

⚠️ このドキュメントはAIによって自動翻訳されています。不正確な部分がある場合は、英語版を参照してください。
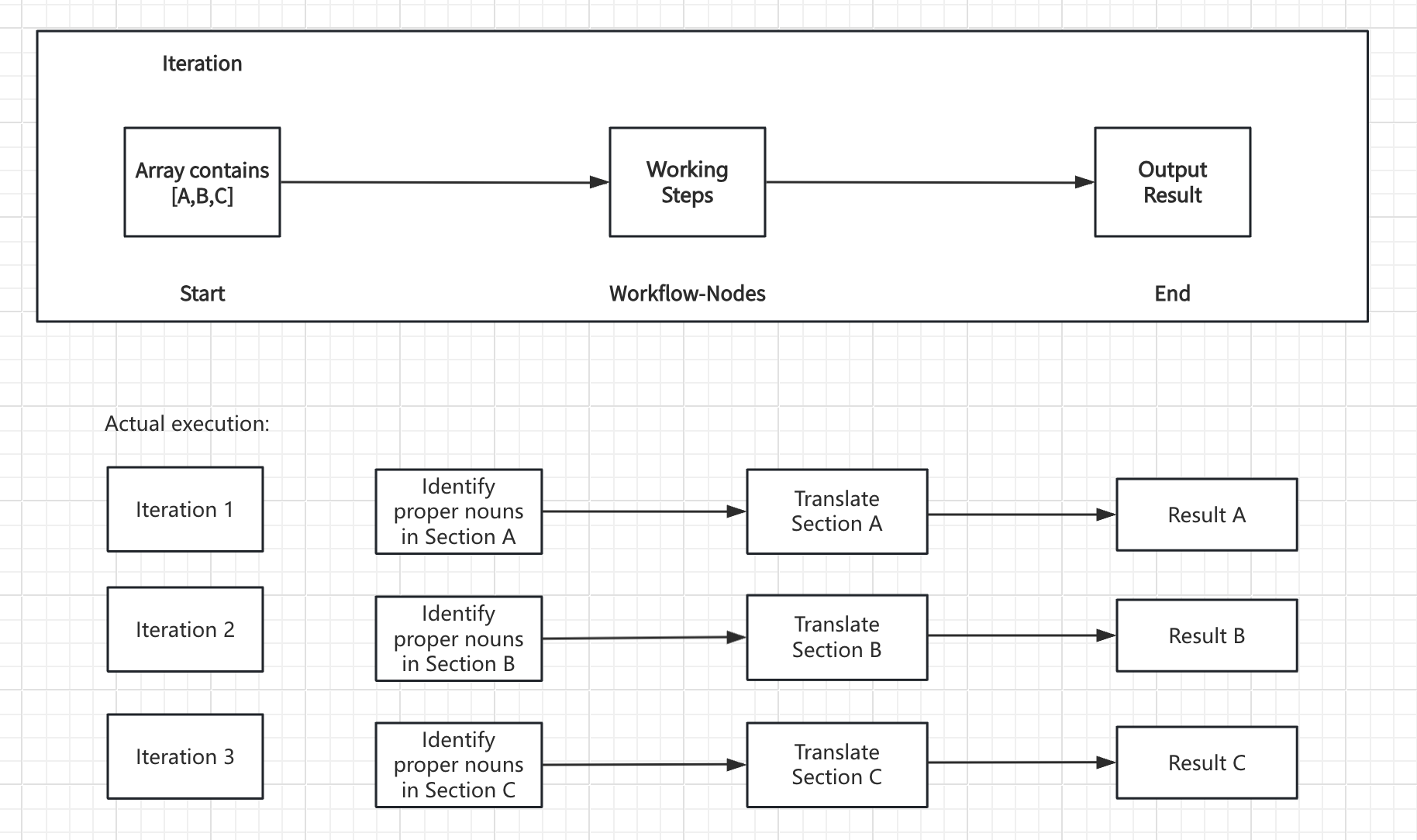
ワークフローを処理する反復処理ノード
反復処理の動作原理
このノードは配列入力を受け取り、配列の各要素に対して一度実行されるサブワークフローを作成します。各反復処理中、現在のアイテムとそのインデックスが変数として使用可能になり、内部ノードから参照できます。 コアコンポーネント:- 入力変数 - 上流ノードからの配列データ
- 内部ワークフロー - 各要素に対して実行する処理ステップ
- 出力変数 - すべての反復処理から収集された結果(同じく配列)
設定
配列入力
パラメータ抽出器、コードノード、知識検索、またはHTTPリクエストレスポンスなどの上流ノードから配列変数を接続します。組み込み変数
各反復処理では以下にアクセスできます:items[object]- 処理中の現在の配列要素index[number]- 現在の反復処理インデックス(0から開始)
処理モード
- シーケンシャルモード
- 並列モード
順次処理 - アイテムが順序通りに一つずつ処理されますストリーミングサポート - 回答ノードを使用して結果を段階的に出力できますリソース管理 - メモリ使用量が少なく、実行順序が予測可能です最適な用途 - 順序が重要な場合やストリーミング出力を使用する場合
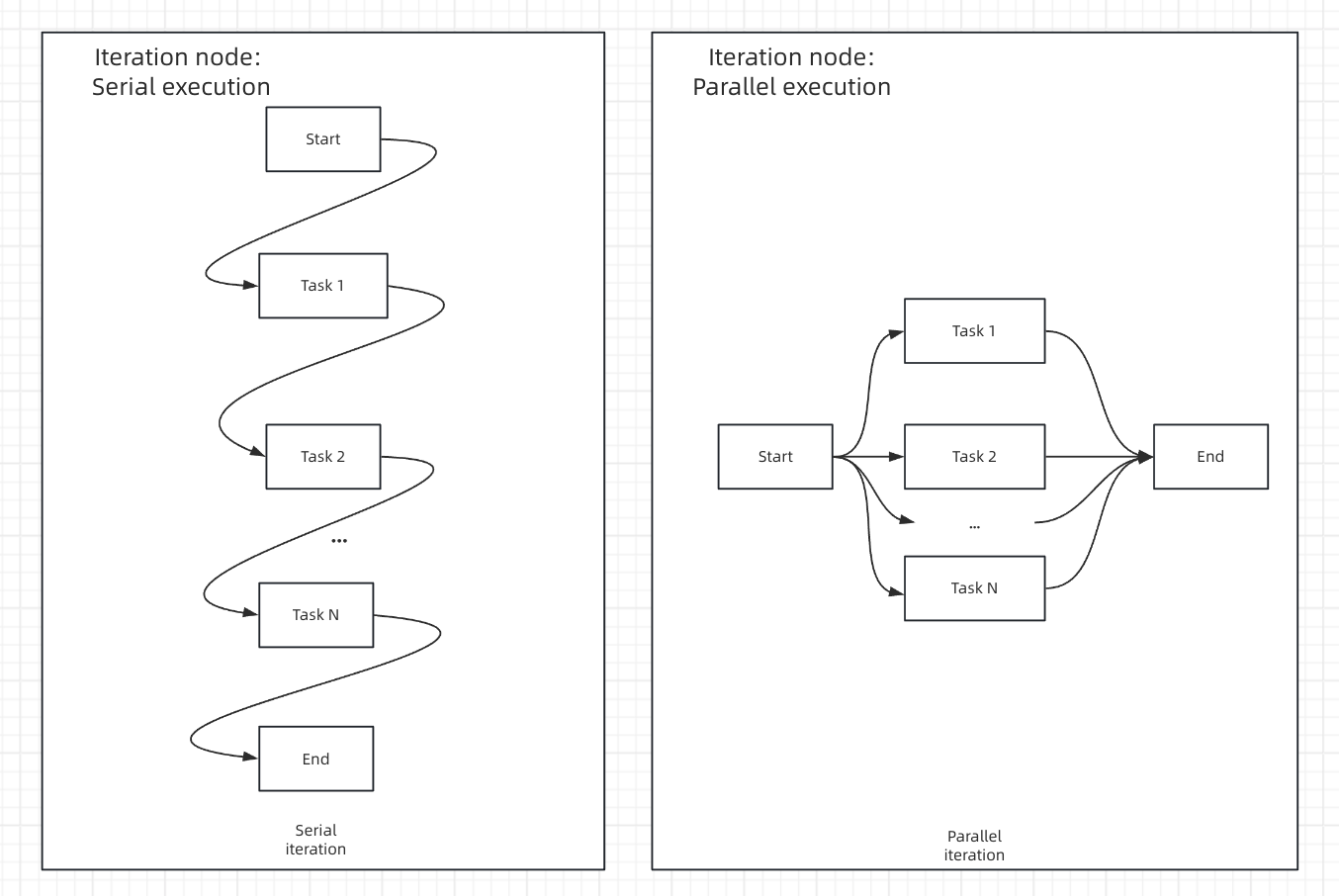
順次処理と並列処理の比較
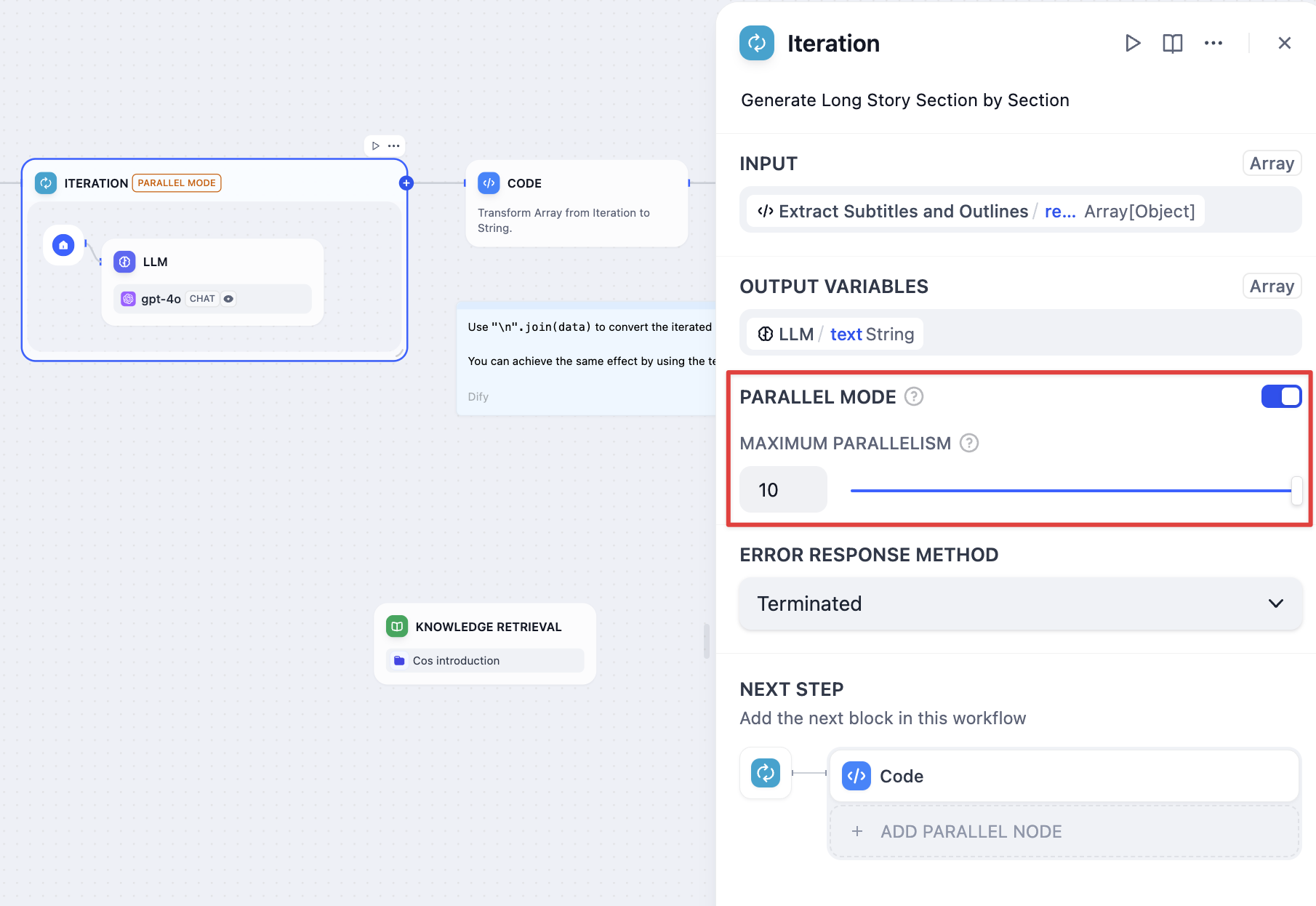
反復処理設定で並列モードを有効化
エラーハンドリング
個々の配列要素の処理失敗をどう処理するかを設定します: 終了 - エラーが発生した時点で処理を停止し、エラーメッセージを返します エラー時継続 - 失敗したアイテムをスキップして処理を継 失敗結果を除去 - 失敗したアイテムをスキップし、成功した結果のみを返します 入出力対応の例:- 入力:
[1, 2, 3] - エラー時継続での出力:
[result-1, null, result-3] - 失敗結果を除去での出力:
[result-1, result-3]
長文記事生成の例
章立てを個別に処理して長いコンテンツを生成します: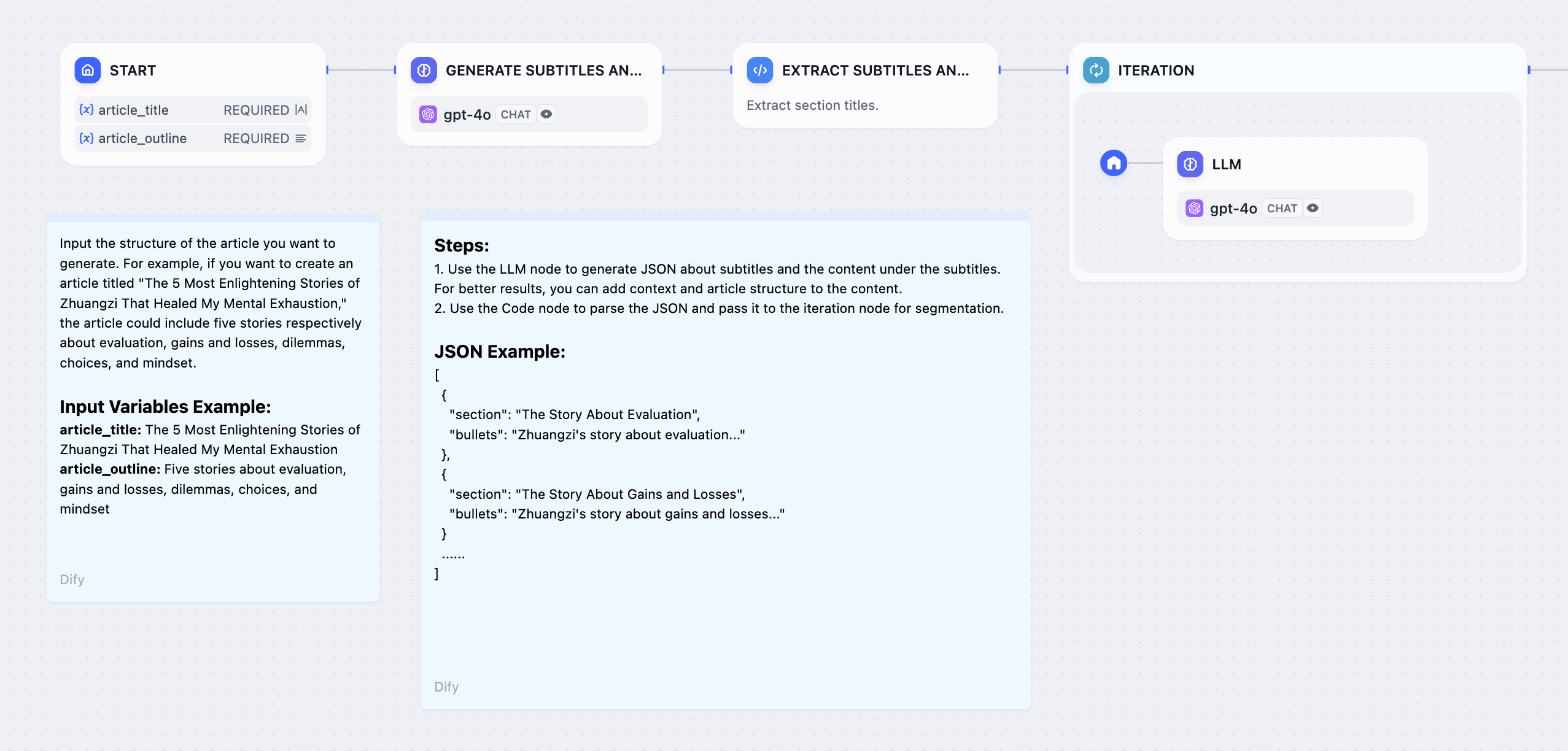
長文記事生成ワークフロー
- 開始ノード - ユーザーがストーリータイトルと概要を提供
- 大規模言語モデルノード - 詳細な章立てを生成
- パラメータ抽出器 - 章リストを構造化配列に変換
- 反復処理ノード - 内部の大規模言語モデルで各章を処理
- 回答ノード - 生成された章コンテンツをストリーミング配信
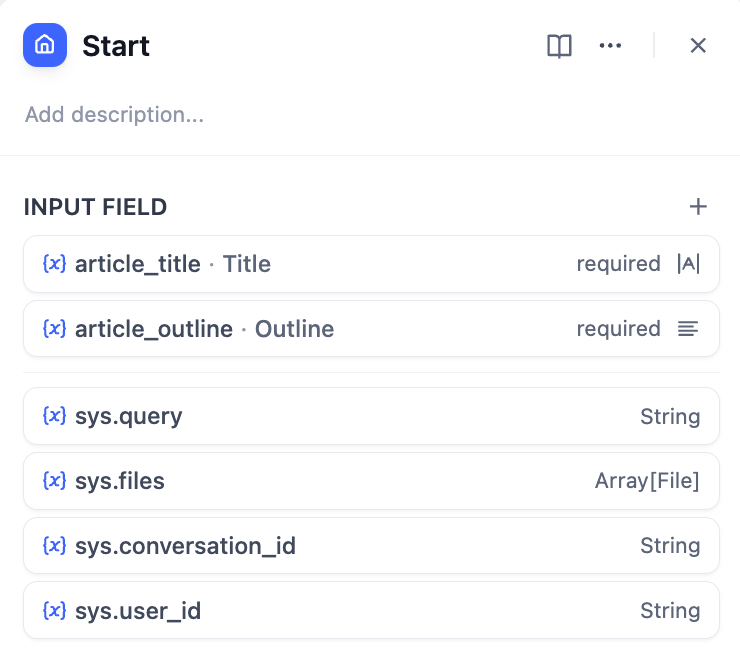
ストーリー入力用の開始ノード設定
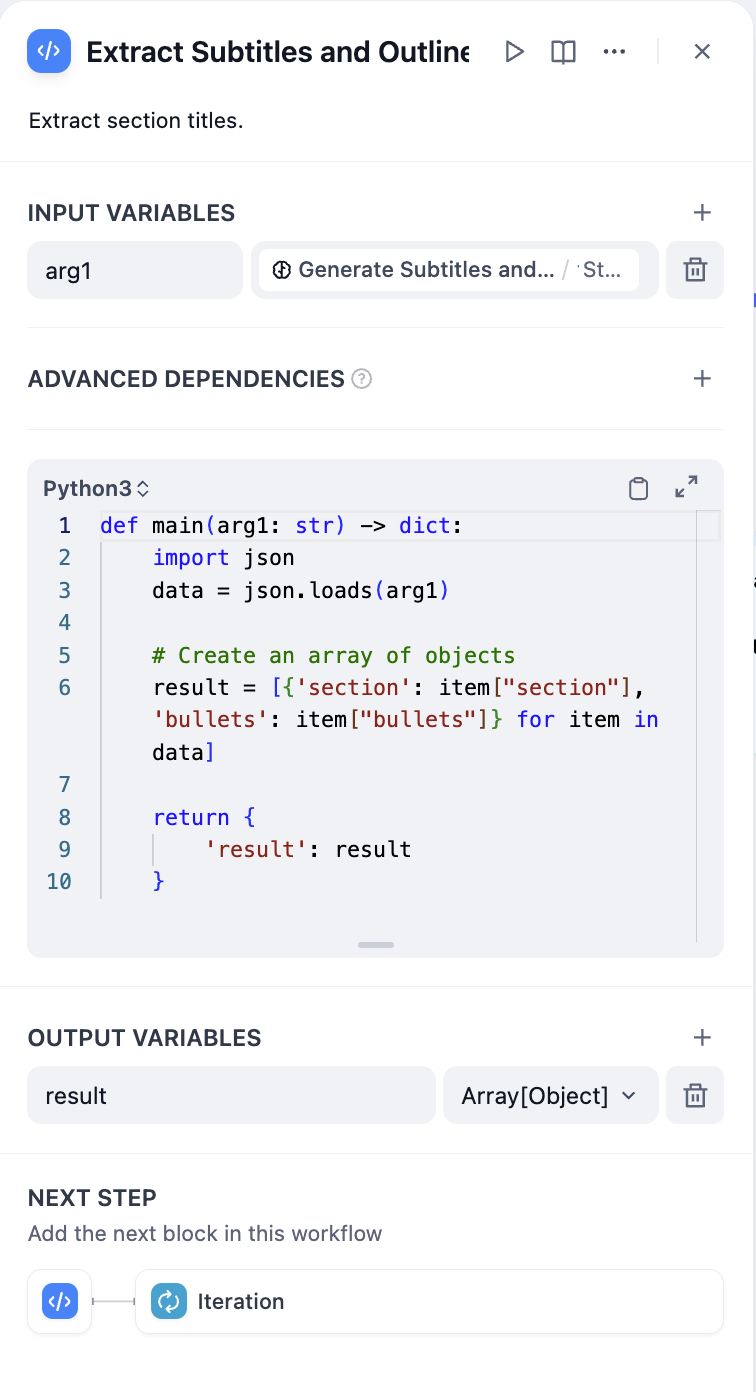
章構造のパラメータ抽出
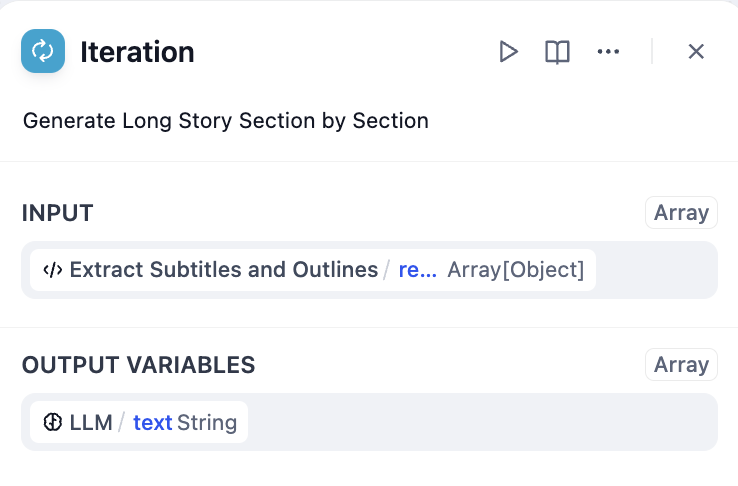
大規模言語モデル処理を含む反復処理設定
パラメータ抽出の効果は、モデルの能力と指示の品質に依存します。より強力なモデルを使用し、指示に例を含めることで結果を改善できます。
出力処理
反復処理ノードは配列を出力しますが、最終使用時には変換が必要な場合があります:配列をテキストに変換
- コードノードを使用
- テンプレートノードを使用
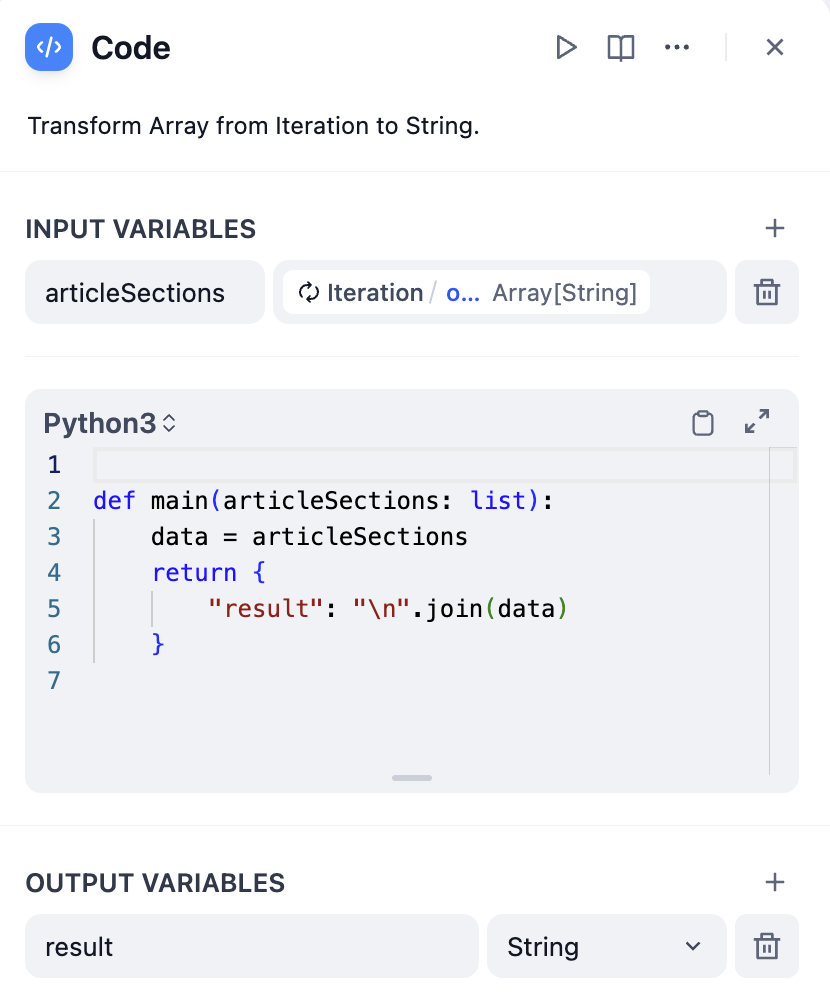
コードノードでの配列変換