

本文档由 AI 自动翻译。如有任何不准确之处,请参考 英文原版。大型语言模型节点调用语言模型来处理文本、图像和文档。它向你配置的模型发送提示词并捕获其响应,支持结构化输出、上下文管理和多模态输入。
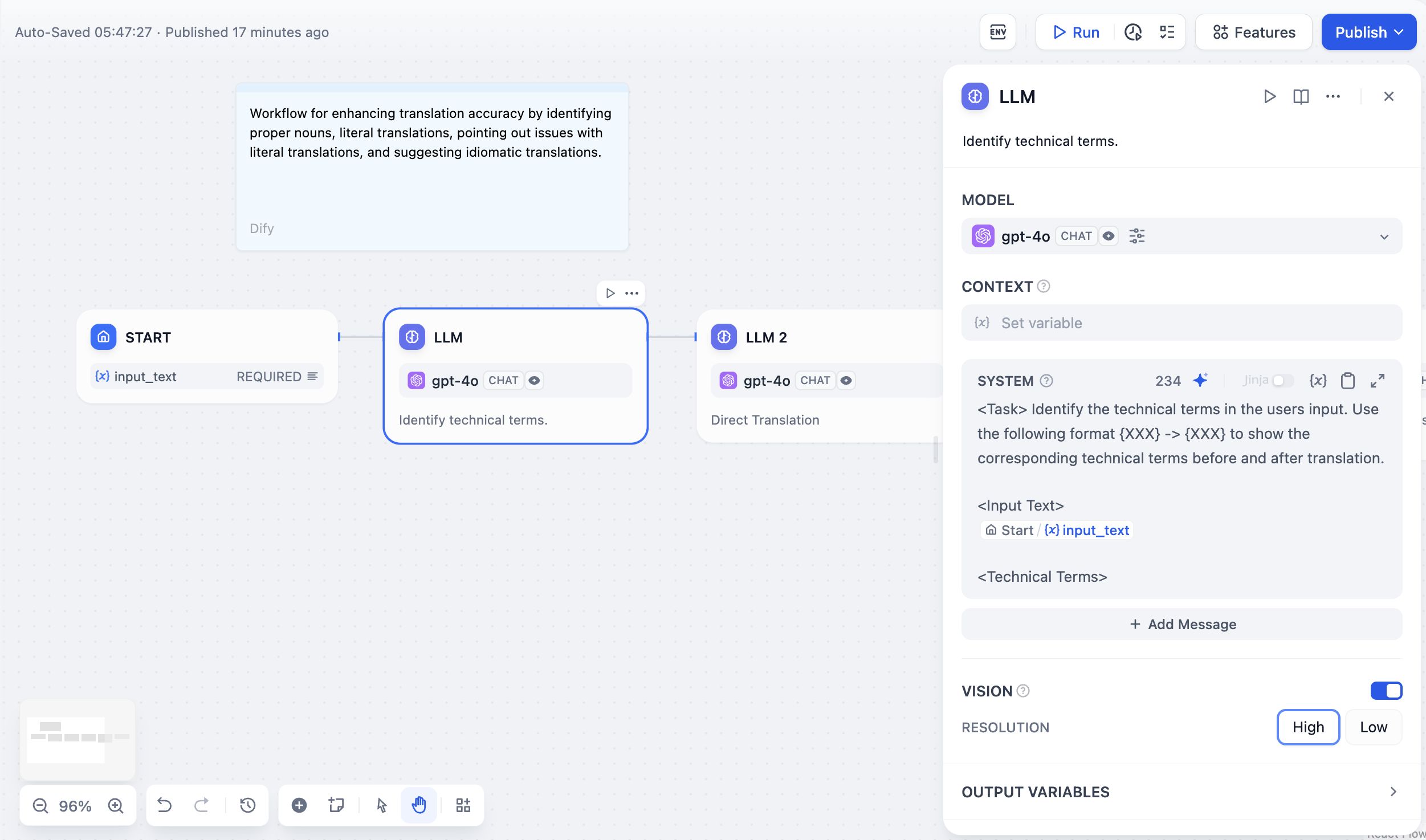
在使用大型语言模型节点之前,先在 集成 > 模型供应商 中配置至少一个模型供应商。
模型选择和参数
从你已配置的任何模型供应商中进行选择。不同模型擅长不同任务 - GPT-4 和 Claude 3.5 在复杂推理方面表现良好但成本较高,而 GPT-3.5 Turbo 在能力和经济性之间取得平衡。
提示词配置
你的界面根据模型类型自适应。聊天模型使用消息角色(系统 用于行为,用户 用于输入,助手 用于示例),而完成模型使用简单的文本续写。 在提示词中使用双花括号引用工作流变量:{{variable_name}}。变量在到达模型之前会被实际值替换。
上下文变量
上下文变量在保持来源归属的同时注入外部知识。这使得大型语言模型可以使用你的特定文档回答问题的检索增强生成应用成为可能。
结构化输出
强制模型返回特定数据格式(如 JSON)以便程序化使用。通过三种方法配置:- 可视化编辑器
- JSON Schema
- AI 生成
用户友好的界面适用于简单结构。添加具有名称和类型的字段,标记必需字段,设置描述。编辑器自动生成 JSON Schema。
记忆和文件处理
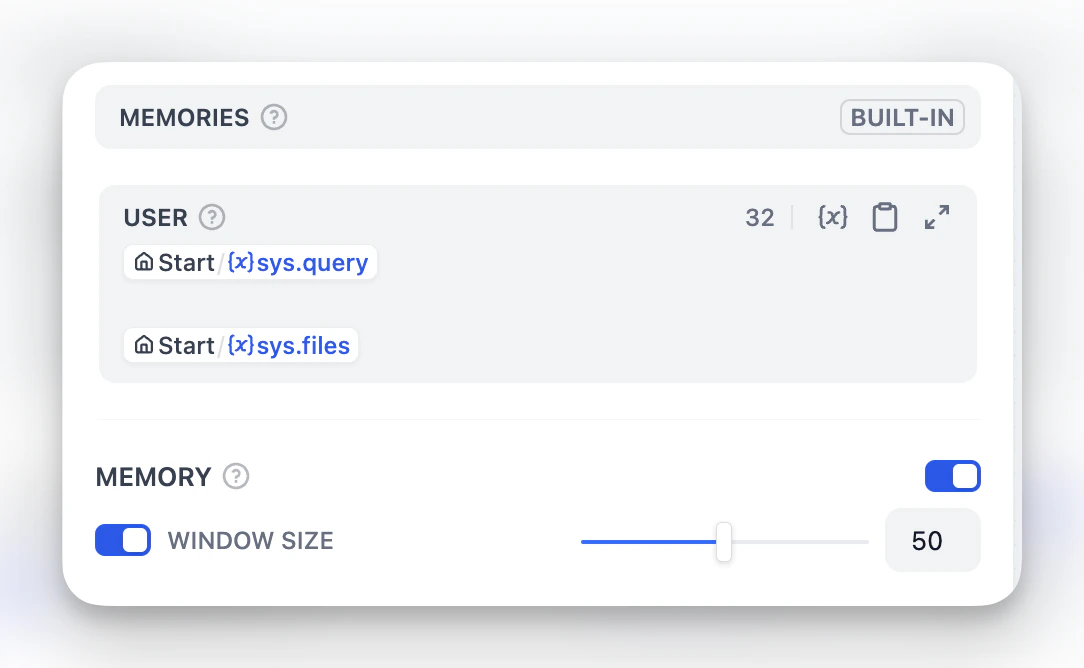
USER 模板来自定义用户提示词的内容。记忆是节点特定的,不会在不同对话之间持续存在。
对于 文件处理,将文件变量添加到多模态模型的提示词中。GPT-4V 处理图像,Claude 直接处理 PDF,而其他模型可能需要预处理。
视觉能力配置
处理图像时,你可以控制细节级别:- 高细节 - 对复杂图像具有更好的准确性但使用更多令牌
- 低细节 - 对简单图像进行更快处理,使用较少令牌
userinput.files,它会自动从用户输入节点获取文件。
Jinja2 模板支持
大型语言模型提示词支持 Jinja2 模板以进行高级变量处理。当你使用 Jinja2 模式(edition_type: "jinja2")时,你可以:
流式结果返回
大型语言模型节点默认支持流式结果返回。每个文本块都作为RunStreamChunkEvent 产生,实现实时响应显示。文件输出(图像、文档)在流式传输期间自动处理和保存。
从回答中分离推理内容
部分推理模型会用<think>...</think> 标签包裹思考过程。默认情况下,这些标签保留在 text 输出中,推理内容随回答一起传递到下游节点。
打开 启用推理标签分离 开关即可将两者分开:text 输出仅保留回答,思考过程则移至独立的 reasoning_content 输出变量。开关关闭时,reasoning_content 为空。
在 API 调用中,该开关对应 reasoning_format 参数。开关打开时,reasoning_format 为 separated,流式 API 客户端会通过独立的 reasoning_chunk 事件接收推理内容,与回答流分开。事件详情参见 发送对话消息 和 执行工作流。
此设置仅对用
<think> 标签包裹推理内容的模型生效。