

⚠️ このドキュメントは AI によって自動翻訳されています。不正確な部分がある場合は、英語版 を参照してください。
検索拡張生成(RAG)とは
この技術の正式名称は RAG(Retrieval-Augmented Generation)です。これは、AI を一般的なレシピを暗記しているシェフから、カウンターに専用のレシピブックを置いているシェフに変えるようなものです。 これは 3 つのシンプルなステップで行われます。 1. 検索(Retrieval)- レシピを探す ユーザーが質問すると、AI はあなたのレシピブック(アップロードしたファイル)をめくって、最も関連性の高いページを探します。 例:誰かがおばあちゃん特製のアップルパイを注文します。あなたはその特定のレシピページを探しに行きます。 2. 拡張(Augmentation)- 材料を準備する AI はその特定のレシピを目の前に置き、記憶に頼る必要がないようにします。 例:レシピをカウンターに広げ、必要なリンゴとシナモンを正確に準備します。 3. 生成(Generation)- 焼き上げる AI は見つけた事実のみに基づいて回答を作成します。 例:レシピ通りに正確にパイを焼き、市販の一般的なものではなく、おばあちゃんの味を再現します。ナレッジ検索ノード
これは、AI アシスタントの隣に参考資料の束を置くようなものです。ユーザーが質問すると、AI はまずこのカンニングペーパーをめくって最も関連性の高いページを探します。そして、見つけた内容とユーザーの元の質問を組み合わせて、最適な回答を考えます。 この実践では、ナレッジ検索ノードを使用して AI アシスタントに公式のカンニングペーパーを提供し、回答が常に事実に基づいたものになるようにします。ハンズオン 1:ナレッジベースを作成する
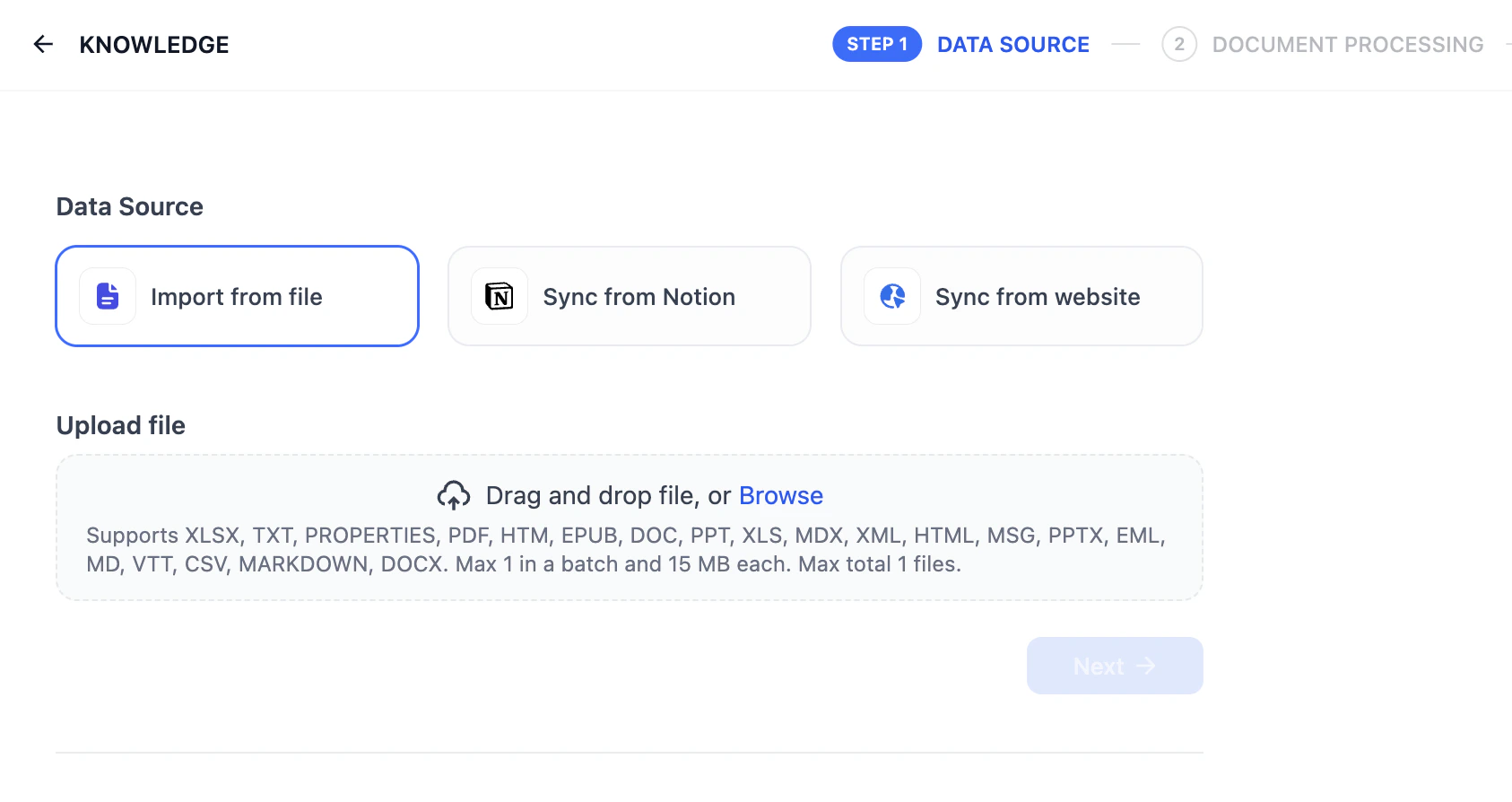
ライブラリに入る
上部ナビゲーションバーのナレッジをクリックし、ナレッジを作成をクリックします。
テキスト分割のステップ
関連性の高いチャンクは、AI アプリケーションが正確で包括的な回答を提供するために不可欠です。長い本を想像してみてください。500 ページの中から 1 つの文を見つけるのは大変です。Dify は本をさまざまなナレッジカードに分割し、正しい答えをより速く見つけられるようにします。チャンク構造ここでは、Dify が長いテキストを自動的に小さく検索しやすいチャンクに分割します。ここでは通用モードのままにしておきましょう。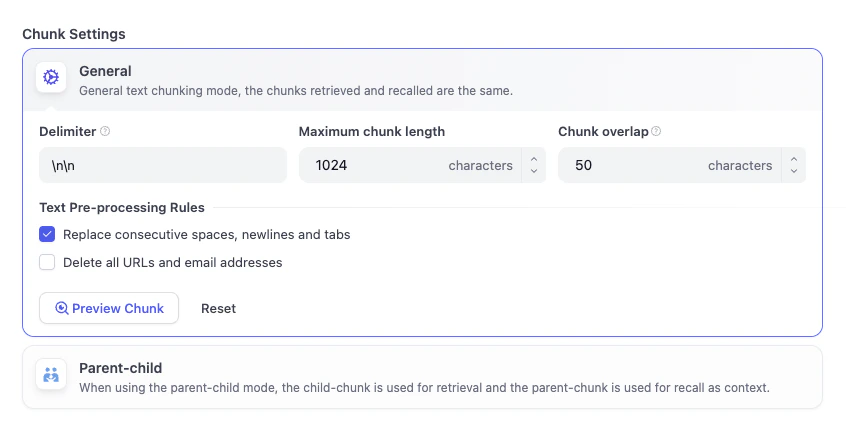

- 高品質:LLM モデルを使用してドキュメントを処理し、より正確な検索を実現して、LLM が高品質な回答を生成できるようにします。
- エコノミー:チャンクごとに 10 個のキーワードを使用して検索を行います。トークンは消費されませんが、検索精度は低下します。
検索設定
ドキュメントの処理が完了したら、検索設定の最終確認を行います。ここでは、Dify が情報を検索する方法を設定できます。エコノミーモードでは、転置インデックスのみが利用可能です。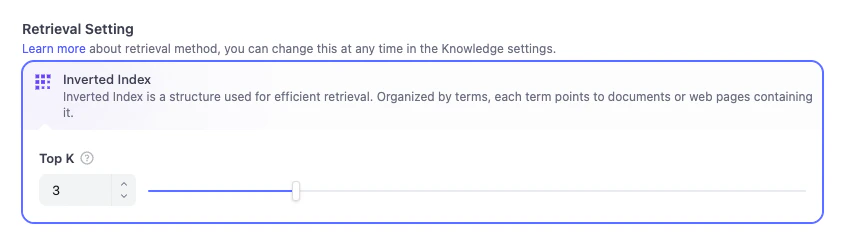
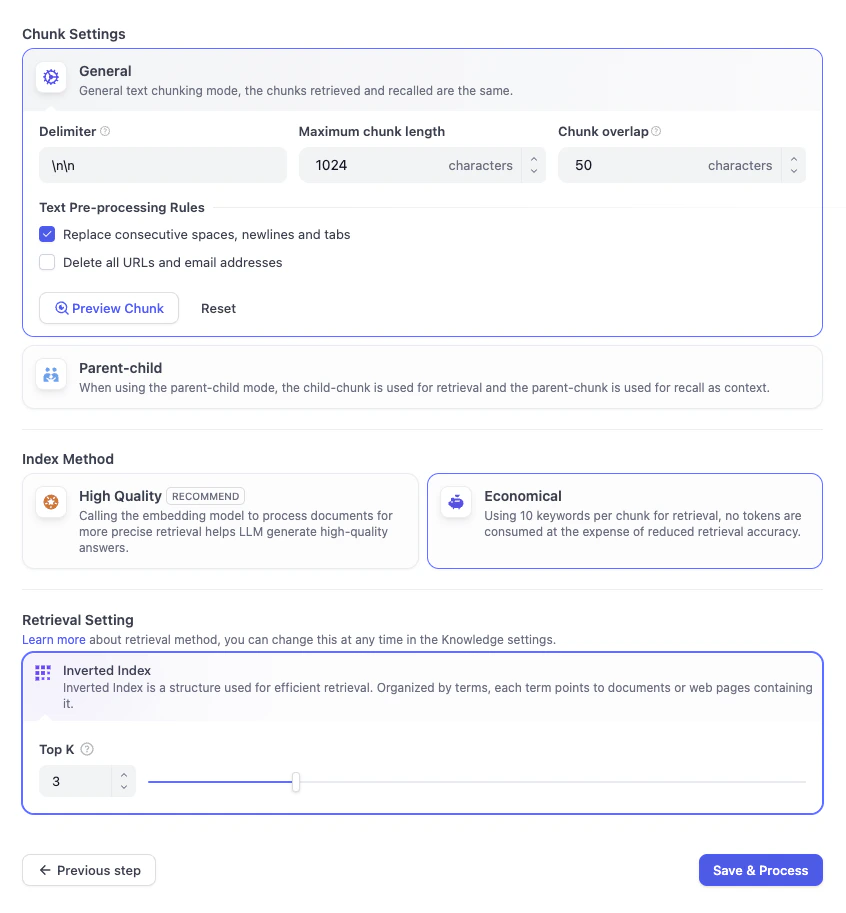
- 転置インデックス これは Dify が使用するデフォルトの構造です。本の巻末にある索引のようなもので、重要な用語が一覧表示され、それらがどのページに出現するかを Dify に正確に伝えます。 これにより、Dify は最初から本全体を読むのではなく、キーワードに基づいて適切なナレッジカードに即座にジャンプできます。
- Top K 3 に設定されたスライダーが表示されます。これは Dify に次のように指示しています:ユーザーが質問したとき、レシピブックから最も関連性の高い上位 3 枚のナレッジカードを見つけて AI に表示せよ。 値を高く設定すると、AI はより多くのコンテキストを読むことができますが、高すぎると情報過多になる可能性があります。
素晴らしい!最初のナレッジベースの作成に成功しました。次に、このナレッジベースを使って AI メールアシスタントをアップグレードしましょう。
ハンズオン 2:ナレッジ検索ノードを追加する
ノードを追加する
- メールアシスタントのワークフローに戻ります。
- 開始ノードと LLM ノードの間の線にカーソルを合わせます。
- **プラス(+)**アイコンをクリックし、ナレッジ検索ノードを選択します。
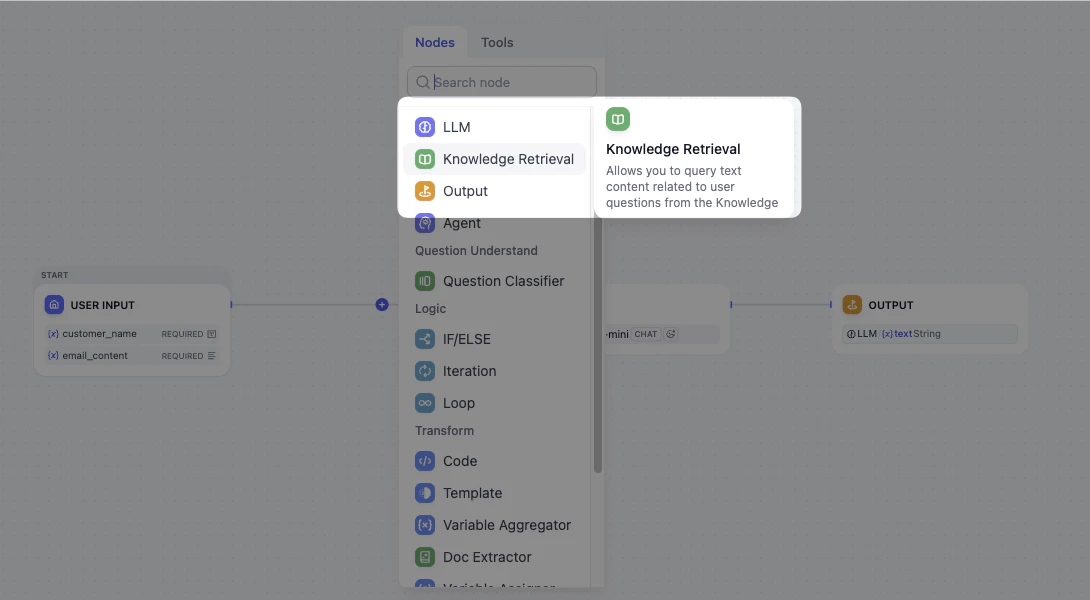
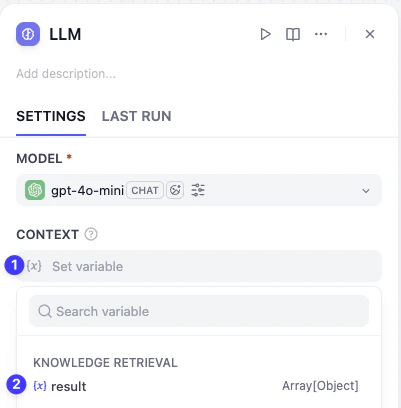
ナレッジベースを接続する
- ノードをクリックし、右側のパネルに移動します。
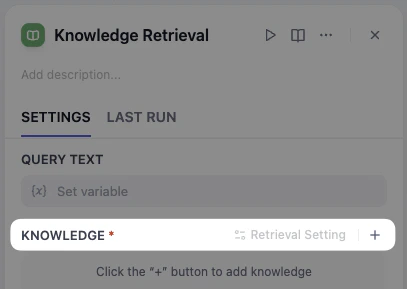
-
ナレッジの横にある**プラス(+)**ボタンをクリックしてナレッジを追加します。
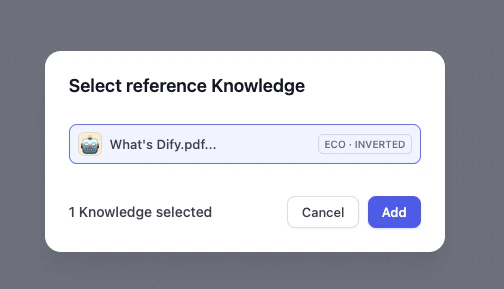
-
What’s Dify を選択し、追加をクリックします。
ハンズオン 3:メールアシスタントをアップグレードする
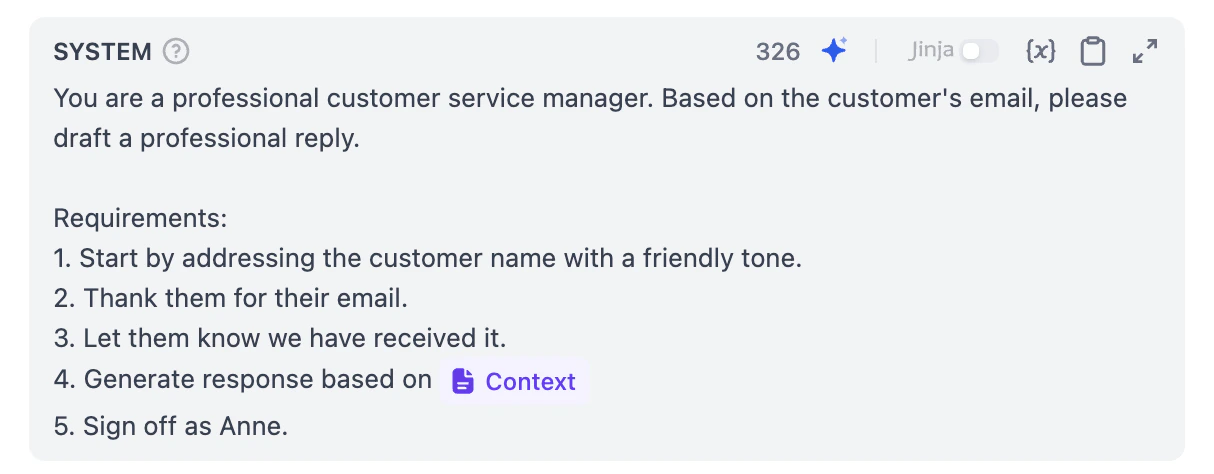
ナレッジベースの準備ができました。次に、LLM ノードに返信を生成する前にナレッジをコンテキストとして実際に読むよう指示する必要があります。
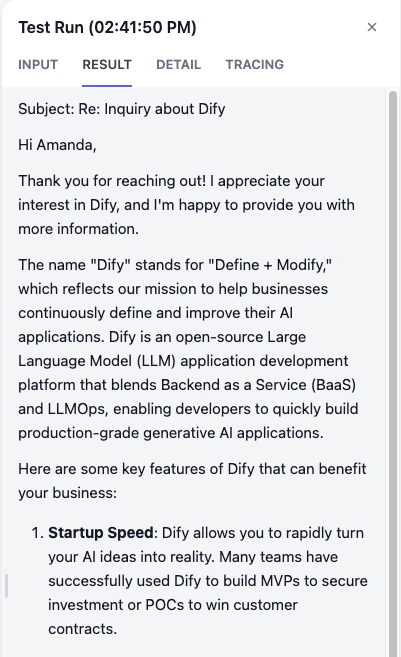
お疲れ様でした! 最も難しい部分を完了しました。これで、メールアシスタントは返信を生成する際に参照できるナレッジベースを持っています。どのように動作するか見てみましょう。
以下のサンプルテキストを使って自由にテストしてみてください。
ミニチャレンジ
- 顧客がナレッジベースにない質問をした場合、どうなりますか?
- ナレッジベースとしてどのような情報をアップロードできますか?
- チャンク構造、インデックス方法、検索設定を探索してみましょう。