

本文档由 AI 自动翻译。如有任何不准确之处,请参考 英文原版。变量赋值器节点通过写入会话变量(在这里了解不同类型的变量)来管理 Chatflow 应用中的持久化数据。与每次执行都会重置的常规工作流变量不同,会话变量在整个聊天会话期间持续存在。
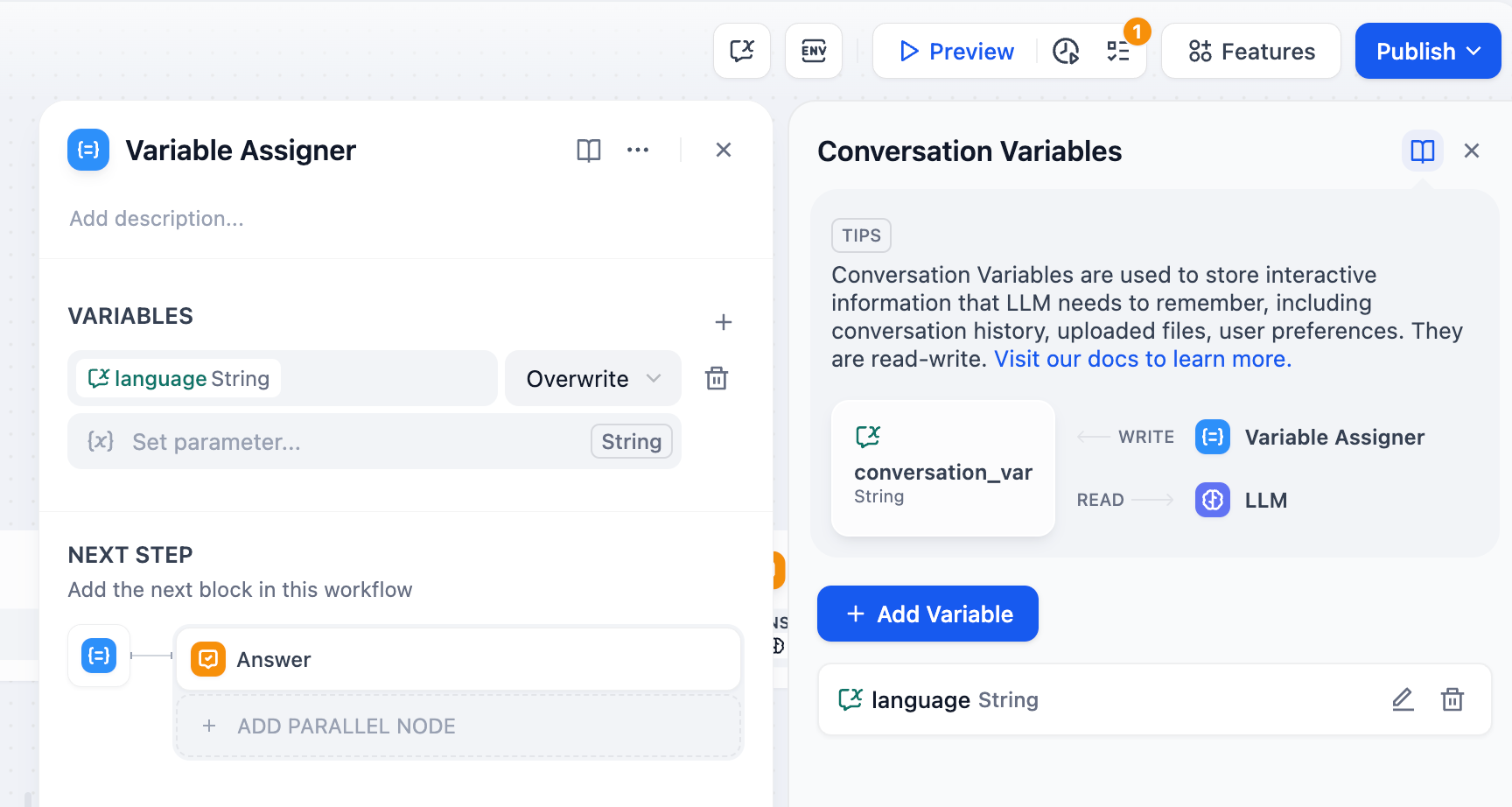
变量赋值器节点配置
会话变量 vs 工作流变量
工作流变量 仅在单次工作流执行期间存在,并在工作流完成时重置。 会话变量 在同一聊天会话中的多个对话轮次之间持续存在,支持有状态交互和上下文记忆。 这种持久性支持上下文对话、用户个性化、有状态工作流,以及跨多个用户交互的进度跟踪。配置
配置要更新的会话变量并指定其源数据。你可以在单个节点中分配多个变量。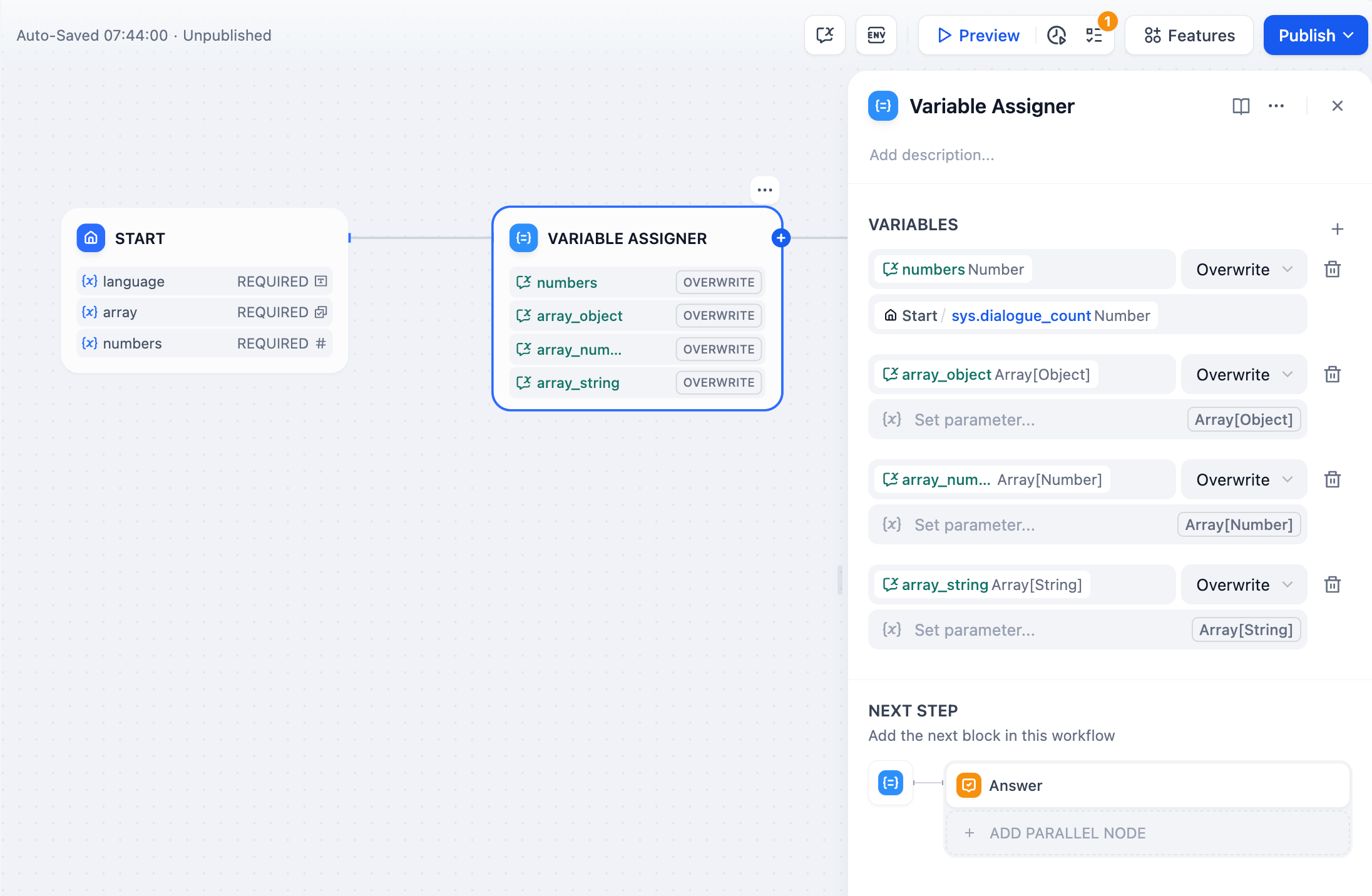
变量分配配置界面
操作模式
不同变量类型根据其数据结构支持不同的操作:- 字符串
- 数字
- 布尔值
- 对象
- 数组
- 覆写 - 用另一个字符串变量替换
- 清除 - 移除当前值
- 设置 - 手动分配一个固定值
常见实现模式
智能记忆系统
构建能够自动检测和存储对话中重要信息的聊天机器人: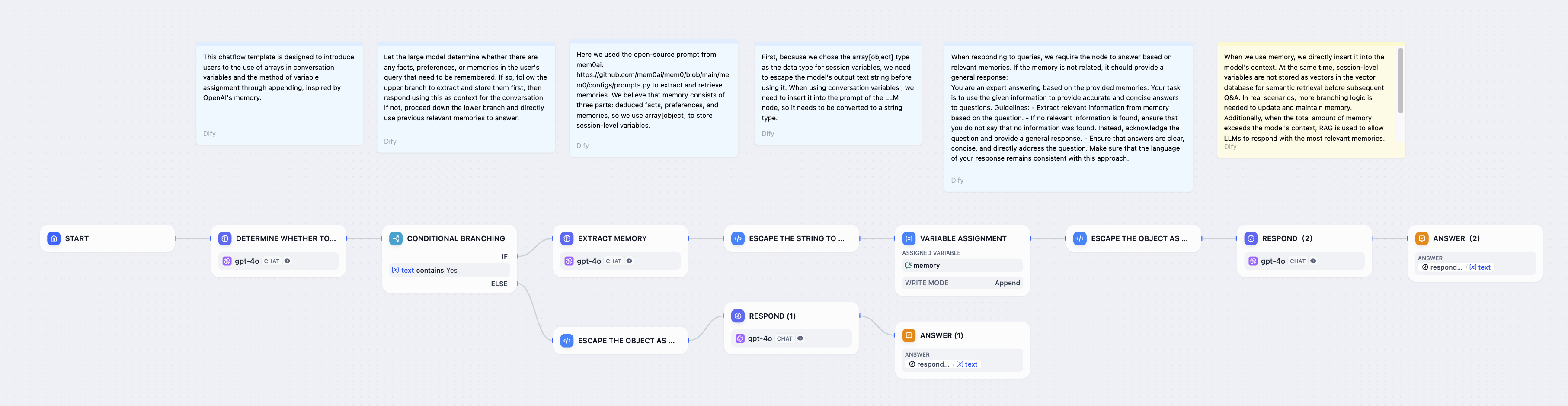
智能记忆系统工作流
用户偏好存储
存储用户偏好,如语言设置、通知偏好或显示选项: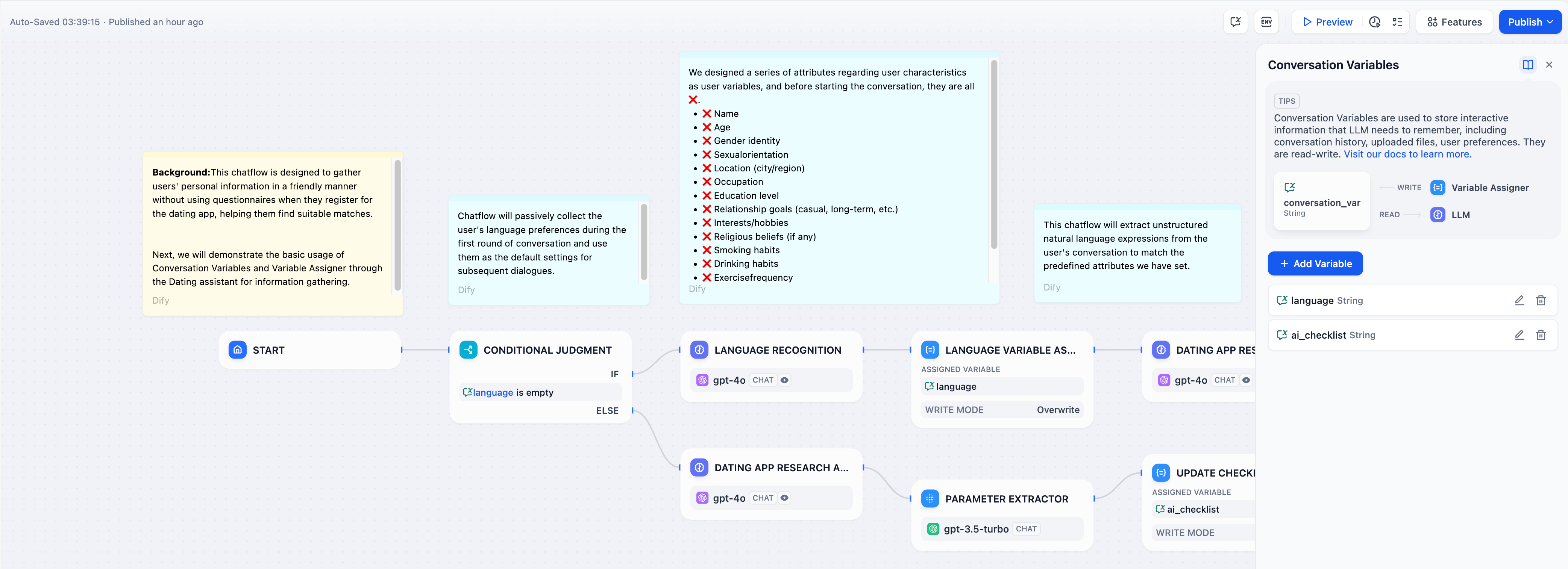
用户偏好管理
渐进式清单
构建跨多个对话轮次跟踪完成状态的引导式工作流: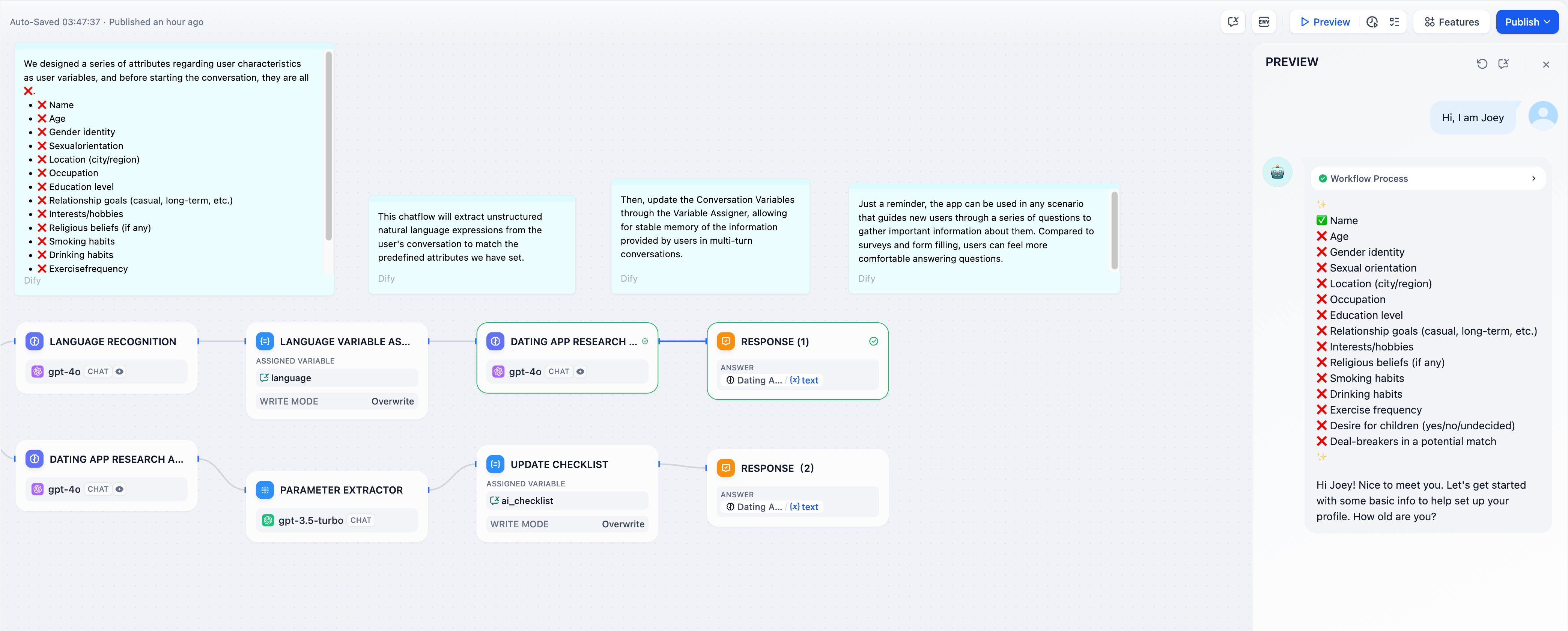
渐进式清单实现