

モデルの統合
GPUStackによってデプロイされたローカルモデルの統合
GPUStackは、AIモデルを実行するために設計されたオープンソースのGPUクラスターマネージャーです。
Difyは、大規模言語モデルの推論、埋め込み、再順位付け機能をローカル環境で展開するために、GPUStackとの統合を実現しています。
その後、表示される指示に従ってGPUStackのUIにアクセスできます。
 GPUStackに関する詳細情報は、GitHub Repoを参照してください。
GPUStackに関する詳細情報は、GitHub Repoを参照してください。
このページを編集する | 問題を報告する
GPUStackの展開方法
GPUStackを展開する際は、公式のドキュメントを参照するか、以下の手順に従って簡単に統合できます。LinuxまたはMacOSでの展開
GPUStackは、systemdやlaunchdベースのシステムにサービスとしてインストールするためのスクリプトを提供しています。この方法でGPUStackをインストールするには、次のコマンドを実行してください:Windowsでの展開
管理者としてPowerShellを実行し(PowerShell ISEは使用しないでください)、次のコマンドを実行してGPUStackをインストールします:LLMの展開手順
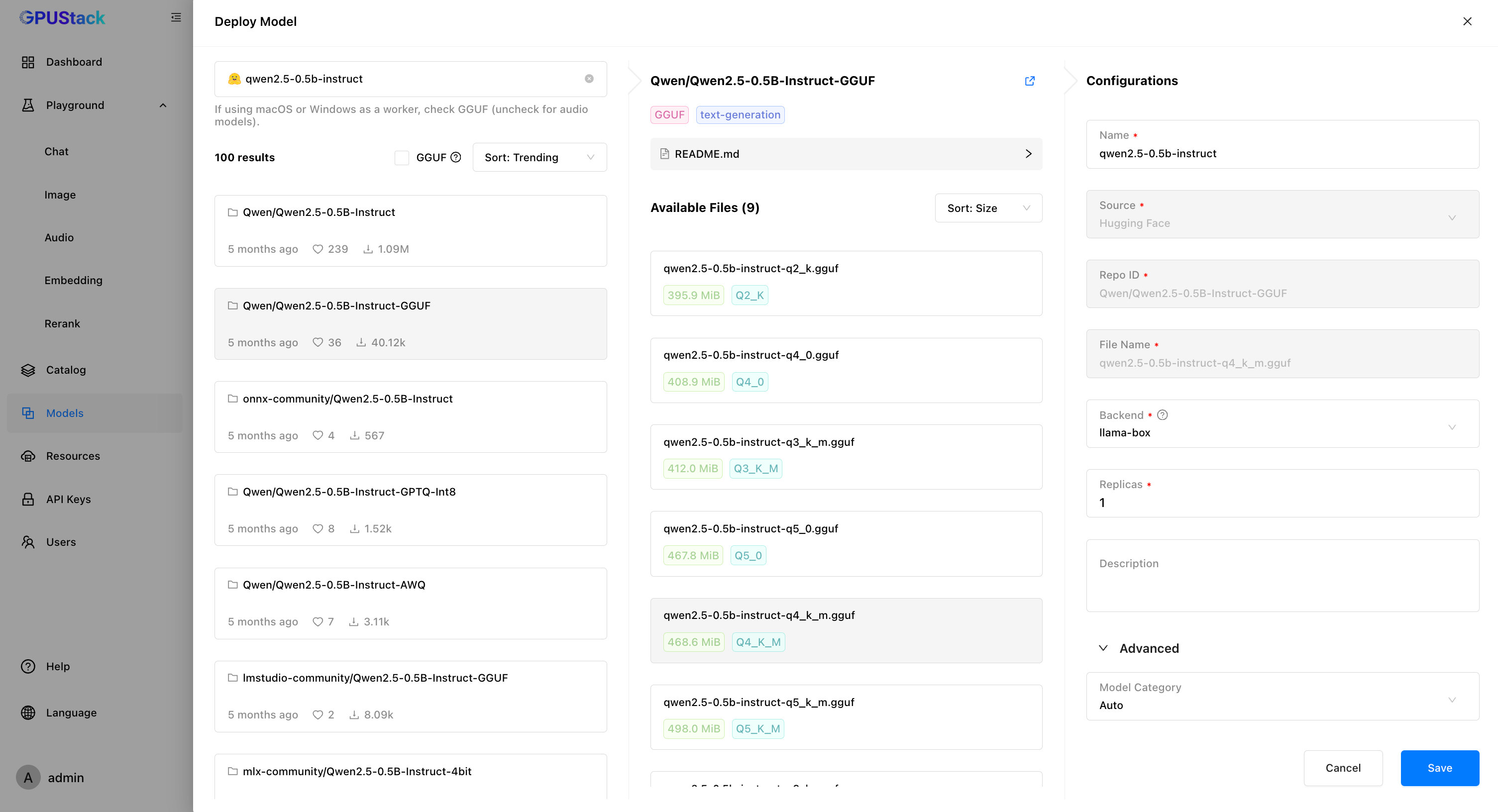
GPUStackにホストされたLLMを使用する方法の例です:- GPUStack UIで「Models」ページに移動し、「Deploy Model」をクリック、次に「Hugging Face」をドロップダウンメニューから選択します。
- 左上の検索バーを使って、モデル名「Qwen/Qwen2.5-0.5B-Instruct-GGUF」を検索します。
- モデルを展開するために「Save」をクリックします。
APIキーの作成方法
- 「API Keys」ページに移動し、「New API Key」をクリックします。
- 名前を入力し、「Save」をクリックします。
- APIキーをコピーし、後で使用するために保存しておきます。
DifyとGPUStackの統合手順
-
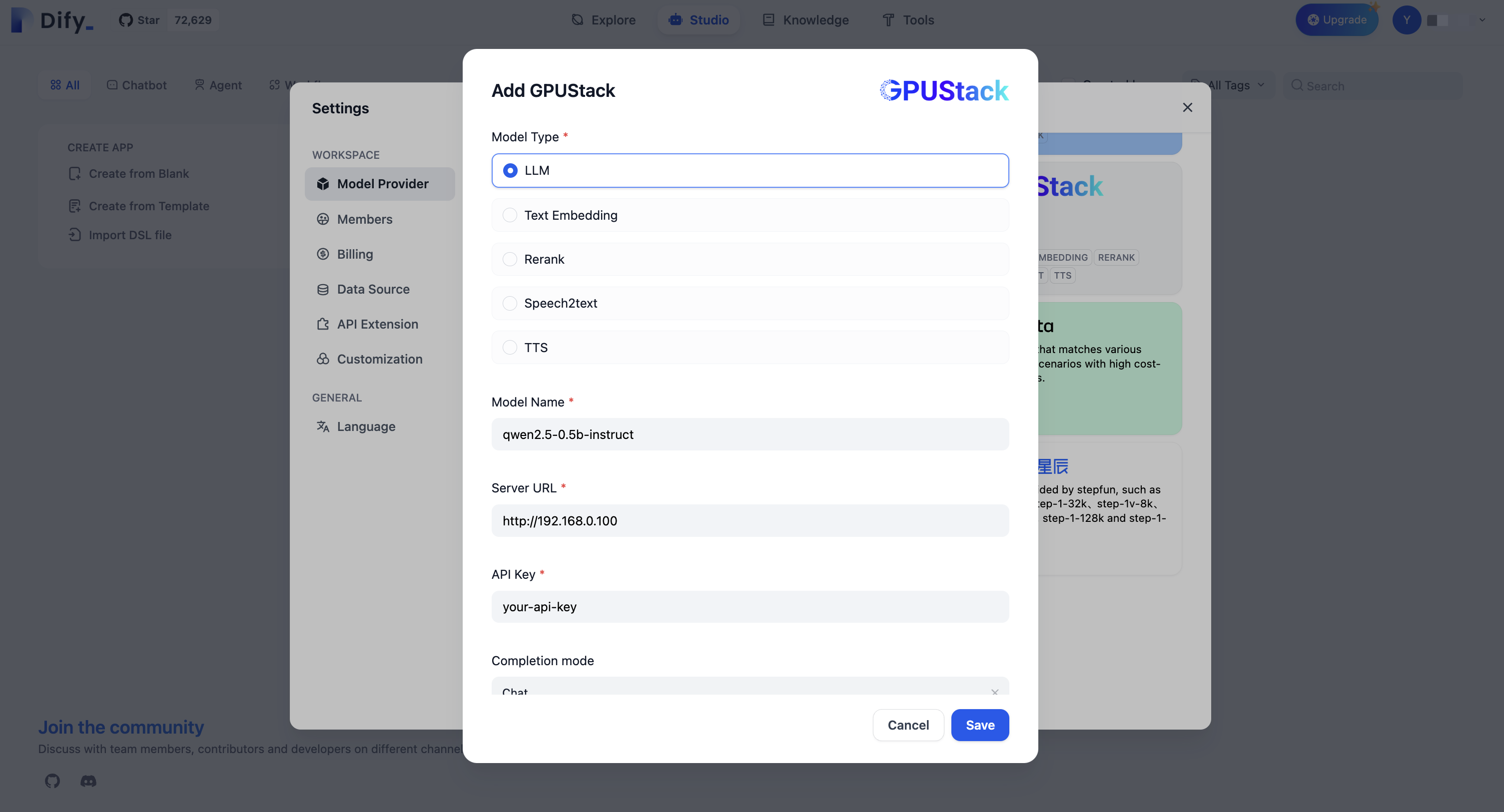
Settings > Model Providers > GPUStackに移動し、以下の情報を入力します:-
モデルタイプ:
LLM -
モデル名:
qwen2.5-0.5b-instruct -
サーバーURL:
http://your-gpustack-server-ip -
APIキー:
コピーしたAPIキーを入力
-
モデルタイプ:
GPUStackに関する詳細情報は、GitHub Repoを参照してください。
このページを編集する | 問題を報告する