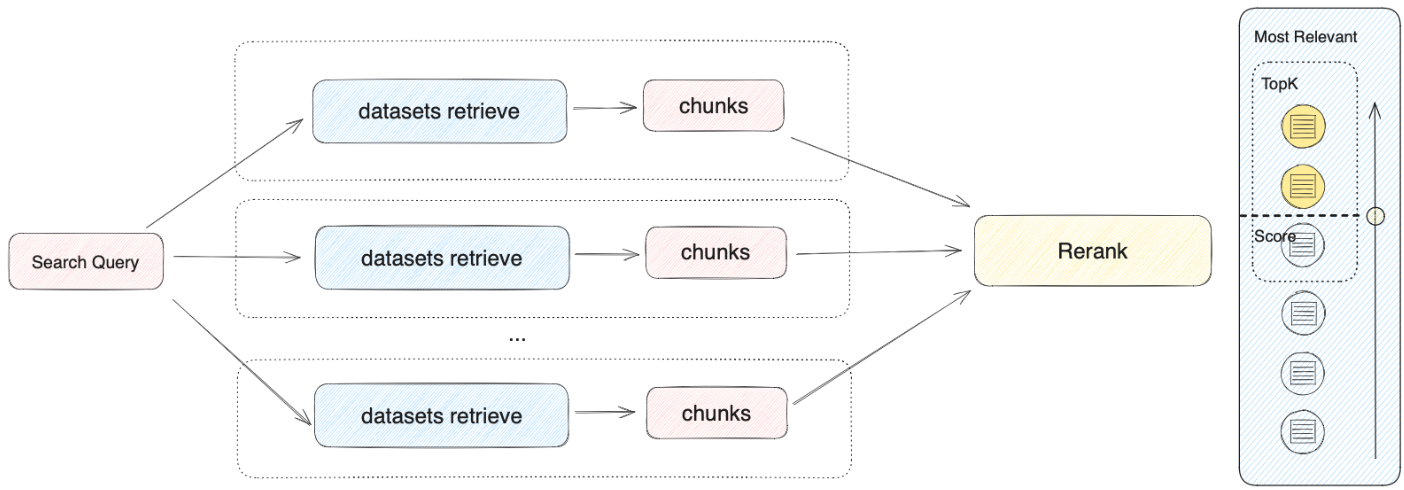
| 文字列 | is | フィールドの値は入力した値と完全に一致する必要があります。例えば、フィルタリング条件を is "公開済み" に設定した場合、「公開済み」とマークされた文書のみが返されます。 |
| is not | フィールドの値は入力した値と一致してはいけません。例えば、フィルタリング条件を is not "下書き" に設定した場合、「下書き」とマークされていないすべての文書が返されます。 | |
| is empty | フィールドの値が空です。この条件を設定すると、その文字列がマークされていない文書を検索できます。 | |
| is not empty | フィールドの値が空ではありません。この条件を設定すると、その文字列がマークされている文書を検索できます。 | |
| contains | フィールドの値に入力したテキストが含まれています。例えば、フィルタリング条件を contains "レポート" に設定した場合、「月次レポート」や「年次レポート」など、「レポート」を含むすべての文書が返されます。 | |
| not contains | フィールドの値に入力したテキストが含まれていません。例えば、フィルタリング条件を not contains "下書き" に設定した場合、「下書き」を含まないすべての文書が返されます。 | |
| starts with | フィールドの値が入力したテキストで始まります。例えば、フィルタリング条件を starts with "Doc" に設定した場合、「Doc1」や「Document」など、「Doc」で始まるすべての文書が返されます。 | |
| ends with | フィールドの値が入力したテキストで終わります。例えば、フィルタリング条件を ends with "2024" に設定した場合、「レポート 2024」や「概要 2024」など、「2024」で終わるすべての文書が返されます。 | |
| 数値 | = | フィールドの値は入力した数値と等しい必要があります。例えば、= 10 は数値が 10 とマークされているすべての文書に一致します。 |
| ≠ | フィールドの値は入力した数値と等しくてはいけません。例えば、≠ 5 は数値が 5 とマークされていないすべての文書を返します。 | |
| > | フィールドの値は入力した数値より大きい必要があります。例えば、> 100 は数値が 100 より大きいとマークされているすべての文書を返します。 | |
| < | フィールドの値は入力した数値より小さい必要があります。例えば、< 50 は数値が 50 より小さいとマークされているすべての文書を返します。 | |
| ≥ | フィールドの値は入力した数値以上である必要があります。例えば、≥ 20 は数値が 20 以上とマークされているすべての文書を返します。 | |
| ≤ | フィールドの値は入力した数値以下である必要があります。例えば、≤ 200 は数値が 200 以下とマークされているすべての文書を返します。 | |
| is empty | フィールドに値が設定されていません。例えば、is empty はそのフィールドに数値がマークされていないすべての文書を返します。 | |
| is not empty | フィールドに値が設定されています。例えば、is not empty はそのフィールドに数値がマークされているすべての文書を返します。 | |
| 時間 | is | フィールドの時間値は選択した時間と完全に一致する必要があります。例えば、is "2024-01-01" は 2024 年 1 月 1 日とマークされている文書のみを返します。 |
| before | フィールドの時間値は選択した時間より前でなければなりません。例えば、before "2024-01-01" は 2024 年 1 月 1 日より前とマークされているすべての文書を返します。 | |
| after | フィールドの時間値は選択した時間より後でなければなりません。例えば、after "2024-01-01" は 2024 年 1 月 1 日より後とマークされているすべての文書を返します。 | |
| is empty | フィールドの時間値が空です。この条件を設定すると、時間がマークされていない文書を検索できます。 | |
| is not empty | フィールドの時間値が空ではありません。この条件を設定すると、時間がマークされている文書を検索できます。 | |