

プラグインの仕組み
- オーナーと管理者
- 編集者とメンバー
ワークスペース全体のプラグインをインストール、設定、削除
プラグインのインストール
マーケットプレイス
テストされメンテナンスされている公式およびパートナープラグイン
GitHub
URL + バージョンで任意の公開リポジトリからインストール
ローカルアップロード
プライベートまたは内部プラグイン用のカスタム.zipパッケージ
プラグインの本質
プラグインをDifyと外部世界を繋ぐ橋として考えてください:モデルプロバイダー
Difyのすべての LLM(OpenAI、Anthropicなど)は実際にはプラグインです
ツールと関数
API呼び出し、データ処理、計算——すべてプラグインベース
カスタムエンドポイント
外部システムが呼び出せるAPIとしてDifyアプリを公開
リバースコーリング
プラグインはDifyにコールバックしてモデル、ツール、ワークフローを使用可能
ワークスペースプラグイン設定
ワークスペース設定でプラグイン権限を制御:インストール権限
インストール権限
全員 - 任意のメンバーがプラグインをインストール可能
管理者のみ - ワークスペース管理者のみインストール可能(推奨)
デバッグアクセス
デバッグアクセス
全員 - すべてのメンバーがプラグインの問題をデバッグ可能
管理者のみ - デバッグを管理者に制限
自動更新
自動更新
更新戦略(セキュリティのみ vs すべての更新)を選択し、含めるまたは除外するプラグインを指定
プラグインインストール制限
エンタープライズ限定
- プラグイン → マーケットプレイスを探索の「プラグインをインストール」ドロップダウンが限定的なオプションを表示
- インストール確認ダイアログでプラグインがポリシーによってブロックされているか表示
- プラグイン付きアプリ(DSLファイル)をインポートする際、制限されたプラグインについての通知が表示
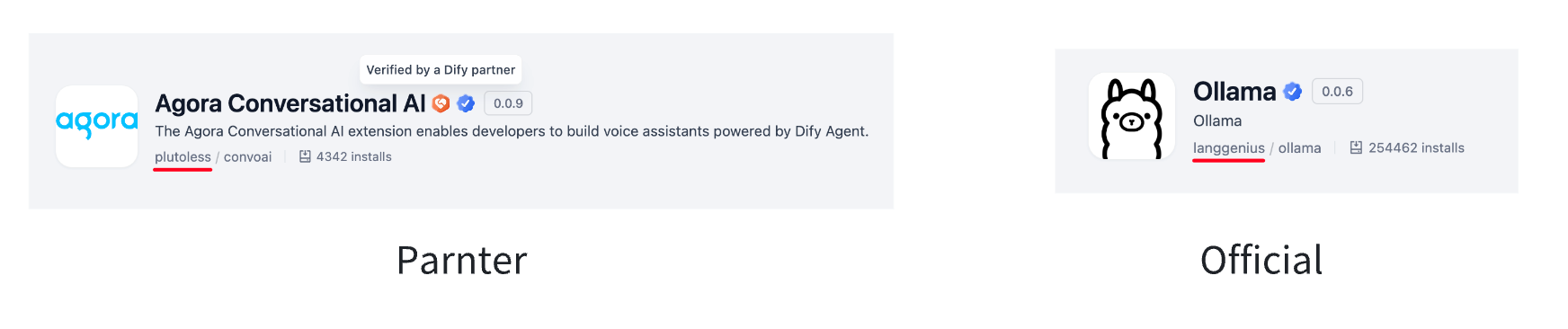 これらのバッジを探してプラグインタイプを識別——管理者設定に基づいて、ワークスペースは特定のタイプのみを許可する場合があります。
これらのバッジを探してプラグインタイプを識別——管理者設定に基づいて、ワークスペースは特定のタイプのみを許可する場合があります。
必要なプラグインをインストールできない場合は、ワークスペース管理者に連絡してください。管理者は、どのプラグインソース(マーケットプレイス、GitHub、ローカルファイル)とタイプ(公式、パートナー、サードパーティ)が許可されるかを制御しています。
カスタムプラグインの構築
カスタム機能が必要な場合、DifyのSDKを使用してプラグインを開発:- 設定 → プラグイン → デバッグからデバッグキーを取得
- ローカルでプラグインをビルドしてテスト
- マニフェストと依存関係を含む.zipとしてパッケージ化
- プライベートで配布するか、マーケットプレイスに公開