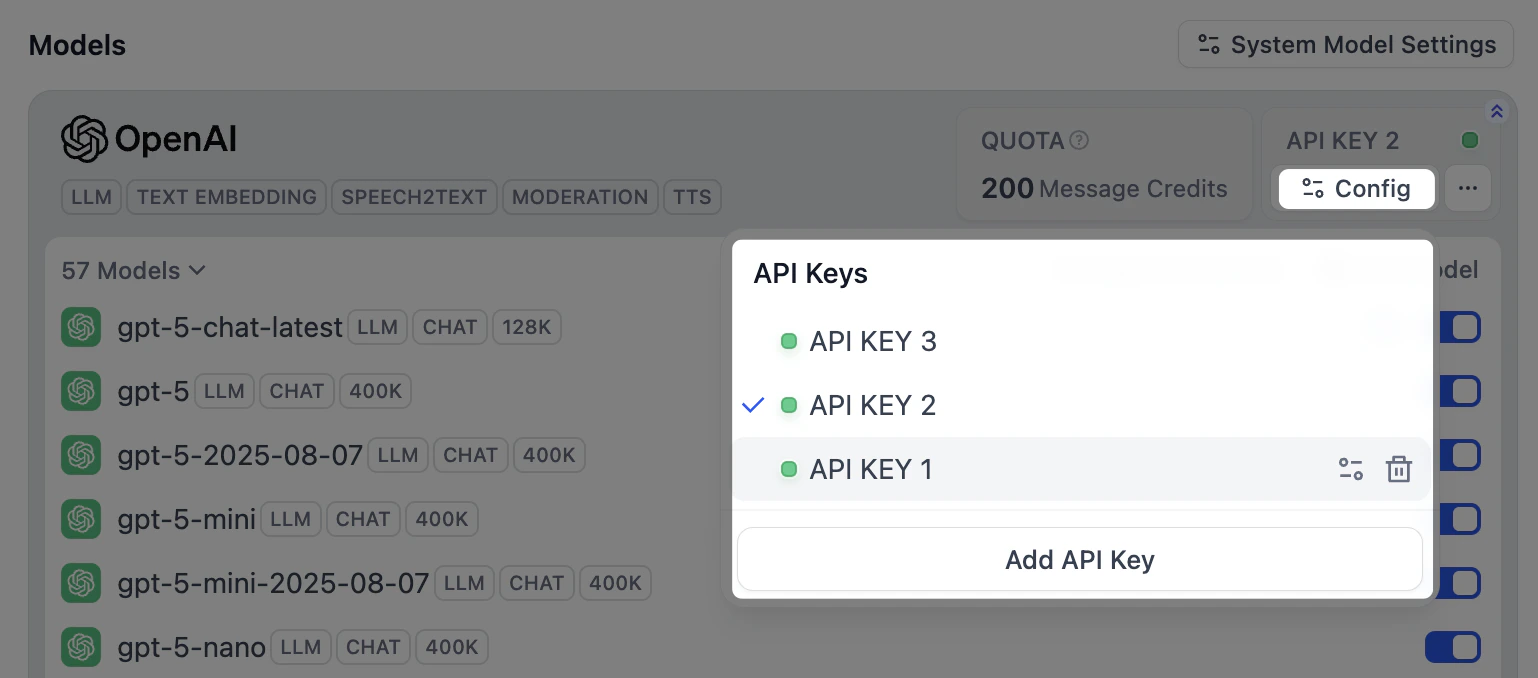
- 添加新凭据
- 选择任一凭据作为所有预定义模型的默认凭据
- 修改凭据
- 删除凭据
若默认凭据被删除,需手动指定新的默认凭据。
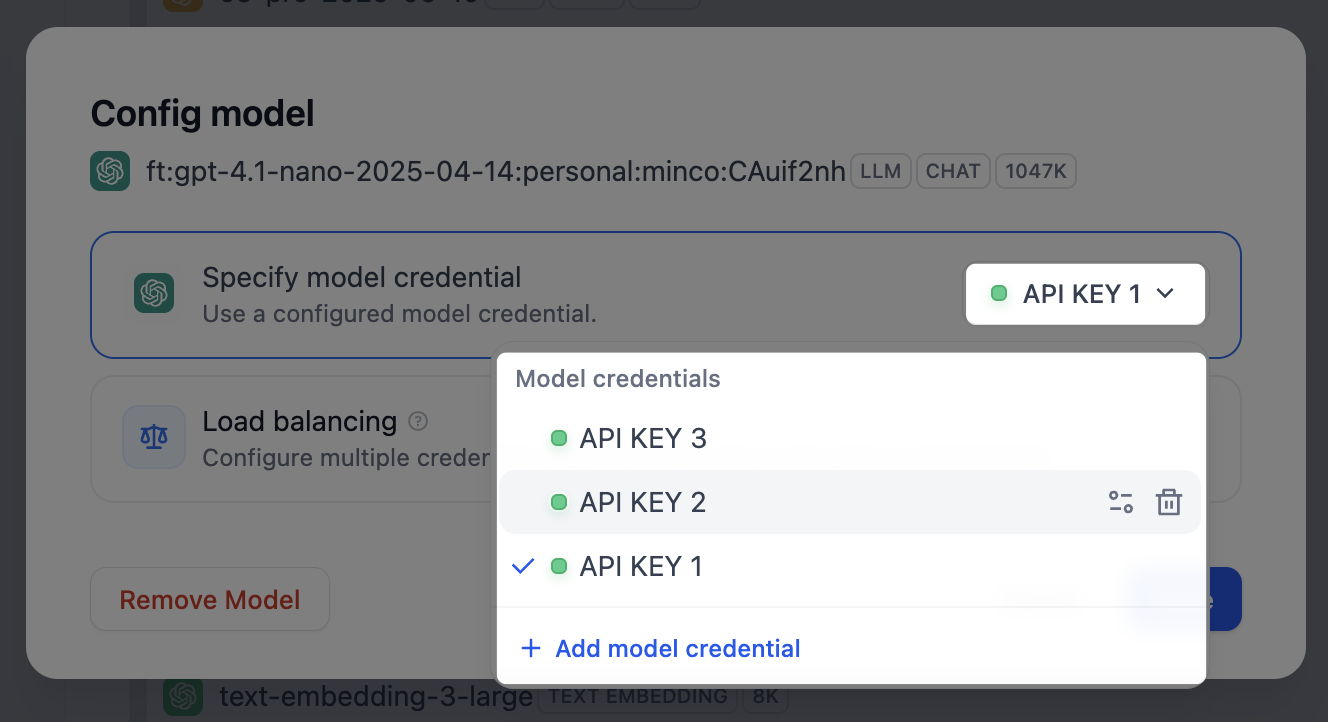
配置模型负载均衡
负载均衡为付费特性,可通过 订阅 SaaS 付费服务或者购买企业版 以启用。
- 在模型列表中找到目标模型,点击对应的 配置,选择 负载均衡 模式。
-
在负载均衡池中,点击 添加凭据,从已有凭据中选择或添加新凭据。
默认配置 为当前指定的默认凭据。
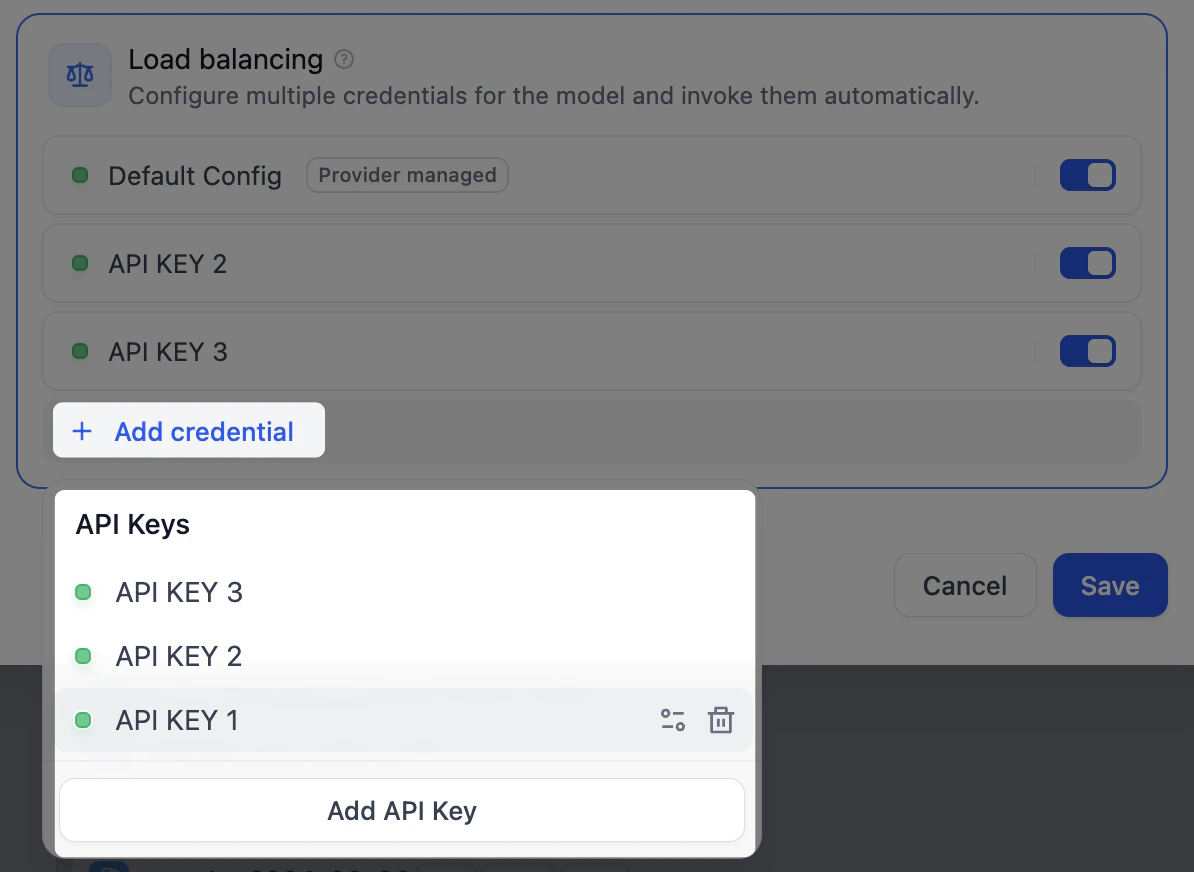
-
在负载均衡池中启用至少 2 个凭据,点击 保存。已启用负载均衡的模型将带有特殊标识。

从负载均衡模式切换回默认的单凭据模式时,系统将保留负载均衡配置以备后用。
访问和计费
系统供应商通过你的Dify订阅计费,使用限制基于你的计划。自定义供应商直接通过供应商(OpenAI、Anthropic等)向你收费,通常提供更高的速率限制。 团队访问遵循工作区权限:- 所有者/管理员可以配置、修改和删除供应商
- 编辑者/成员可以查看可用供应商并在应用程序中使用它们