

⚠️ このドキュメントはAIによって自動翻訳されています。不正確な部分がある場合は、英語版を参照してください。
設定
入力とモデルセットアップ
入力変数 - 分類する内容を選択します。通常はユーザーの質問に対してsys.queryを使用しますが、前のワークフローノードからの任意のテキスト変数も使用できます。
モデル選択 - 分類用の大規模言語モデルを選択します。高速なモデルは単純なカテゴリには適していますが、より強力なモデルは微妙な区別をより適切に処理できます。
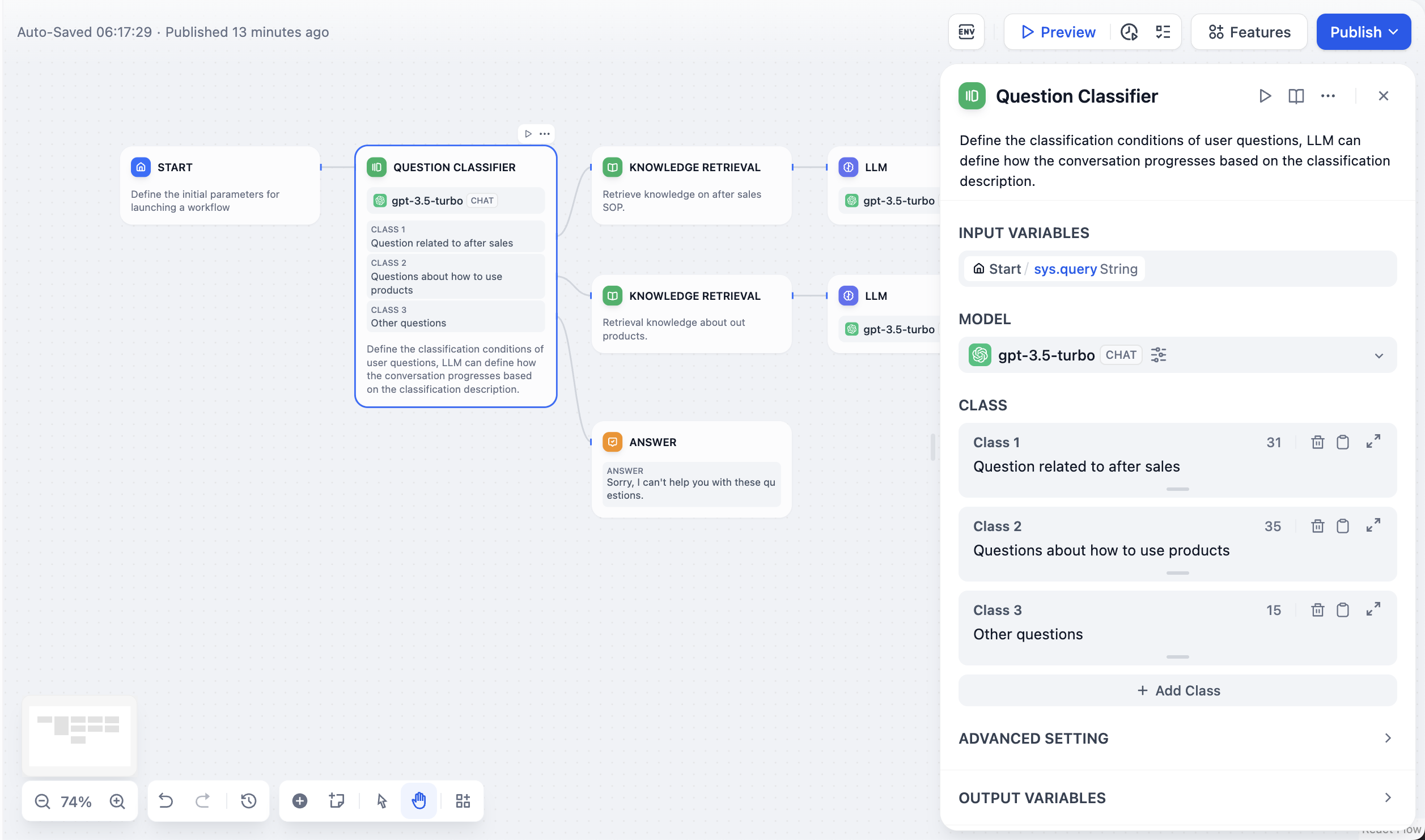
Question Classifier configuration interface
カテゴリ定義
各カテゴリに属するものについての具体的な説明を含む、明確で説明的なラベルを作成します。大規模言語モデルが正確な決定を下せるよう、カテゴリ間の境界について正確に記述してください。 各カテゴリは潜在的な出力パスとなり、専門的な知識ベース、レスポンステンプレート、または処理ワークフローなど、異なる下流ノードに接続できます。分類例
以下は、カスタマーサービスシナリオでの質問分類器の動作例です: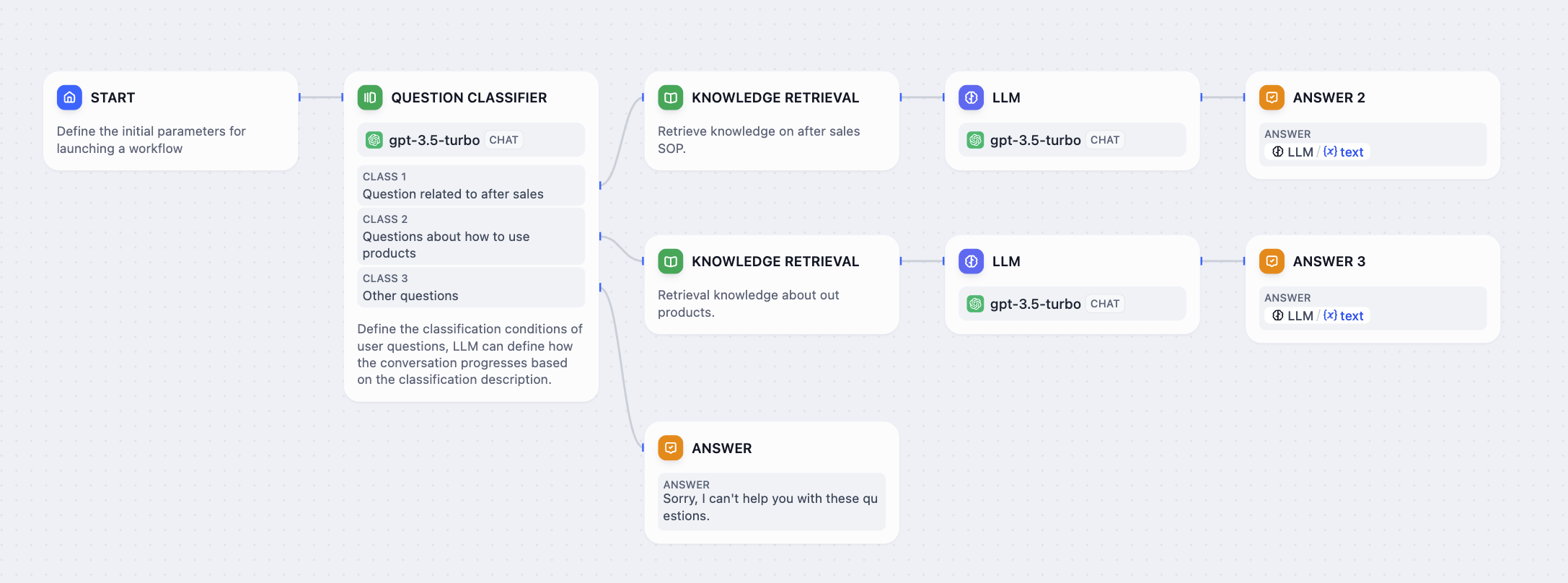
Customer service classification workflow
- アフターサービス - 保証請求、返品、修理、購入後サポート
- 製品使用 - セットアップ手順、トラブルシューティング、機能説明
- その他の質問 - 特定のカテゴリでカバーされない一般的な問い合わせ
- “iPhone 14で連絡先を設定する方法は?” → 製品使用
- “私の購入品の保証期間は何ですか?” → アフターサービス
- “今日の天気はどうですか?” → その他の質問
高度な設定
指示とガイドライン
指示フィールドに詳細な分類ガイドラインを追加して、エッジケース、曖昧なシナリオ、または特定のビジネスルールを処理します。これにより、大規模言語モデルがカテゴリ間の微妙な区別を理解できるようになります。メモリ統合
入力を分類する際に会話履歴を含めるためにメモリを有効にします。これにより、現在の入力が以前のコンテキストに依存する複数ターンの会話での精度が向上します。 メモリウィンドウは、含める会話履歴の量を制御しト認識とトークン効率および処理速度のバランスを取ります。出力使用
分類器は、一致したカテゴリラベルを含むclass_name変数を出力します。この変数を下流ノードで以下の用途に使用します:
条件分岐ルーティング - 分類結果に基づいて異なるワークフローパスに接続
知識ベース選択 - 各カテゴリ専用の知識ベースにルーティング
レスポンスカスタマイゼーション - 異なるレスポンステンプレートや処理ロジックを適用
分析とログ記録 - カテゴリ全体でのユーザー問い合わせの分布を追跡