

⚠️ このドキュメントはAIによって自動翻訳されています。不正確な部分がある場合は、英語版を参照してください。
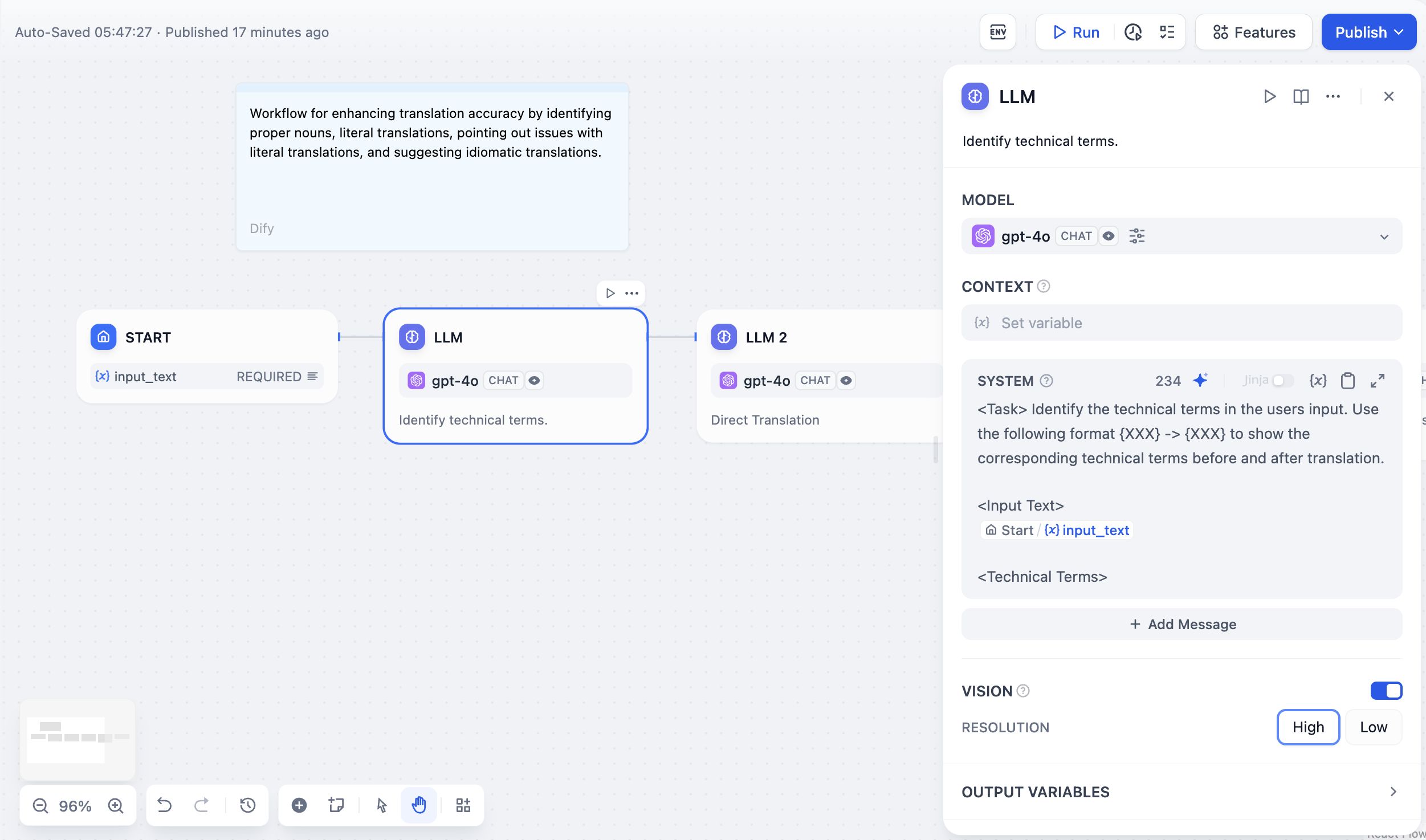
LLMノード設定インターフェース
LLMノードを使用する前に、システム設定 → モデルプロバイダーで少なくとも1つのモデルプロバイダーを設定してください。セットアップ手順についてはモデル設定ガイドをご覧ください。
モデル選択とパラメーター
設定したモデルプロバイダーから任意のモデルを選択できます。異なるモデルはそれぞれ異なるタスクに適しています。GPT-4とClaude 3.5は複雑な推論を得意としますがコストが高く、GPT-3.5 Turboは機能と価格のバランスが取れています。ローカル展開には、Ollama、LocalAI、Xinferenceを使用してください。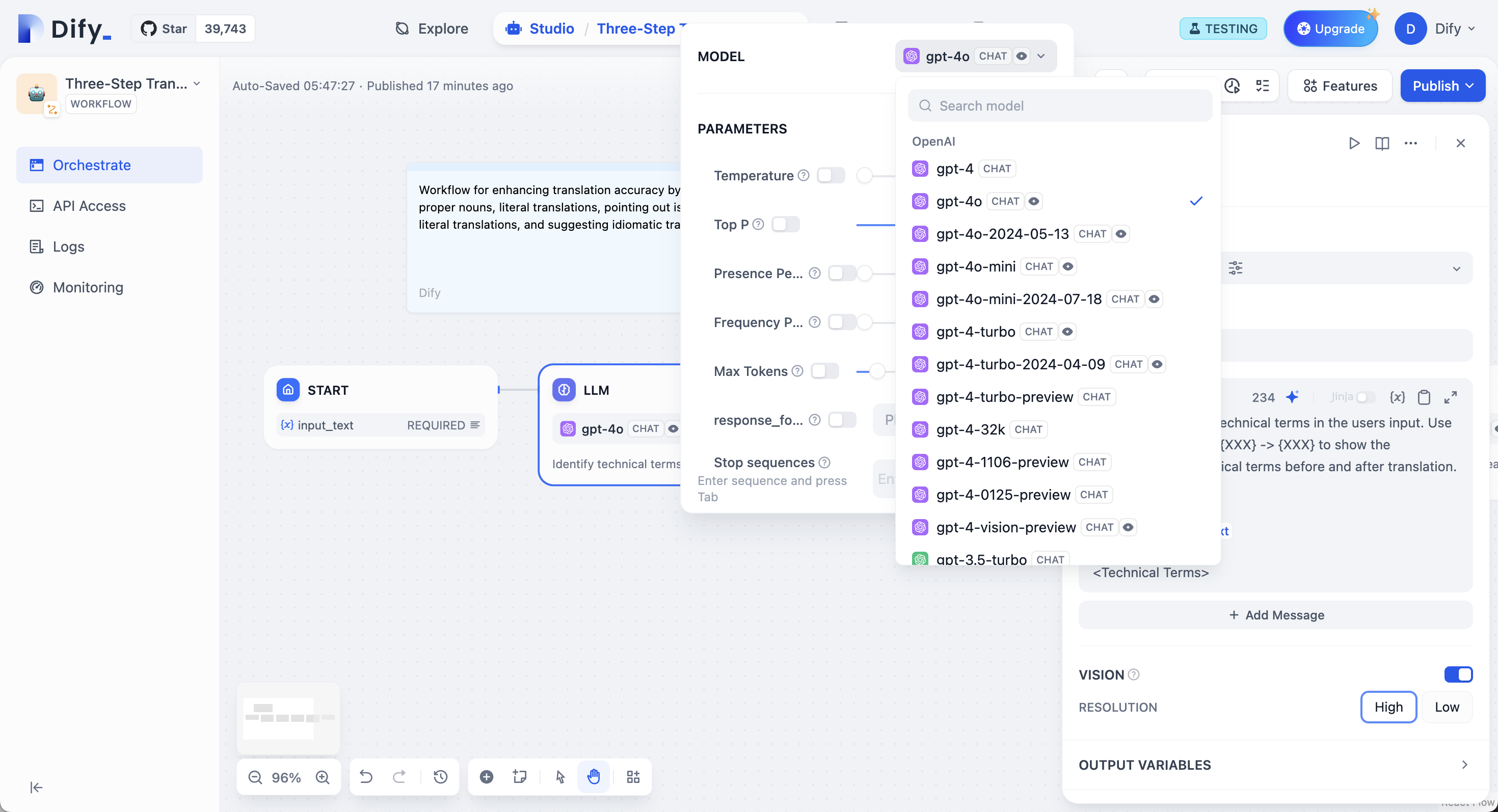
モデル選択とパラメーター設定
プロンプト設定
インターフェースはモデルタイプに基づいて適応します。チャットモデルではメッセージロール(システムは動作用、ユーザーは入力用、アシスタントは例用)を使用し、補完モデルでは単純なテキスト継続を使用します。 プロンプト内でワークフロー変数を二重中括弧で参照します:{{variable_name}}。変数はモデルに到達する前に実際の値で置き換えられます。
コンテキスト変数
コンース帰属を保持しながら外部知識を注入します。これにより、大規模言語モデルがあなたの特定のドキュメントを使用して質問に答えるRAGアプリケーションが可能になります。
RAGアプリケーションでのコンテキスト変数の使用
構造化出力
プログラムで使用するために、JSONなどの特定のデータ形式での応答をモデルに強制します。3つの方法で設定できます:- ビジュアルエディター
- JSONスキーマ
- AI生成
シンプルな構造のためのユーザーフレンドリーなインターフェース。名前とタイプでフィールドを追加し、必須フィールドをマークし、説明を設定します。エディターは自動的にJSONスキーマを生成します。
メモリとファイル処理
メモリを有効にすると、ワークフロー実行内の複数のLLM呼び出しでコンテキストを維持できます。ノードは以前のインタラクションを後続のプロンプトに含めます。メモリはノード固有であり、ワークフロー実行間では持続しません。 ファイル処理では、マルチモーダルモデル用にプロンプトにファイル変数を追加します。GPT-4Vは画像をaudeはPDFを直接処理しますが、他のモデルでは前処理が必要な場合があります。ビジョン機能設定
画像を処理する際、詳細レベルを制御できます:- 高詳細 - 複雑な画像でより良い精度を提供しますが、より多くのトークンを使用します
- 低詳細 - シンプルな画像でより少ないトークンでより高速な処理
sys.filesで、開始ノードからファイルを自動的に取得します。
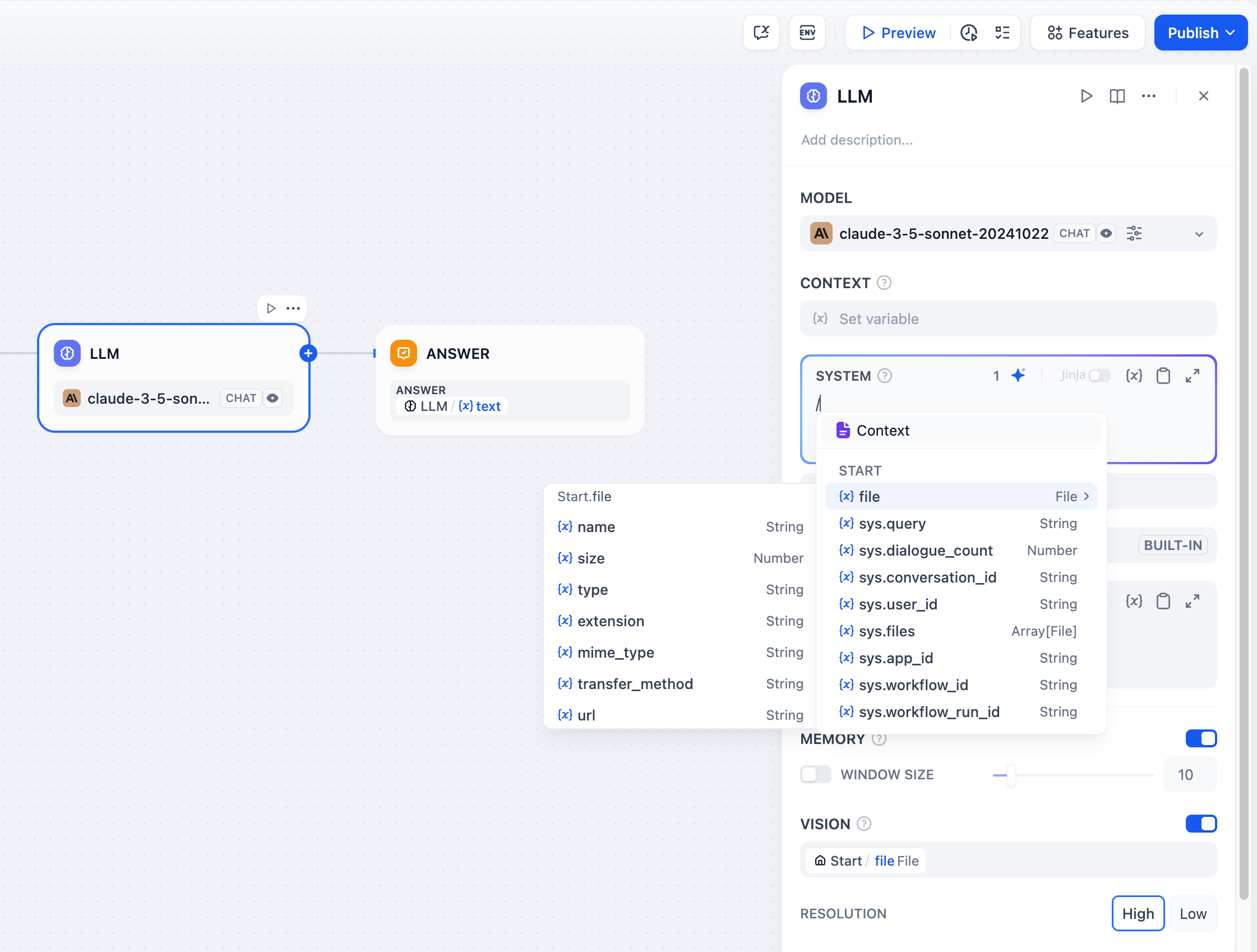
マルチモーダル大規模言語モデルでのファイル処理
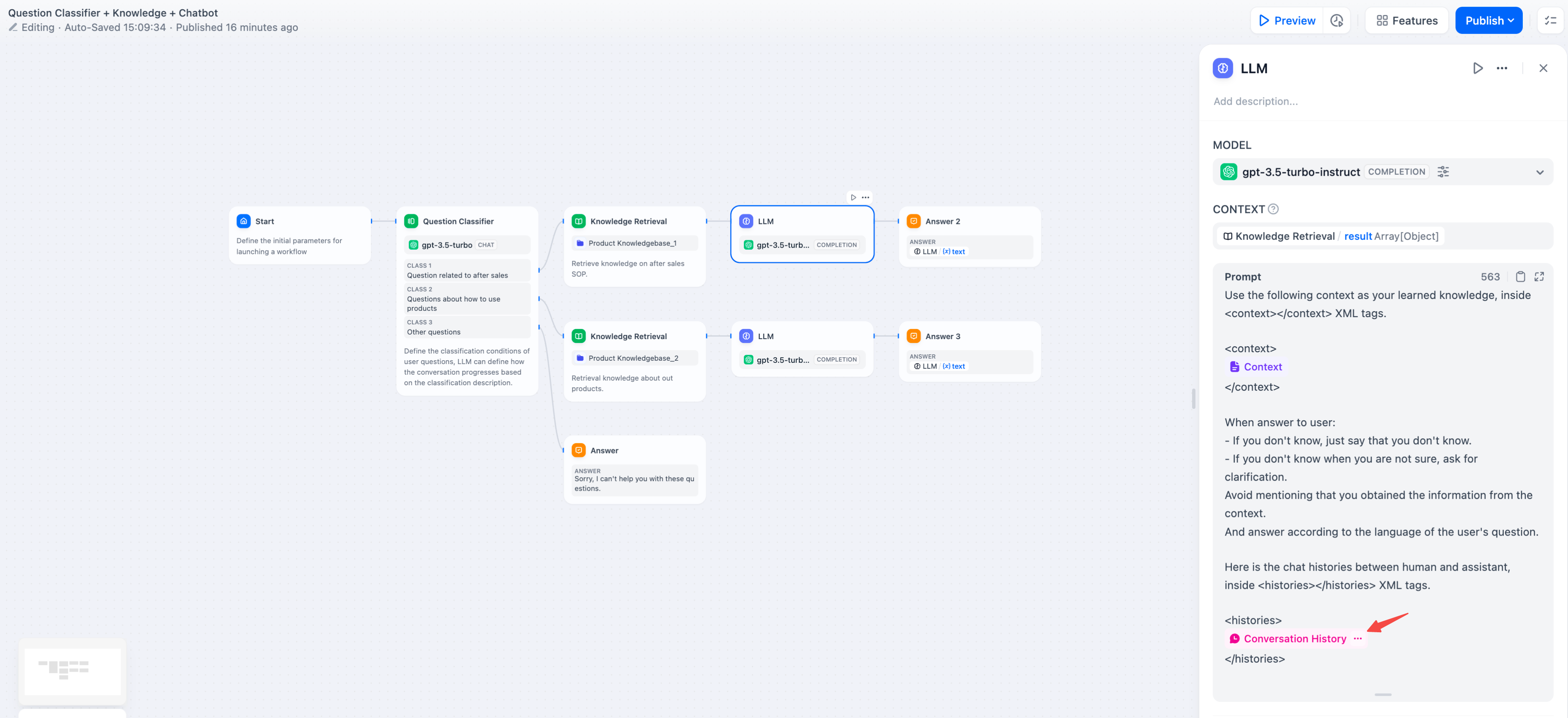
会話履歴変数の使用
Jinja2テンプレートサポート
LLMプロンプトは高度な変数処理のためにJinja2テンプレートをサポートしています。Jinja2モード(edition_type: "jinja2")を使用すると、次のことができます:
ストリーミングレスポンス
LLMノードはデフォルトでストリーミングレスポンスをサポートしています。各テキストチャンクはRunStreamChunkEventとして生成され、リアルタイムの応答表示が可能になります。ファイル出力(画像、ドキュメント)はストリーミング中に自動的に処理され保存されます。