

このドキュメントは AI によって自動翻訳されています。不正確な部分がある場合は、英語版 を参照してください。
このクイックスタートは Dify Cloud を使用します。無料で始められ、AI クレジットが含まれ、セットアップ不要の最短ルートです。自分で運用したい場合は、Dify をセルフホストしてから、同じ手順をご自身のインスタンスで実行できます。

始める前に
1
サインアップ
cloud.dify.ai にアクセスして無料でサインアップします。新しいアカウントは Sandbox プランから始まり、OpenAI、Anthropic、Gemini などのプロバイダーのモデルを呼び出すための 200 AI クレジットが含まれています。
Sandbox プランの AI クレジットは 1 回限りの割り当てで、毎月更新されません。
2
モデルプロバイダーの設定
統合 > モデルプロバイダー に移動し、OpenAI モデルプロバイダーをインストールします。このチュートリアルでは
gpt-5.2 を使用します。AI クレジットの対象モデルには API キーは不要で、プロバイダーをインストールすればすぐに使用できます。独自の API キーを設定して使用することもできます。3
デフォルトモデルの設定
- モデルプロバイダー ページの右上隅で、デフォルトモデル をクリックします。
-
システム推論モデル を
gpt-5.2に設定します。これがワークフローのデフォルトモデルになります。
ステップ 1:新しいワークフローの作成
- スタジオ に移動し、空白から作成 > ワークフローを選択します。
-
ワークフローに
マルチプラットフォームコンテンツジェネレーターという名前を付けて、作成 をクリックします。自動的にワークフローキャンバスに移動し、構築を開始します。 - ユーザー入力ノードを選択してワークフローを開始します。
ステップ 2:オーケストレーションと設定
言及されていない設定はデフォルト値のままにしてください。
1. ユーザー入力を収集:ユーザー入力ノード
まず、コンテンツジェネレーターを実行するためにユーザーから収集する情報を定義する必要があります。ドラフトテキスト、ターゲットプラットフォーム、希望のトーン、参考資料などです。ユーザー入力ノードは、これらを簡単に設定できる場所です。ここに追加する各入力フィールドは、すべての下流ノードが参照して使用できる変数になります。
参考資料 - テキスト
参考資料 - テキスト
- フィールドタイプ:
段落 - 変数名:
draft - ラベル名:
ドラフト - 最大長:
2048 - 必須:
はい
参考資料 - ファイル
参考資料 - ファイル
- フィールドタイプ:
ファイルリスト - 変数名:
user_file - ラベル名:
ファイルをアップロード (≤ 10) - サポートファイルタイプ:
ドキュメント、画像 - アップロードファイルタイプ:
両方 - 最大アップロード数:
10 - 必須:
いいえ
ボイスとトーン
ボイスとトーン
- フィールドタイプ:
段落 - 変数名:
voice_and_tone - ラベル名:
ボイス&トーン - 最大長:
2048 - 必須:
いいえ
ターゲットプラットフォーム
ターゲットプラットフォーム
- フィールドタイプ:
短いテキスト - 変数名:
platform - ラベル名:
ターゲットプラットフォーム (≤ 10) - 最大長:
256 - 必須:
はい
言語要件
言語要件
- フィールドタイプ:
選択 - 変数名:
language - ラベル名:
言語 - オプション:
English日本語简体中文
- 必須:
はい
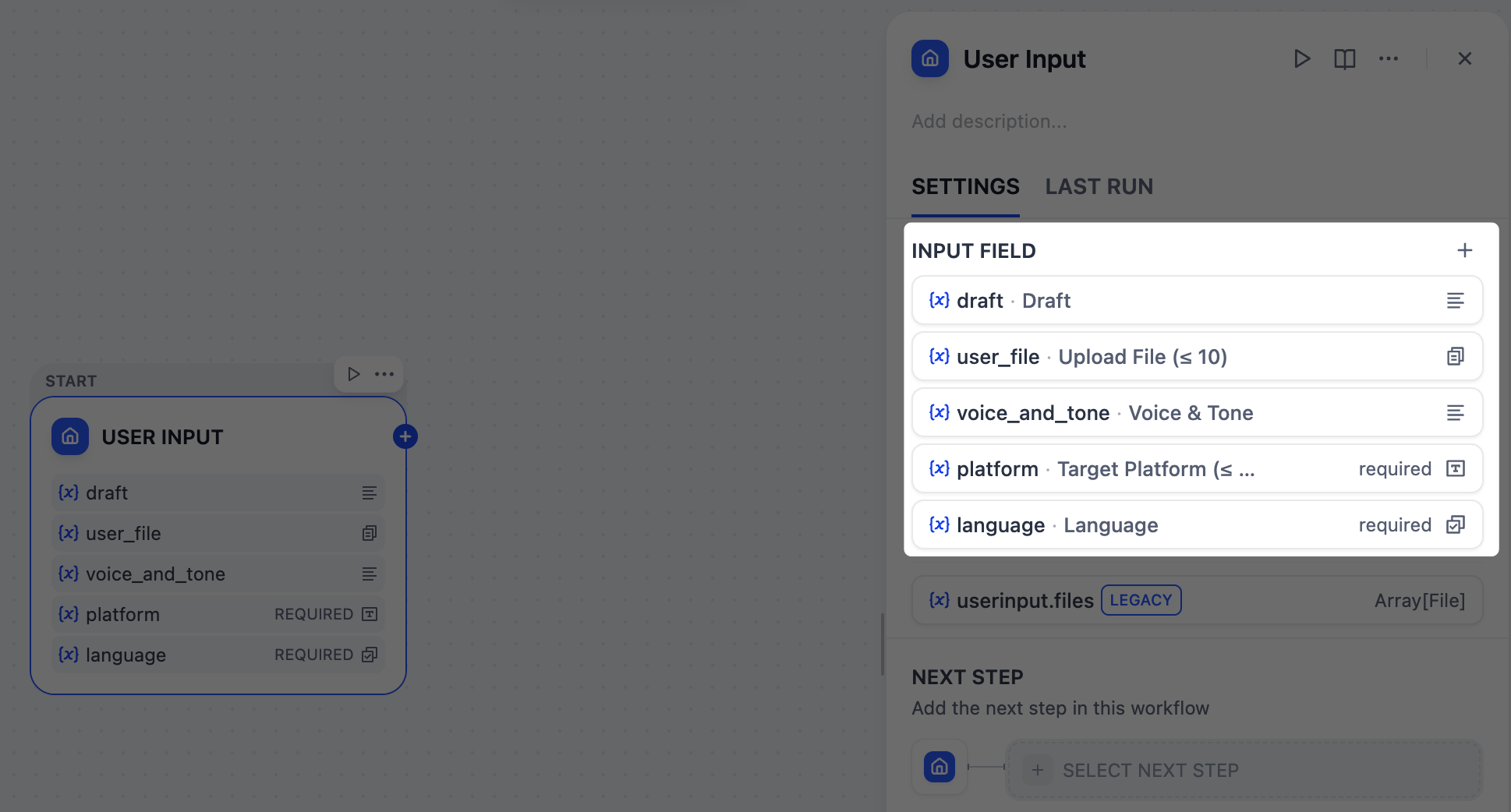
2. ターゲットプラットフォームの識別:パラメータ抽出器ノード
プラットフォームフィールドは自由形式のテキスト入力を受け入れるため、ユーザーは様々な方法で入力する可能性があります:
x and linkedIn、post on Twitter and LinkedIn、さらにはTwitter + LinkedIn pleaseなど。しかし、下流ノードが確実に動作できる["Twitter", "LinkedIn"]のようなクリーンで構造化されたリストが必要です。これはパラメータ抽出器ノードの完璧な仕事です。今回のケースでは、gpt-5.2 モデルを使用してユーザーの自然言語を分析し、これらすべてのバリエーションを認識し、標準化された配列を出力します。-
入力変数 フィールドで、
User Input/platformを選択します。 -
抽出パラメータを追加します:
-
名前:
platform -
タイプ:
Array[String] -
説明:
The platform(s) for which the user wants to create tailored content. -
必須:
はい
-
名前:
-
指示 フィールドに、LLM のパラメータ抽出をガイドする以下を貼り付けます:
INSTRUCTION無効な入力に対して特定のエラーメッセージを出力するよう LLM に指示したことに注意してください。これは次のステップでワークフローの終了トリガーとして機能します。
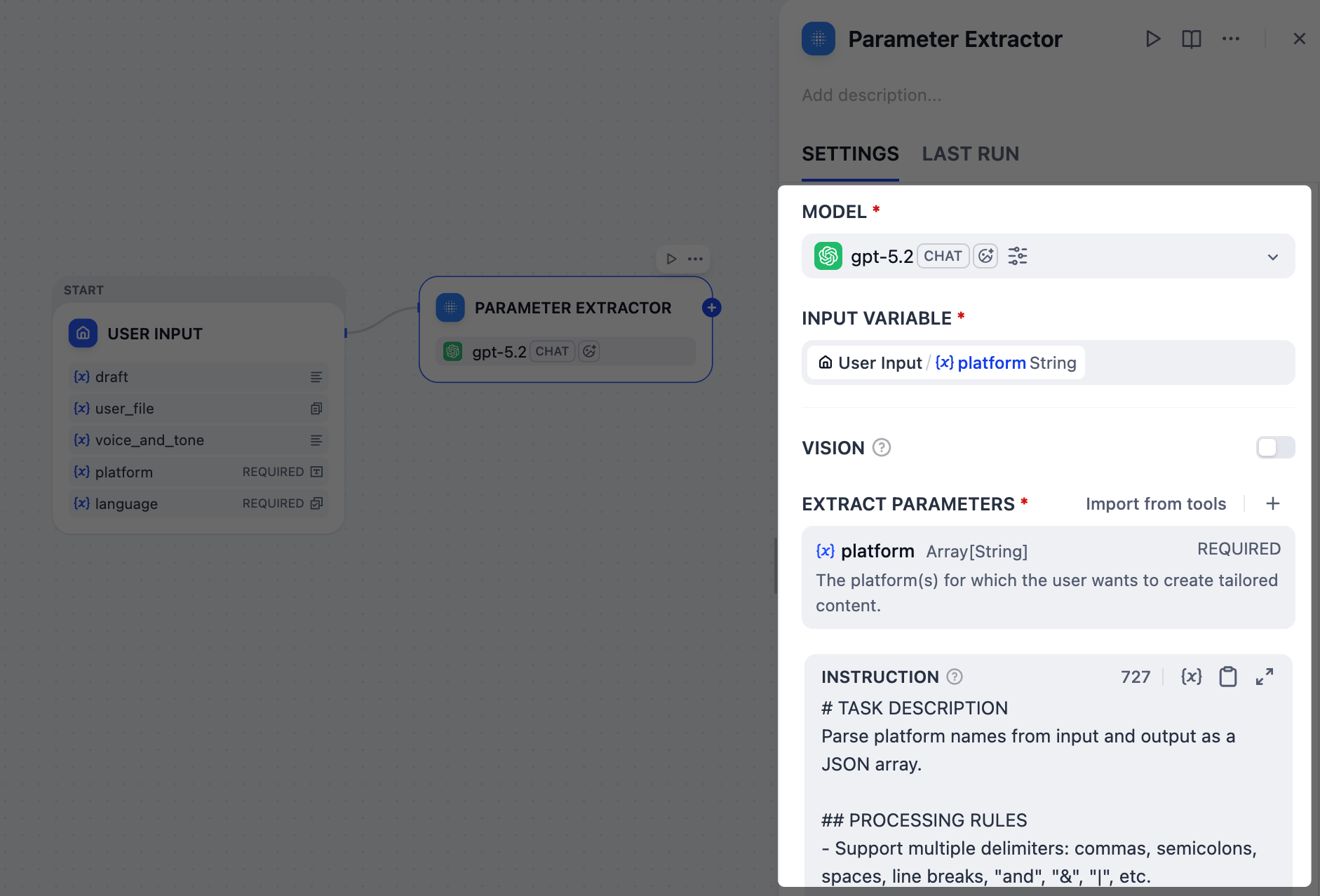
3. プラットフォーム抽出結果の検証:IF/ELSE ノード
ユーザーが
ohhhhhh や BookFace のような無効なプラットフォーム名を入力した場合はどうなるでしょうか?無駄なコンテンツを生成するために時間とトークンを無駄にしたくありません。そのような場合、IF/ELSE ノードを使用してワークフローを早期に停止する分岐を作成できます。パラメータ抽出器ノードからのエラーメッセージをチェックする条件を設定し、そのメッセージが検出された場合、ワークフローは直接出力ノードにルーティングされます。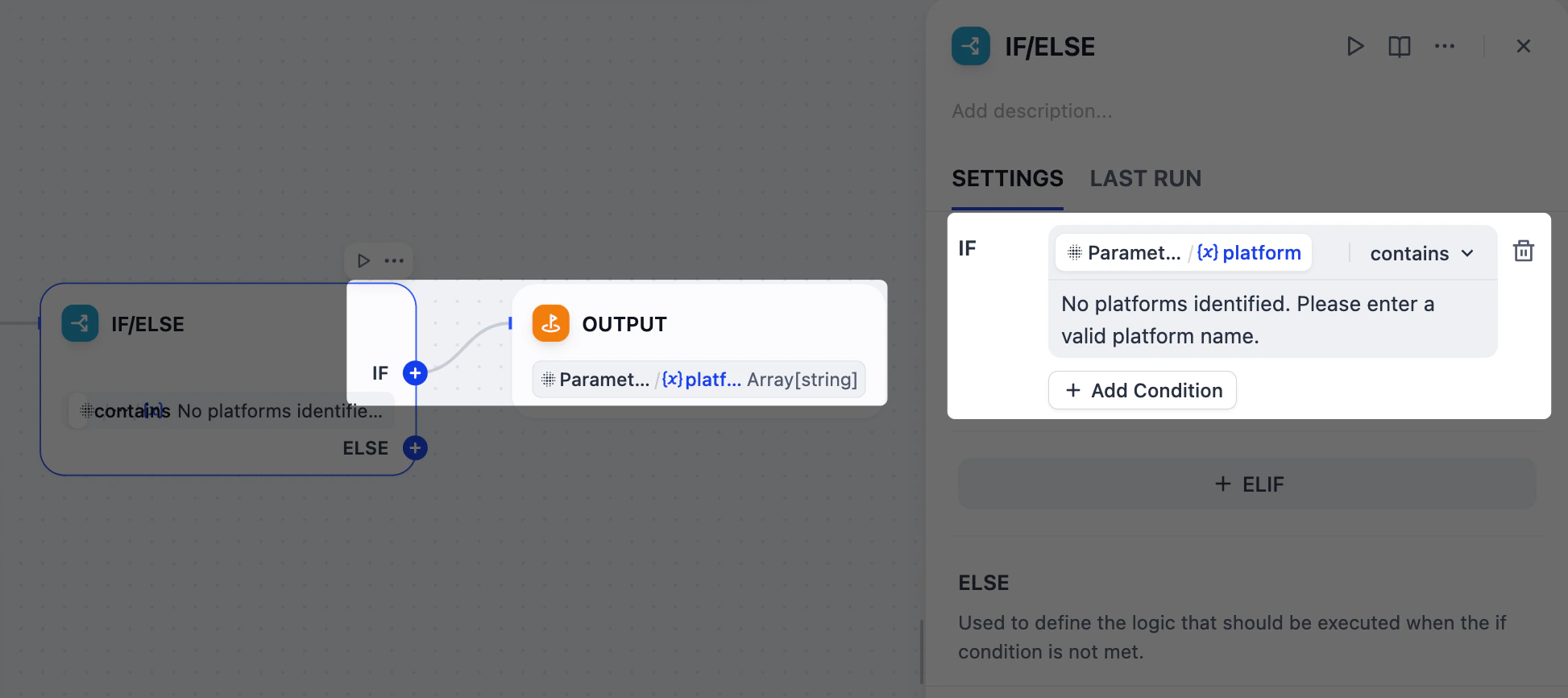
- パラメータ抽出器ノードの後に、IF/ELSE ノードを追加します。
-
IF/ELSEノードのパネルで、IF 条件を定義します:
IF
Parameter Extractor/platform含むNo platforms identified. Please enter a valid platform name. - IF/ELSEノードの後、IFブランチに出力ノードを追加します。
-
出力ノードのパネルで、
Parameter Extractor/platformを出力変数として設定します。
4. アップロードされたファイルをタイプ別に分離:リスト演算子ノード
ユーザーは参考資料として画像とドキュメントの両方をアップロードできますが、
gpt-5.2 ではこの 2 つのタイプは異なる処理が必要です:画像はビジョン機能を通じて直接解釈できますが、ドキュメントはモデルが処理できるようにまずテキストに変換する必要があります。これを管理するために、2 つのリスト演算子ノードを使用して、アップロードされたファイルをフィルタリングし、別々のブランチに分割します(1 つは画像用、1 つはドキュメント用)。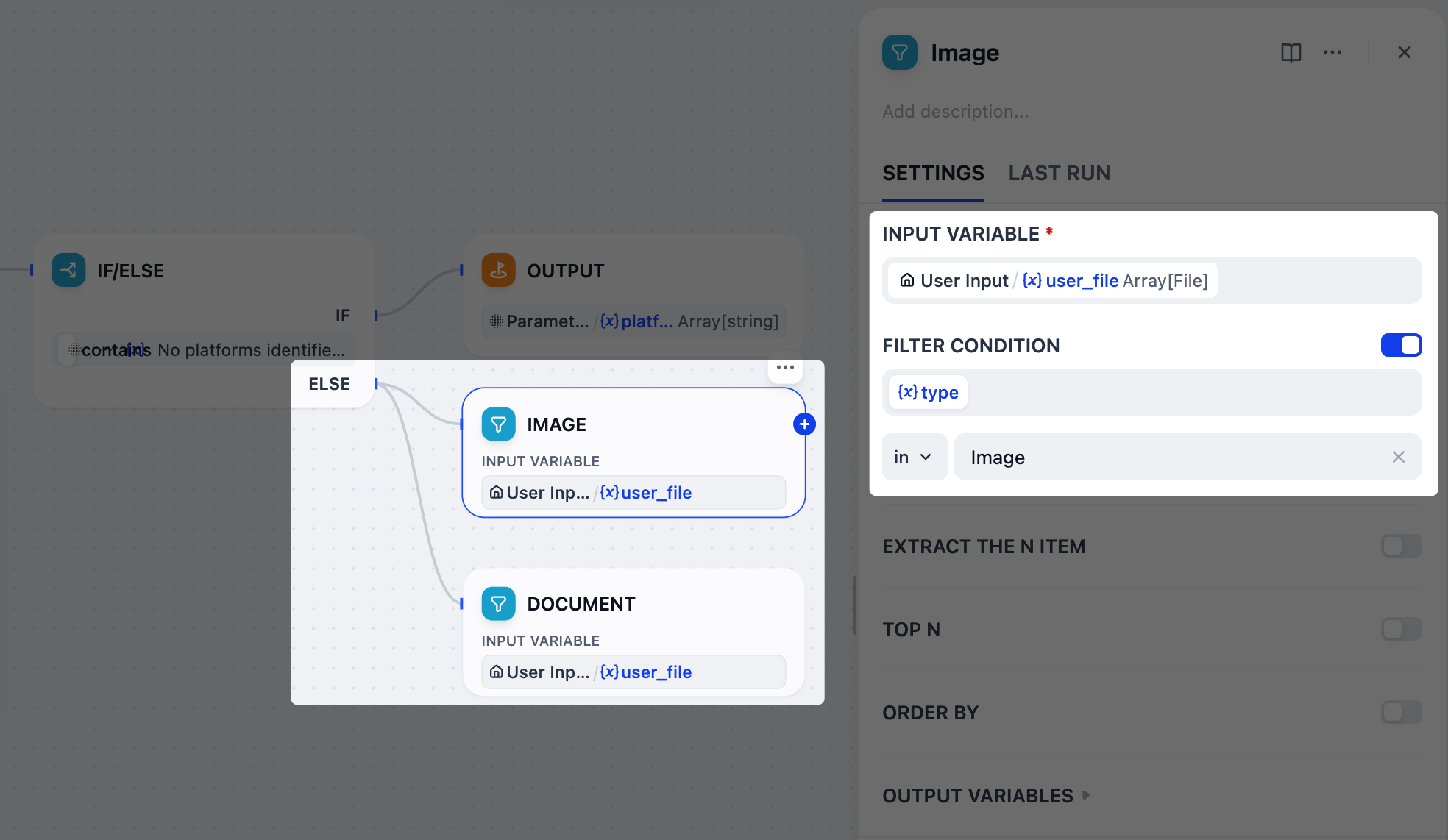
- IF/ELSEノードの後、ELSEブランチに 2 つ の並列リスト演算子ノードを追加します。
-
1 つのノードを
画像、もう 1 つをドキュメントに名前を変更します。 -
画像ノードを設定します:
-
User Input/user_fileを入力変数として設定します。 -
フィルタ条件 を有効にします:
{x}typeにImage。
-
-
ドキュメントノードを設定します:
-
User Input/user_fileを入力変数として設定します。 -
フィルタ条件 を有効にします:
{x}typeにDoc。
-
5. ドキュメントからテキストを抽出:テキスト抽出ノード
gpt-5.2 は PDF や DOCX などのアップロードされたドキュメントを直接読むことはできないため、まずプレーンテキストに変換する必要があります。これがまさにテキスト抽出ノードが行うことです。ドキュメントファイルを入力として受け取り、次のステップのためにクリーンで使用可能なテキストを出力します。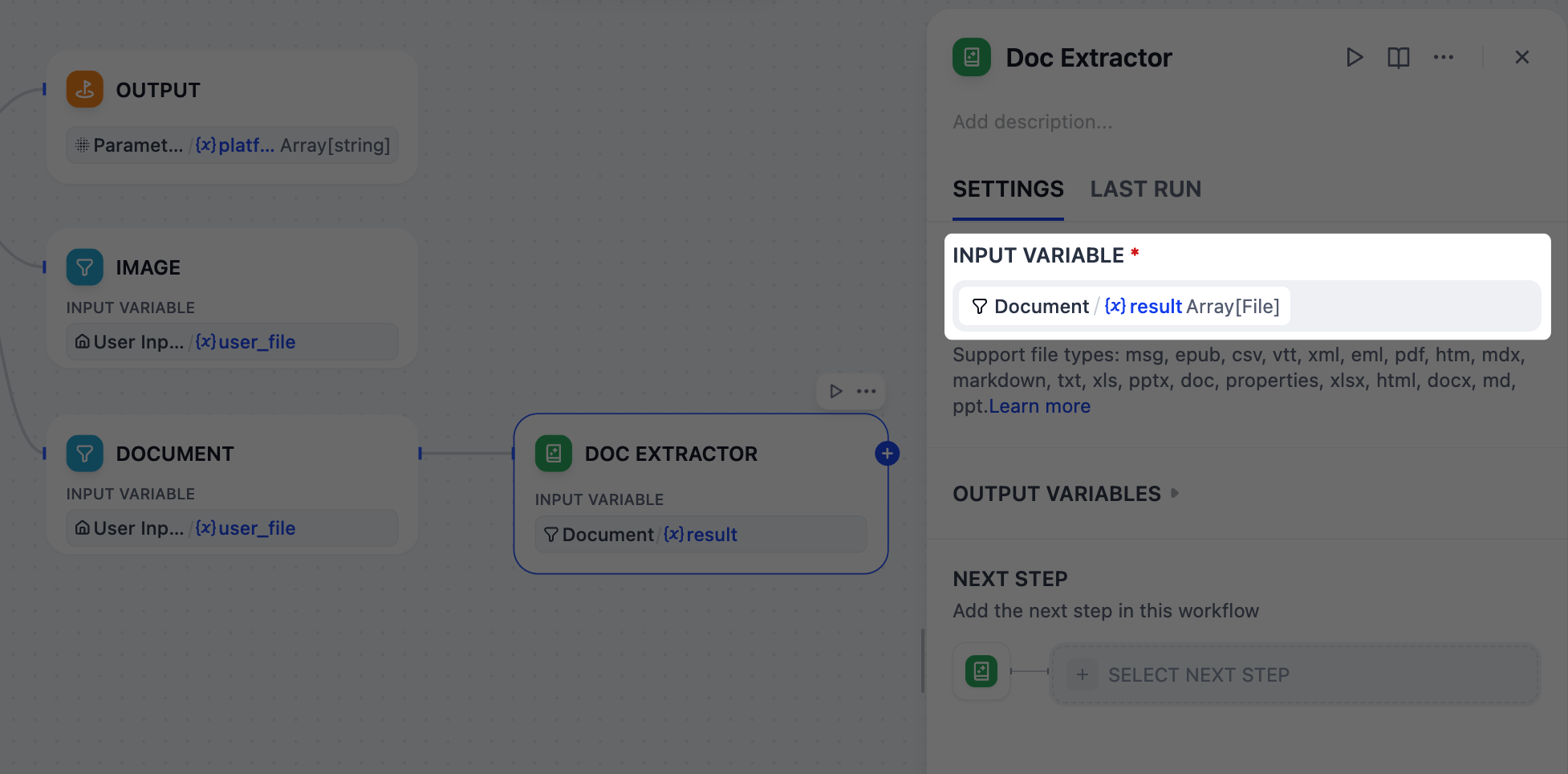
- ドキュメントノードの後に、テキスト抽出ノードを追加します。
-
テキスト抽出ノードのパネルで、
Document/resultを入力変数として設定します。
6. すべての参考資料を統合:LLM ノード
ユーザーが複数の参考タイプ(ドラフトテキスト、ドキュメント、画像)を同時に提供する場合、それらを一つのまとまった要約に統合する必要があります。LLM ノードは、すべての散在する部分を分析してこのタスクを処理し、後続のコンテンツ生成をガイドする包括的なコンテキストを作成します。
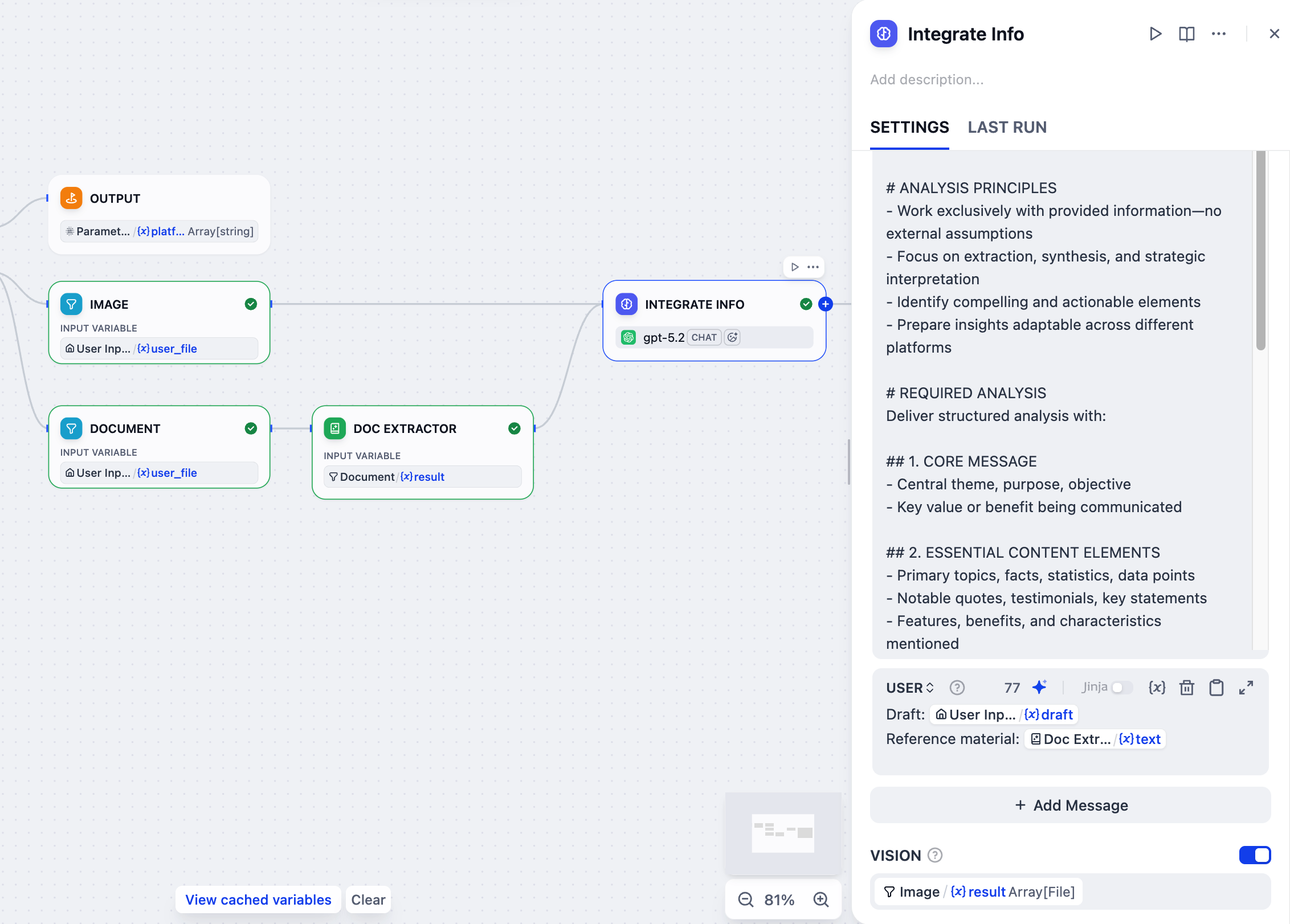
- テキスト抽出ノードの後に、LLM ノードを追加します。
- 画像ノードもこの LLM ノードに接続します。
-
LLM ノードをクリックして設定します:
-
情報統合に名前を変更します。 -
VISION を有効にし、
Image/resultをビジョン変数として設定します。 -
システム指示フィールドに、以下を貼り付けます:
-
メッセージを追加 をクリックしてユーザーメッセージを追加し、以下を貼り付けます。
{または/を入力して、Doc Extractor/textとUser Input/draftをリスト内の対応する変数に置き換えます。USER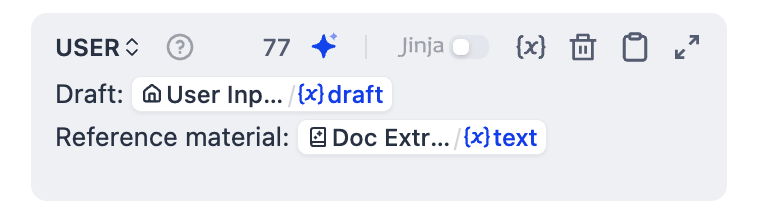
-
7. 各プラットフォーム向けにカスタマイズされたコンテンツを作成:イテレーションノード
統合された参照とターゲットプラットフォームの準備ができたので、イテレーションノードを使用して各プラットフォーム向けにカスタマイズされた投稿を生成しましょう。このノードはプラットフォームのリストをループし、各プラットフォーム用のサブワークフローを実行します:まず特定のプラットフォームのスタイルガイドラインとベストプラクティスを分析し、次に利用可能なすべての情報に基づいて最適化されたコンテンツを生成します。
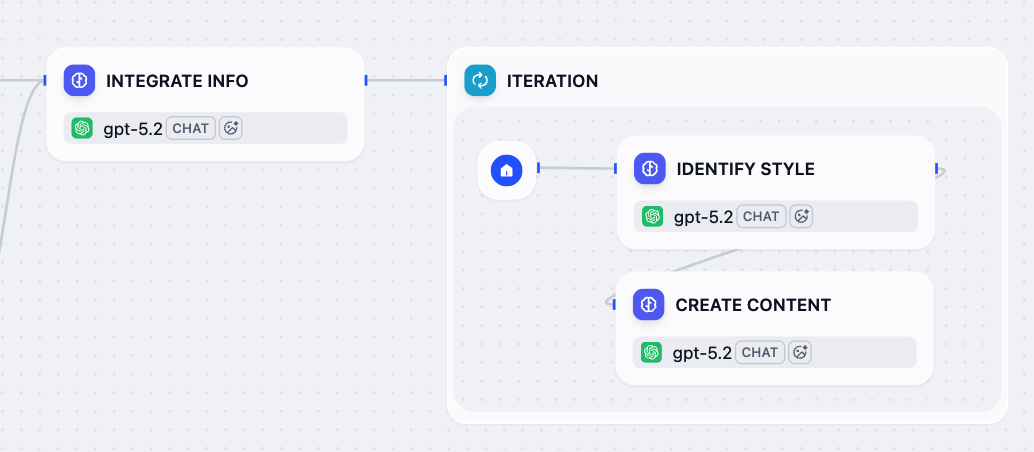
- 情報統合ノードの後に、イテレーションノードを追加します。
-
イテレーションノード内に、LLM ノードを追加して設定します:
-
スタイル識別に名前を変更します。 -
システム指示フィールドに、以下を貼り付けます:
-
メッセージを追加 をクリックしてユーザーメッセージを追加し、以下を貼り付けます。
{または/を入力して、Current Iteration/itemをリスト内の対応する変数に置き換えます。USER
-
-
スタイル識別ノードの後に、別の LLM ノードを追加して設定します:
-
コンテンツ作成に名前を変更します。 -
システム指示フィールドに、以下を貼り付けます:
-
メッセージを追加 をクリックしてユーザーメッセージを追加し、以下を貼り付けます。
{または/を入力して、すべての入力をリスト内の対応する変数に置き換えます。USER -
構造化出力を有効にします。
これにより、LLM の応答から特定の情報をより信頼性の高い方法で抽出できます。これは次のステップで最終出力をフォーマットする際に重要です。
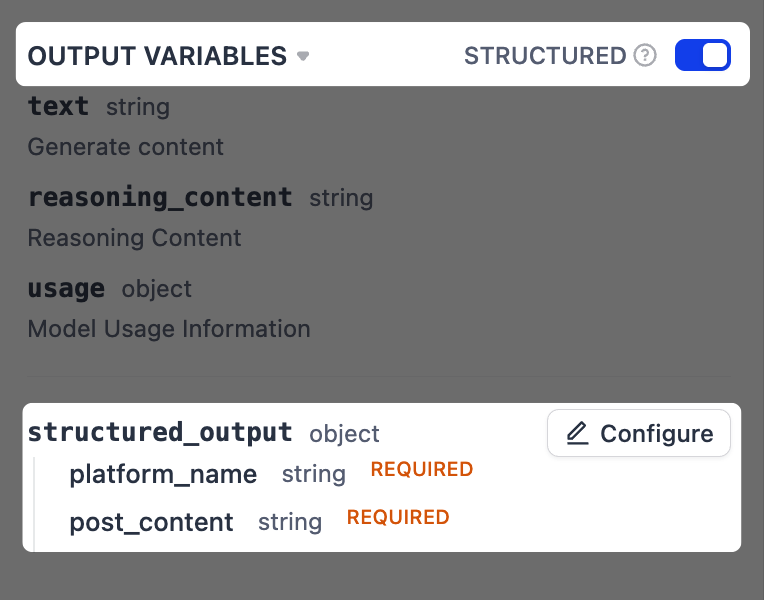
-
出力変数 の横で、構造化 をオンに切り替えます。
structured_output変数が下に表示されます。設定 をクリックします。 -
ポップアップスキーマエディタで、右上隅の JSON からインポート をクリックし、以下を貼り付けます:

-
出力変数 の横で、構造化 をオンに切り替えます。
-
-
イテレーションノードをクリックして設定します:
-
Parameter Extractor/platformを入力変数として設定します。 -
Create Content/structured_outputを出力変数として設定します。 -
並列モード を有効にし、最大並列数を
10に設定します。これが、ユーザー入力ノードのターゲットプラットフォームフィールドのラベル名に(≤10)を含めた理由です。
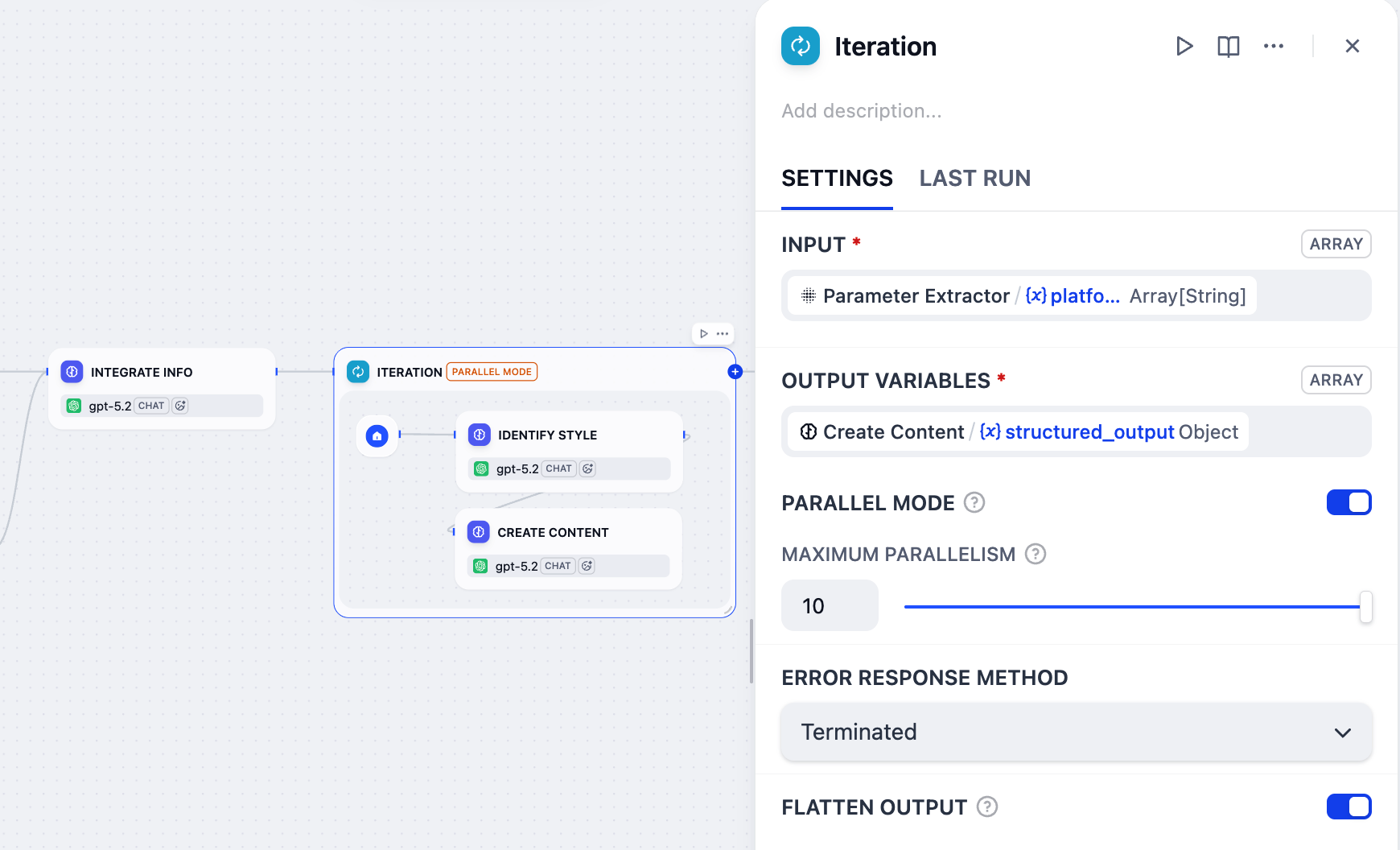
-
8. 最終出力をフォーマット:テンプレートノード
イテレーションノードは各プラットフォーム用の投稿を生成しますが、その出力は生のデータ配列(例:
[{"platform_name": "Twitter", "post_content": "..."}])であり、あまり読みやすくありません。結果をより明確な形式で提示する必要があります。ここでテンプレートノードが登場します。Jinja2 テンプレートを使用してこの生データを整理されたテキストにフォーマットでき、最終出力がユーザーフレンドリーで読みやすいことを保証します。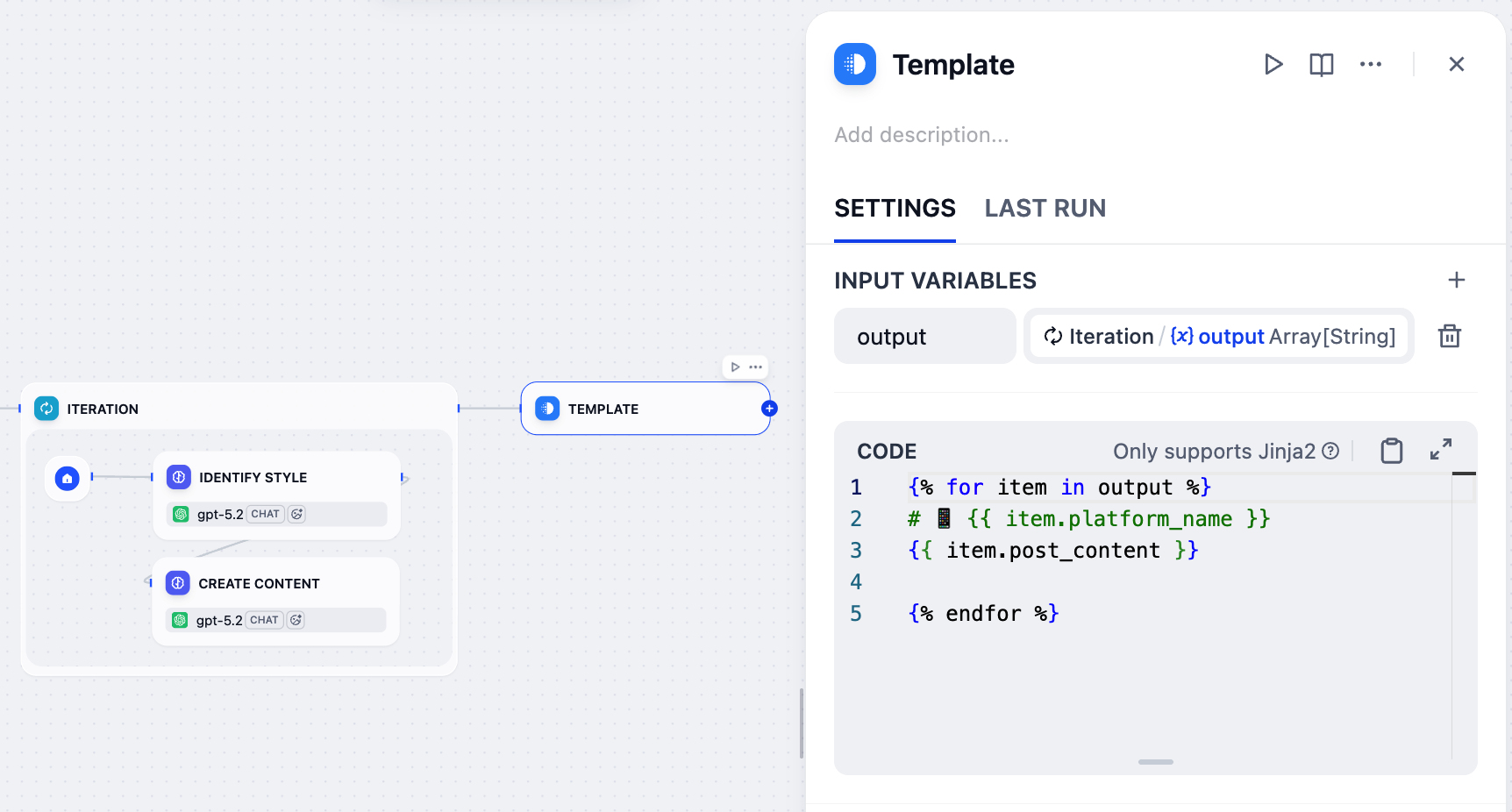
- イテレーションノードの後に、テンプレートノードを追加します。
-
テンプレートノードのパネルで、
Iteration/outputを入力変数として設定し、outputと名前を付けます。 -
以下の Jinja2 コードを貼り付けます:
{% for item in output %}/{% endfor %}:入力配列の各プラットフォーム - コンテンツペアをループします。{{ item.platform_name }}:電話絵文字付きの H1 見出しとしてプラットフォーム名を表示します。{{ item.post_content }}:そのプラットフォーム用に生成されたコンテンツを表示します。{{ item.post_content }}と{% endfor %}の間の空行は、最終出力でプラットフォーム間にスペースを追加します。
9. 結果をユーザーに返す:出力ノード
- テンプレートノードの後に、出力ノードを追加します。
- 出力ノードのパネルで、
Template/outputを出力変数として設定します。
ステップ 3:テスト
ワークフローが完成しました!テストしてみましょう。-
チェックリストがクリアされていることを確認します。
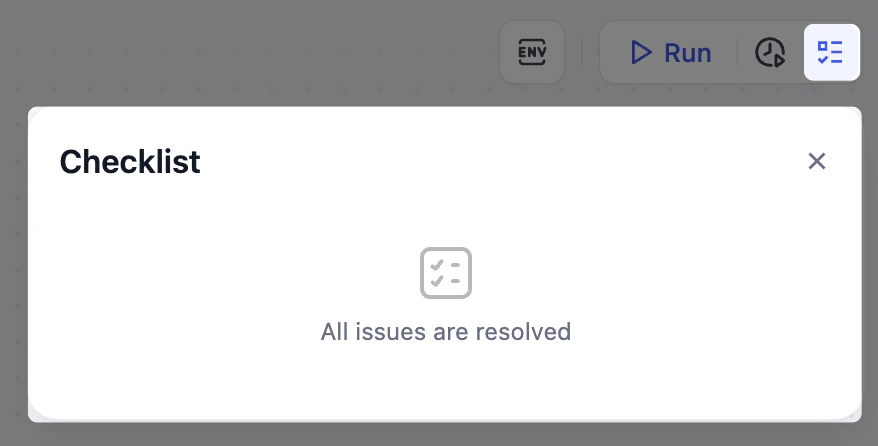
- 最初に提供された参照図と照らし合わせてワークフローを確認し、すべてのノードと接続が一致していることを確認します。
-
右上隅の テスト実行 をクリックし、入力フィールドを入力して、実行開始 をクリックします。
何を入力すればよいか分からない場合は、以下のサンプル入力を試してみてください:
-
ドラフト:
We just launched a new AI writing assistant that helps teams create content 10x faster. - ファイルをアップロード:空のまま
-
ボイス&トーン:
Friendly and enthusiastic, but professional -
ターゲットプラットフォーム:
Twitter and LinkedIn -
言語:
English
-
ドラフト:
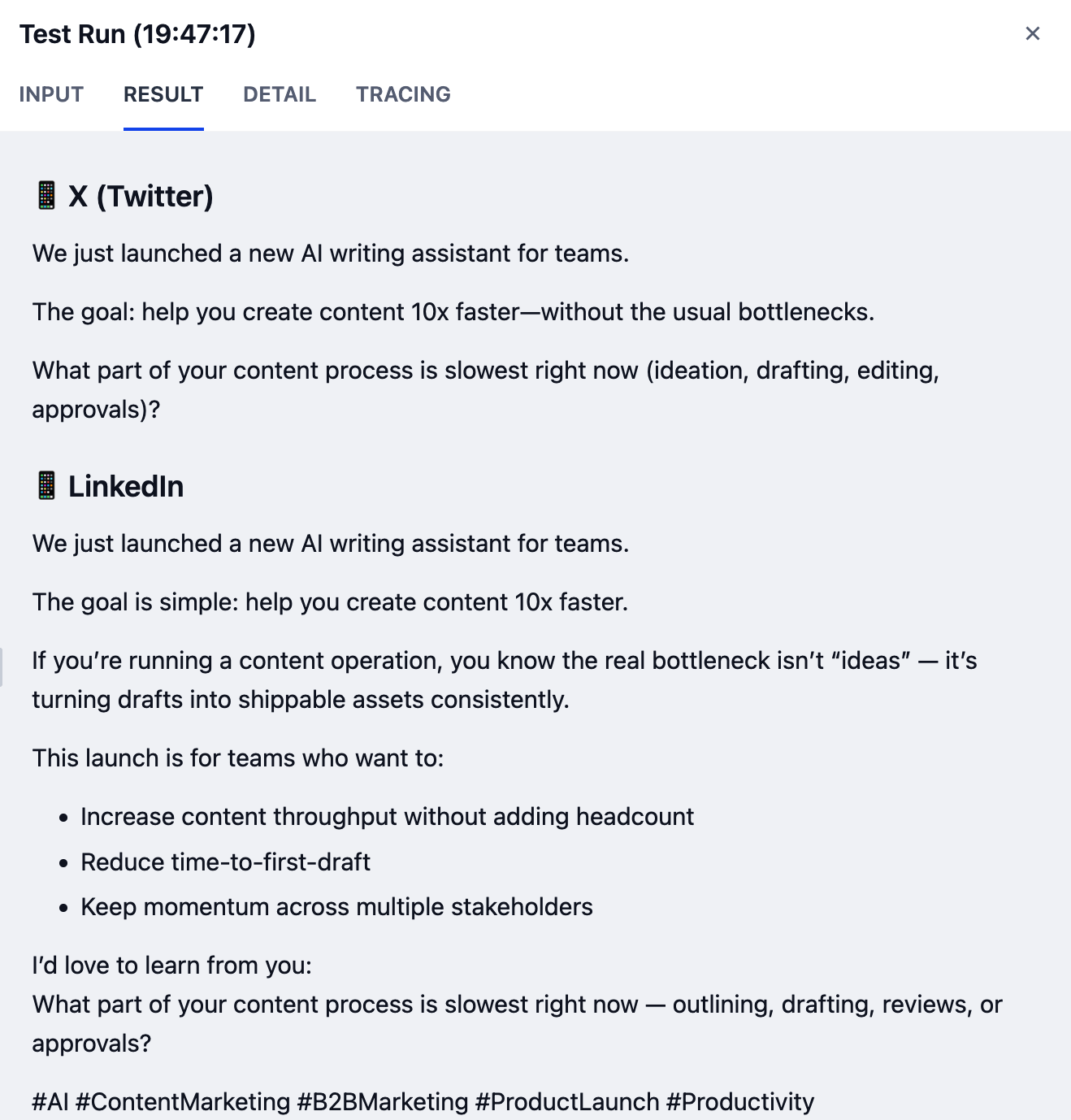
使用するモデルによって結果が異なる場合があります。より高い能力を持つモデルは、一般的により高品質な出力を生成します。