

⚠️ このドキュメントはAIによって自動翻訳されています。不正確な部分がある場合は、英語版を参照してください。
設定
入力とモデル選択
パラメータを抽出したいテキストを含む入力変数を選択します。これは通常、ユーザー入力、大規模言語モデルの応答、またはその他のワークフローノードから取得されます。 優れた構造化出力機能を持つモデルを選択します。パラメータ抽出器は、大規模言語モデルのコンテキスト理解能力と構造化JSON応答の生成能力に依存しています。パラメータ定義
抽出したいパラメータを以下の項目を指定して定義します:- パラメータ名 - 出力JSONに表示されるキー
- データ型 - 文字列、数値、ブール値、配列、またはオブジェクト
- 説明 - 大規模言語モデルが何を抽出すべきかを理解するのに役立ちます
- 必須ステータス - パラメータが必須かどうか
抽出指示
抽出すべき情報とその形式について説明する明確な指示を作成します。指示に例を含めることで、複雑なパラメータの抽出精度と一貫性が向上します。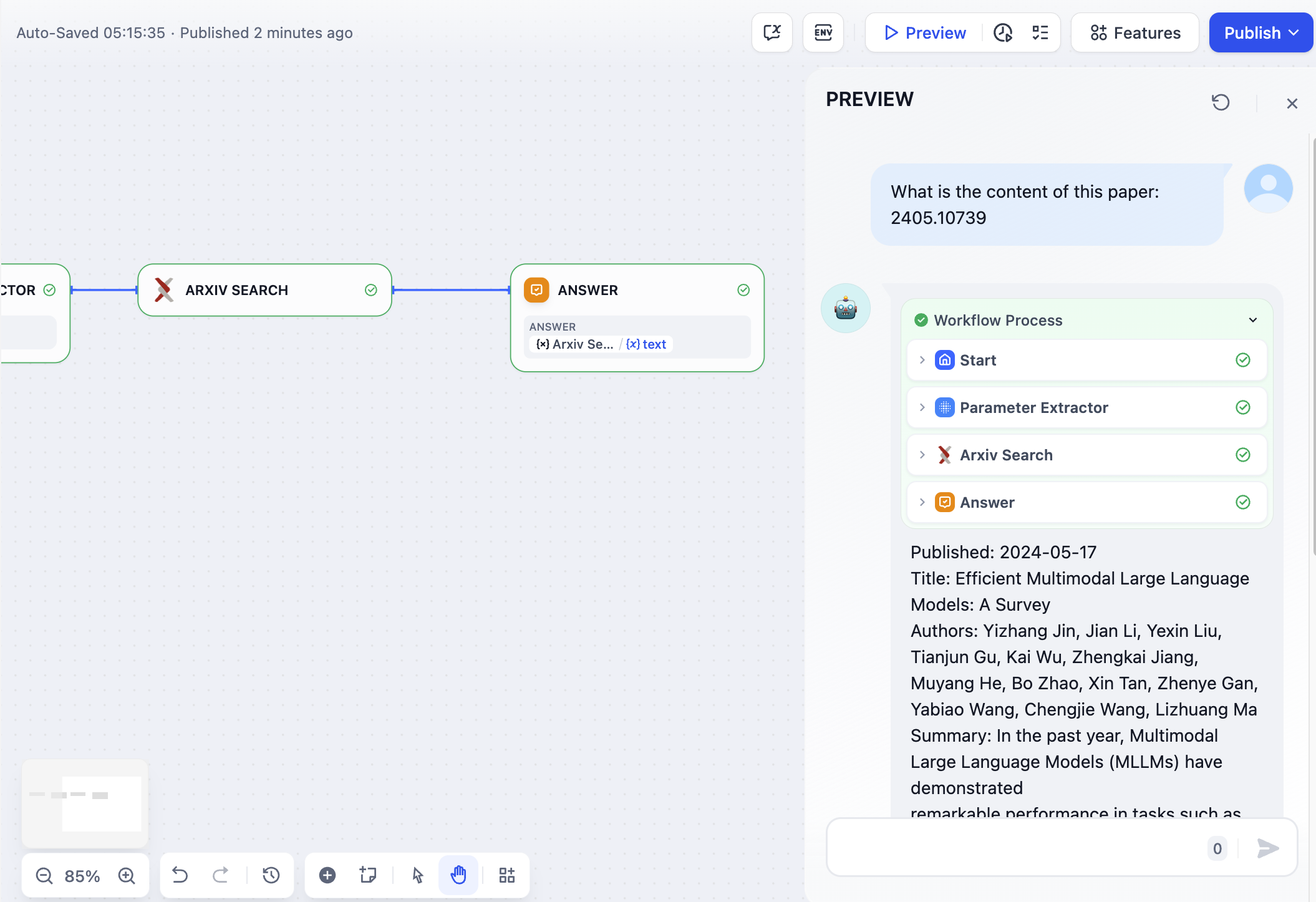
Arxiv論文検索のパラメータ抽出
高度な設定
推論モード
モデルの機能に基づいて、2つの抽出アプローチから選択します: 関数呼び出し/ツール呼び出しは、モデルの構造化出力機能を使用して、強力な型準拠による信頼性の高いパラメータ抽出を行います。 プロンプトベースは、関数呼び出しをサポートしないモデルや、プロンプトベースの抽出がより良いパフォーマンスを発揮する場合に、純粋なプロンプトに依存します。メモリ
パラメータを抽出する際に会話履歴を含めるためにメモリを有効にします。これにより、大規模言語モデルが対話形式でのコンテキストを理解し、対話型ワークフローでの抽出精度が向上します。出力変数
このノードは、抽出されたパラメータと組み込みステータス変数の両方を提供します: 抽出されたパラメータは、パラメータ定義に一致する個別の変数として表示され、下流ノードでの使用に対応しています。 組み込み変数には、ステータス - 抽出成功ステータス(成功の場合は1、失敗の場合は0)__reason- 抽出が失敗した場合のエラー説明
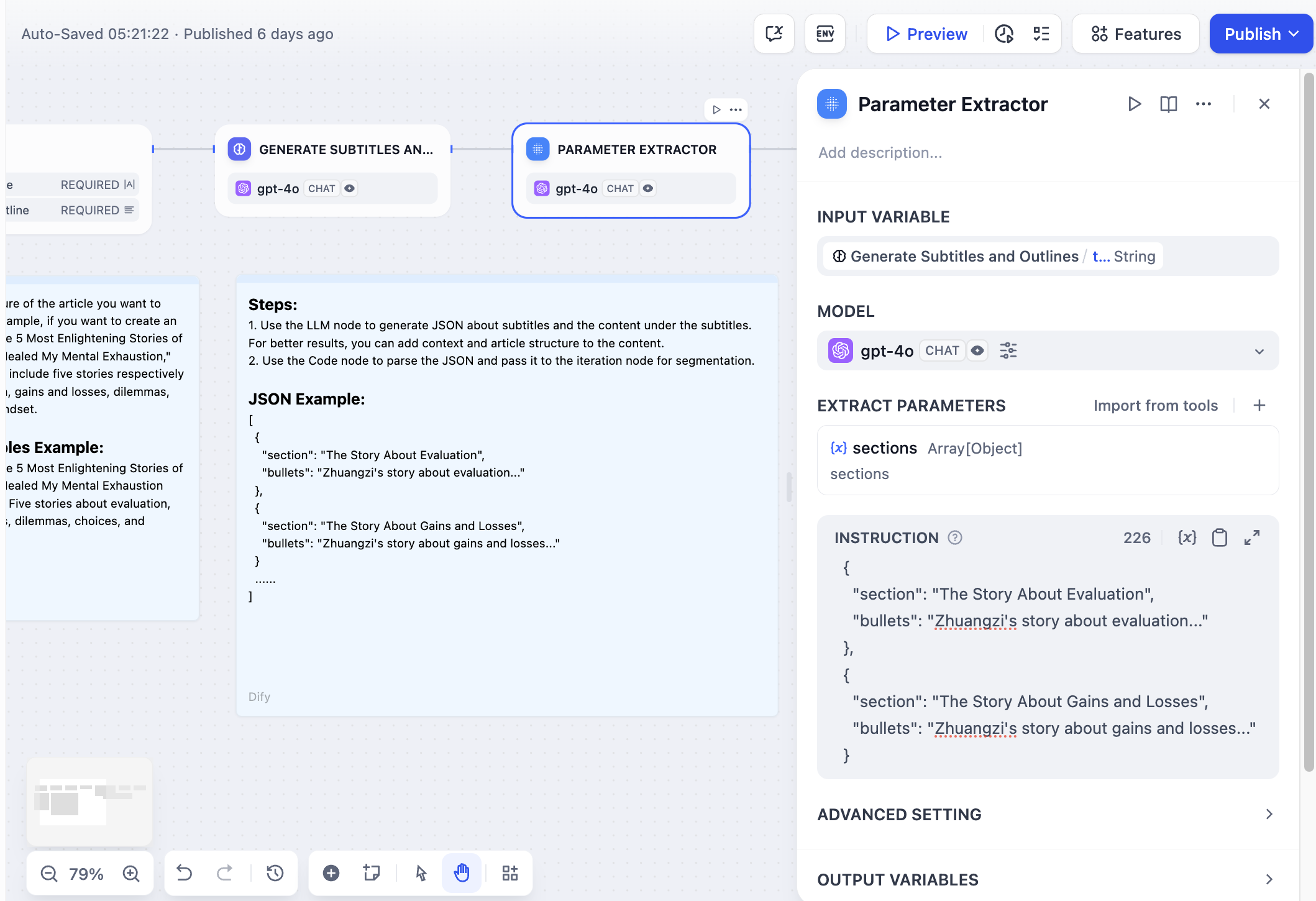
データ形式変換の例
一般的なユースケース
ツールパラメータ準備は、構造化入力を必要とするワークフローツールのために、自然言語から特定のパラメータを抽出します。 データ形式変換は、テキストを他のノードが必要とする形式に変換します。例えば、リストを反復処理用の配列に変換します。 APIリクエスト準備は、外部サービスへのHTTPリクエストのためにデータを構造化し、ユーザーの意図からAPIと互換性のあるパラメータへの変換を処理します。 フォームデータ処理は、データベース保存やさらなる処理のために、自由形式のユーザー入力から構造化情報を抽出します。ベストプラクティス
明確なパラメータ説明は、大規模言語モデルが正確にどのような情報をどの形式で抽出すべきかを理解するのに役立ちます。 指示に例を含めることで、特に複雑またはドメイン固有のパラメータの抽出精度が向上します。 適切なデータ型を使用して、抽出されたパラメータが下流ノードの要件に確実に一致するようにします。 抽出失敗への対処は、__is_success変数をチェックし、抽出が失敗した場合のフォールバックロジックを提供することで行います。