このドキュメントは AI によって自動翻訳されています。不正確な部分がある場合は、英語版 を参照してください。工場の生産ラインを例に考えてみましょう。各ステーション(ノード)が特定の作業を担当し、それらを連携させて部品を組み立て、最終製品を完成させます。ナレッジパイプラインの構築も同様のプロセスです。視覚的なワークフロー設計ツールを使用し、ドラッグ&ドロップ操作だけで容易にデータ処理の流れを設計できます。これにより、ドキュメントの取り込み、処理、分割、インデックス化、検索戦略を自在に管理できます。 本ステップでは、ナレッジパイプライン全体のプロセス、各ノードの役割や設定方法について学び、独自のデータ処理フローをカスタマイズして、効率的にナレッジベースを管理・最適化する方法を解説します。
インターフェースの状態
オーケストレーションキャンバスに入ると、次の状態を確認できます。- タブの状態: 「Documents(ドキュメント)」「Retrieval Test(検索テスト)」「Settings(設定)」タブはグレーアウトされ利用不可です。
- 必要ステップ:パイプラインのオーケストレーションと公開が完了しないと、ファイルアップロードやその他機能は利用できません。
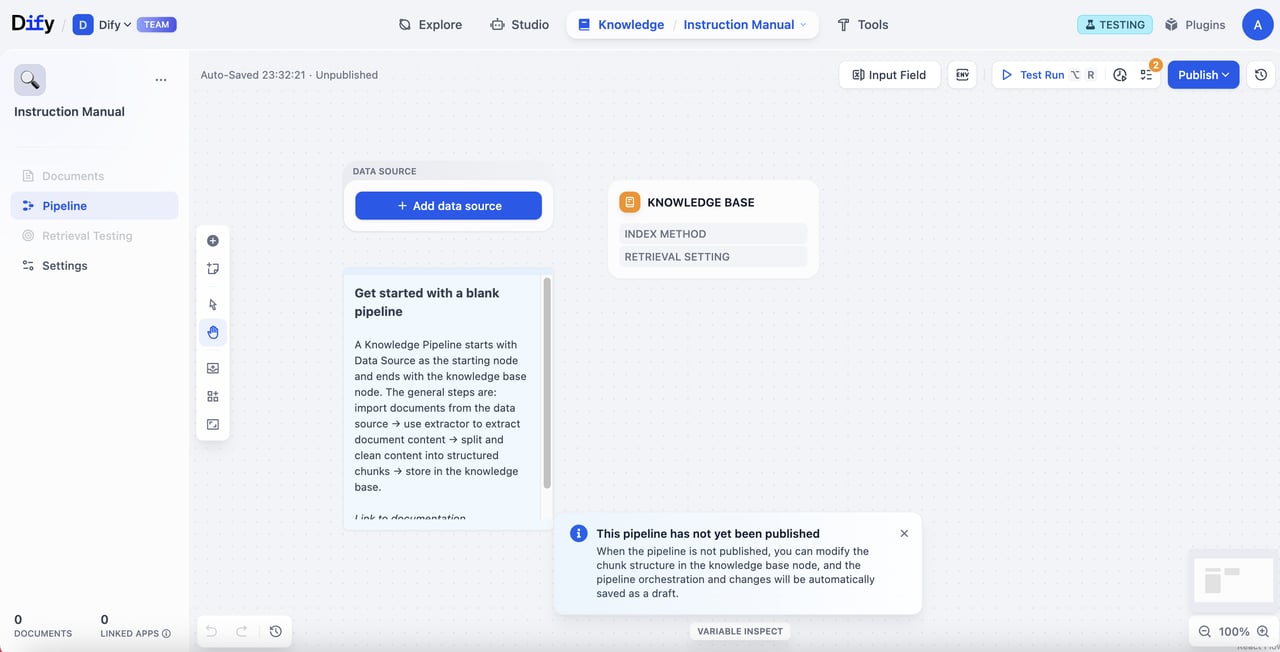
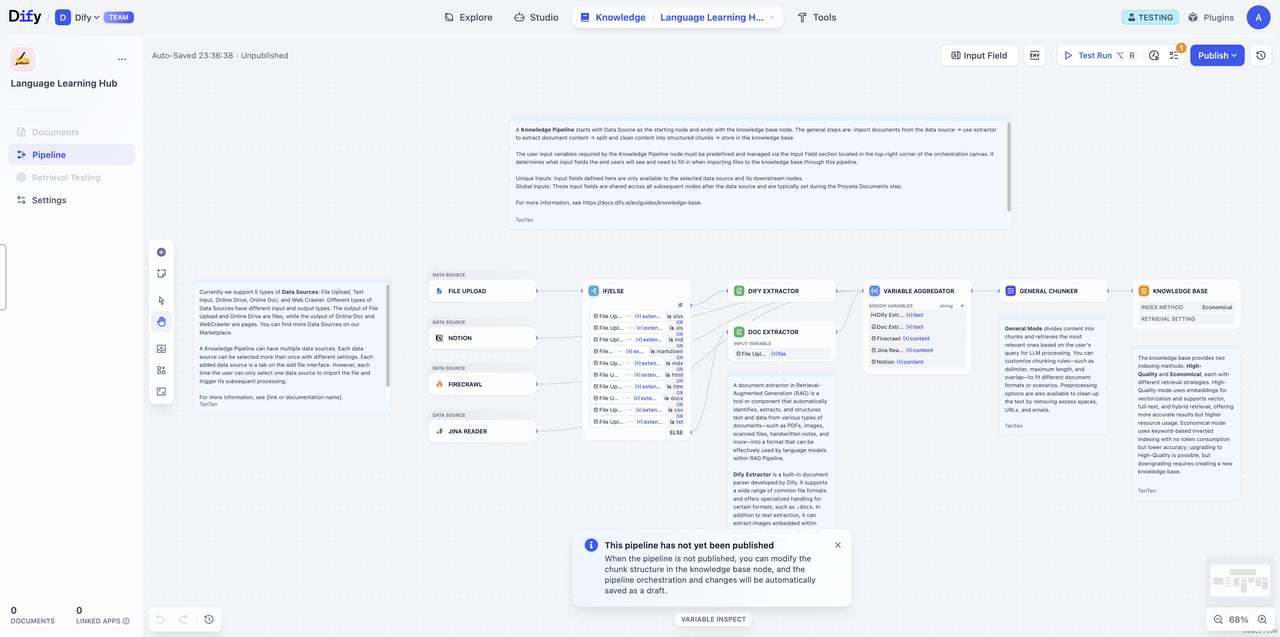
ナレッジパイプラインの全体プロセス
まず、ナレッジパイプラインにおける処理プロセスを分解し、ドキュメントがどのように検索可能なナレッジベースへと変換されるのかを理解しましょう。 ナレッジパイプラインは、以下の主要なステップから構成されます:- データソース:さまざまな情報源(ローカルファイル、Notion、Web ページなど)からのコンテンツ
- データ処理:データ内容の加工と変換
- 抽出器(Extractor):ドキュメントの解析・構造化
- 分割器(Chunker):構造化された内容を扱いやすい断片に分割
- ナレッジベース:分割構造と検索設定の構築
- ユーザー入力フォーム:ユーザーがパイプライン実行時に必要なパラメータや情報を入力するための定義
- テスト&公開:設定の検証および運用開始
ステップ 1:データソースの設定
ナレッジベースには、単一または複数のデータソースを選択できます。現在、Dify では主に 4 種類のデータソースをサポートしています:ファイルアップロード、クラウドストレージ、オンラインドキュメント、Web クローラー。 さらに多様なデータソースについては、Dify Marketplaceをご参照ください。ファイルアップロード
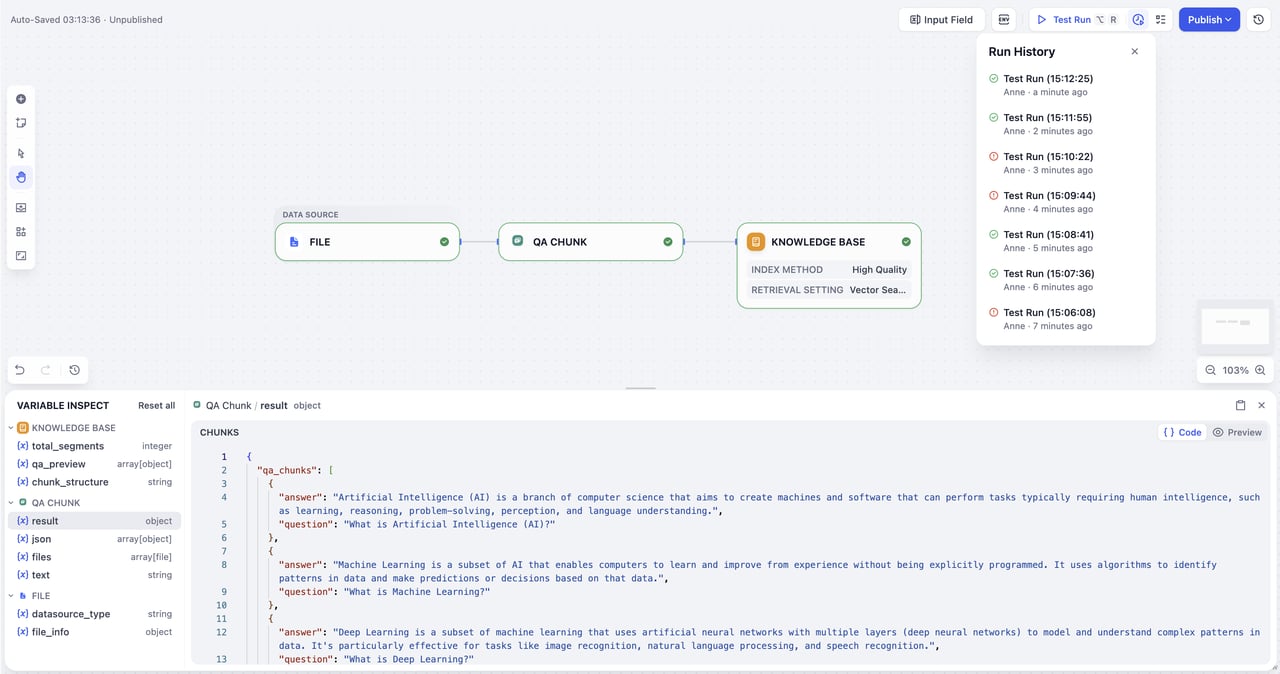
ローカルファイルはドラッグ&ドロップまたはファイル選択でアップロードできます。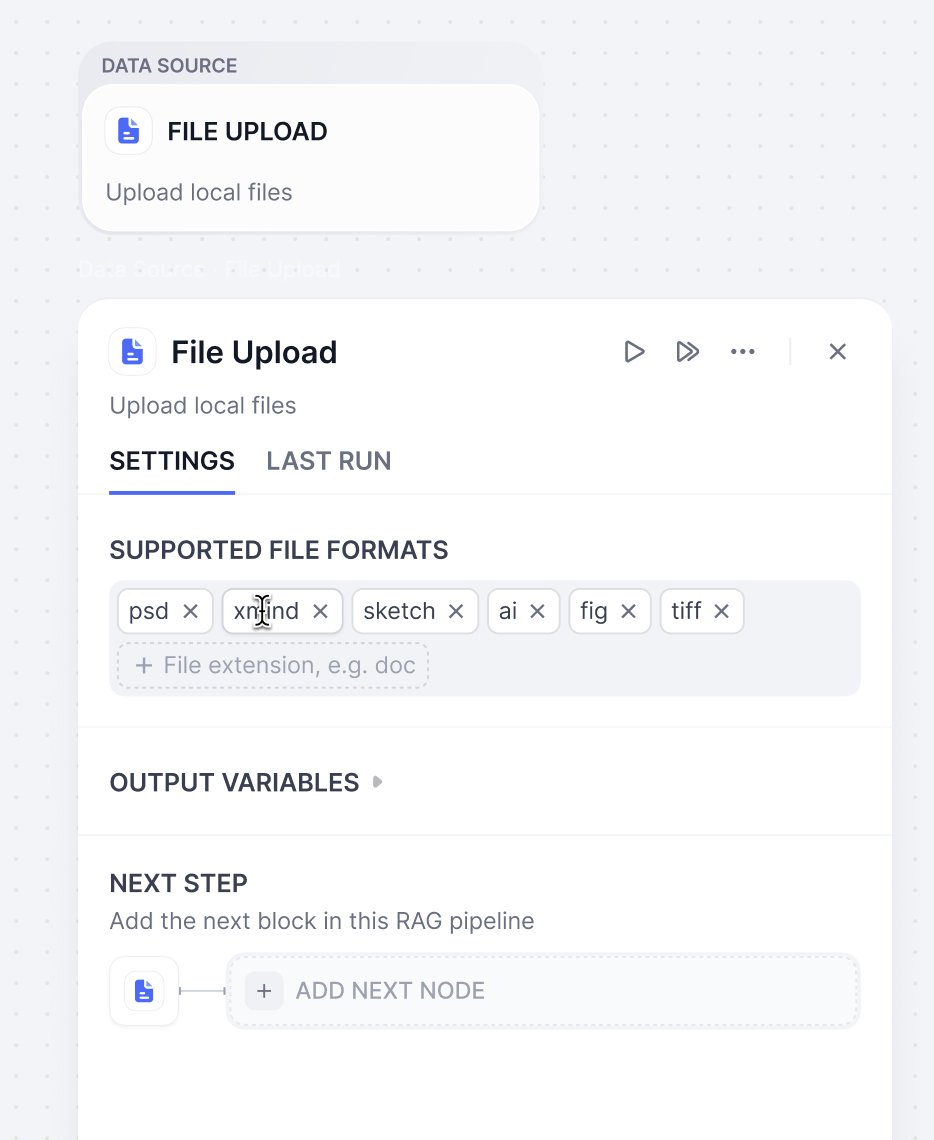
設定オプション
制限事項
出力変数
オンラインドキュメント
Notion
Notion ワークスペースと連携し、ページやデータベースをシームレスにインポート可能です。ナレッジベースは常に自動で最新状態に保たれます。
設定オプション
Web クローラー
Web コンテンツを大規模言語モデルでも読みやすい形式に変換します。ナレッジベースは Jina Reader と Firecrawl をサポートしています。Jina Reader
シンプルかつ使いやすい API を提供するオープンソースの Web 解析ツールです。Web コンテンツの高速クロールと処理に適しています。
パラメータ設定
Firecrawl
きめ細かなクロール制御オプションと API サービスを持つオープンソースの Web 解析ツールです。複雑なサイトの深層クロールやバッチ処理に適しています。
パラメータ設定
クラウドストレージ
Google Drive、Dropbox、OneDrive などのクラウドストレージサービスと連携し、Dify が自動でファイルを取得します。選択したドキュメントをインポートするだけなので、事前の手動ダウンロードは不要です。ステップ 2:データ処理ツールの設定
このステップでは、コンテンツの抽出、分割、最適なナレッジベース用フォーマットへの変換を行います。これは、料理でいう「食材の下準備」と同じく、後に素早く加工できる状態を整える工程です。ドキュメントプロセッサ
PDF、XLSX、DOCX など多様な形式のドキュメントが存在しますが、LLM はこれらをそのまま扱えません。そのため、抽出器(Extractor)が各種ファイルを解析・変換し、LLM が扱いやすい形式に変換します。 Dify のテキスト抽出ノード、あるいは Marketplace から「Dify Extractor」「Unstructured」等のツールを選択できます。ドキュメント内の画像
ドキュメント内の画像
ドキュメント内の画像は、適切なドキュメントプロセッサを使用して抽出できます。抽出された画像は対応するチャンクに添付され、個別に管理でき、検索時にはそのチャンクと一緒に返されます。抽出された画像の URL はチャンクテキスト内に残りますが、テキストをクリーンに保つためにこれらの URL を安全に削除できます。これは抽出された画像には影響しません。各チャンクには最大 10 枚まで画像を添付できます。これを超える画像は抽出されません。選択したプロセッサで画像が抽出されなかった場合、Dify は以下の Markdown 記法でアクセス可能な URL が参照されている 2MB 未満の JPG、JPEG、PNG、GIF 画像を自動的に抽出します:

Doc Extractor(テキスト抽出)

Dify Extractor
Dify Extractor は、Dify が提供する内蔵ドキュメント解析ツールです。一般的なファイル形式に幅広く対応し、特に Doc ファイルに最適化されています。画像抽出・保存や、画像 URL 返却も可能です。
Unstructured
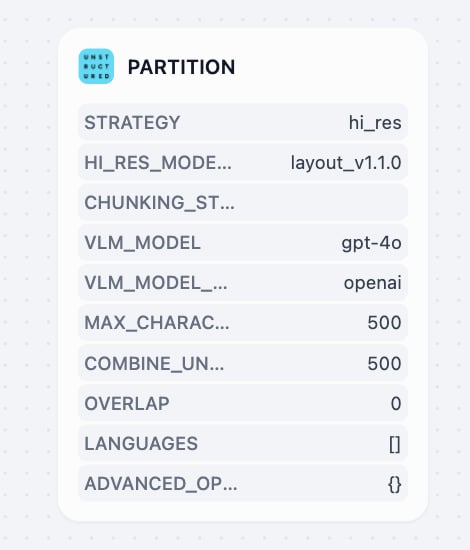
Unstructured は、高度なカスタマイズ可能性を備えた抽出戦略でドキュメントを機械可読形式へ変換します。抽出戦略(auto、hi_res、fast、OCR-only)や分割方法(by_title、by_page、by_similarity)に柔軟に対応。要素ごとの座標や信頼度、レイアウトなどリッチなメタデータも出力し、企業のドキュメントワークフローや混合タイプファイルの精密な処理に適しています。
分割器(Chunker)
人間が一度に多くの情報を集中して理解できないように、LLM も大量情報の同時処理が苦手です。そのため、分割器は抽出後のドキュメントを小さな「チャンク」と呼ばれる断片に分割します。 用途やドキュメントの種類に応じ、最適な分割戦略が異なります。たとえば製品マニュアルは機能ごと、論文は論理セクションごとが理想的です。Dify では主に 3 種類の分割器を用意しています。分割器の種類概要
共通テキスト前処理ルール
すべての分割器で利用できるテキストクリーニングオプション:汎用分割器(General Chunker)
シンプルな構造の文書向けの基本的な分割モジュールです。テキスト分割や前処理オプションを柔軟にカスタマイズ可能です。 入力と出力変数
分割設定
親子分割器(Parent-child Chunker)
クエリマッチング精度と豊富なコンテキスト両立のため、二層チャンク構造を採用し、RAG システムにおけるコンテキストと精度の矛盾を解決します。 親子分割器の仕組み- 子チャンク(高精度マッチング用):ユーザーのクエリに高精度でマッチングするための小さく精密な情報セグメント(通常、1 文ごと)
- 親チャンク(豊富なコンテキスト):該当する子チャンクを含む広い範囲のコンテンツブロック(段落、セクション、またはドキュメント全体)で、大規模言語モデル(LLM)に包括的な背景情報を提供
分割設定
Q&A プロセッサ
抽出&分割を 1 ノードで実施。FAQ や Q&A ペアをテーブルとして持つ CSV/Excel ファイル専用です。 入出力変数
変数設定
ステップ 3:ナレッジベースノードの設定
ドキュメントの処理・分割が完了したら、保存や検索の方法を設定します。ここでは、インデックス作成方法や検索戦略を用途に応じて選択可能です。 本ノードの設定項目は、入力変数、チャンク構造、インデックス方式、検索設定となります。チャンク構造
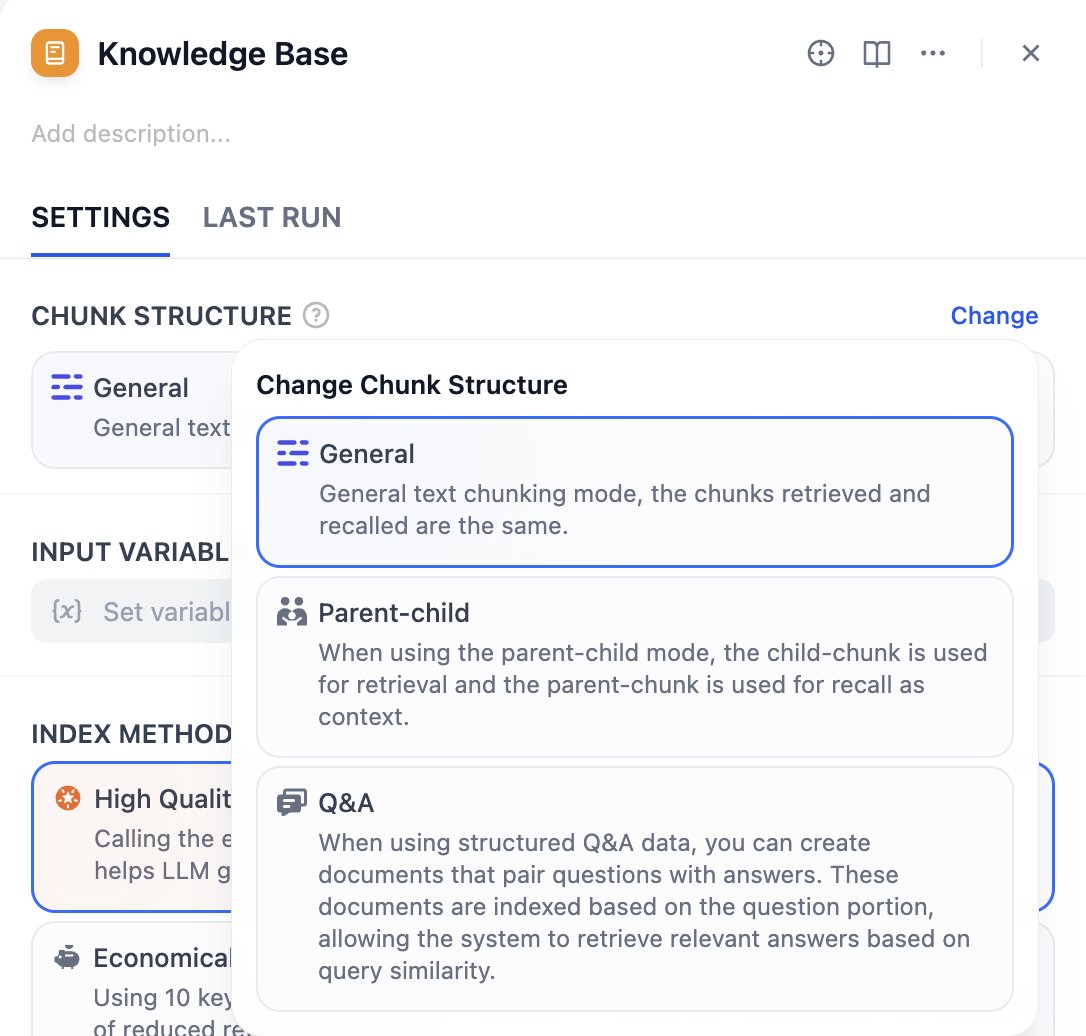
汎用モード
標準的なドキュメント処理に最適です。柔軟なインデックスオプションを提供し、品質やコストの異なる要件に応じて適切なインデックス方法を選択できます。 汎用モードは高品質とコスト効率の両方のインデックス方法、および各種検索設定をサポートします。親子モード
検索時の高精度マッチングと対応するコンテキスト情報を提供し、完全なコンテキストを維持する必要がある専門ドキュメントに適しています。 親子モードは HQ(高品質)モードのみ対応で、クエリマッチング用の子チャンクと検索時のコンテキスト情報用の親チャンクを提供します。Q&A モード
構造化された質問回答データを使用する際に、質問と回答をペアにしたドキュメントを作成します。これらのドキュメントは質問部分に基づいてインデックス化され、クエリの類似性に基づいて関連する回答を検索できます。 Q&A モードは HQ(高品質)モードのみ対応です。入力変数
入力変数はデータ処理ノードからの処理結果をナレッジベースのデータソースとして受け取ります。分割器の出力をナレッジベースノードへ入力として接続する必要があります。 ノードは選択したチャンク構造に基づいて異なるタイプの標準入力をサポートします:- 汎用モード:x Array[Chunk] - 汎用チャンク配列
- 親子モード:x Array[ParentChunk] - 親チャンク配列
- Q&A モード:x Array[QAChunk] - Q&A チャンク配列
インデックス方法と検索設定
インデックス方法はナレッジベース内のコンテンツインデックスの構築方法を決定し、検索設定は選択したインデックス方法に基づいた対応する検索戦略を提供します。 つまり、インデックス方法はドキュメントの整理方法を決定し、検索設定はユーザーがドキュメントを見つけるために使用できる方法を指定します。 ナレッジベースでは 高品質 と コスト効率 の 2 つのインデックス方法があり、それぞれ異なる検索設定オプションを提供します。 高品質モード では、埋め込みモデルを使用してチャンクを数値ベクトルに変換し、大量の情報をより効果的に圧縮・保存できます。これにより、ユーザーの質問の言い回しがドキュメントと完全に一致しなくても、意味的に関連する正確な回答をシステムが見つけることができます。クロスモーダル検索(テキストと画像を意味的関連性に基づいて取得)を有効にするには、Vision アイコン付きのマルチモーダル埋め込みモデルを選択してください。ドキュメントから抽出された画像も埋め込み・インデックス化され、検索対象となります。このような埋め込みモデルを使用するナレッジベースは、カード上で Multimodal と表示されます。
詳細は インデックス方法と検索設定を指定 をご参照ください。
選択した埋め込みモデルがマルチモーダルの場合は、Vision アイコンが表示されたマルチモーダルリランキングモデルも選択してください。そうでない場合、検索された画像は再ランクおよび検索結果から除外されます。
ステップ 4:ユーザー入力フォームの作成
ユーザー入力フォームは、パイプラインを効果的に実行するために必要な初期情報を収集するために不可欠です。ワークフローのユーザー入力ノードと同様に、このフォームはユーザーから必要な詳細情報(アップロードするファイル、ドキュメント処理の特定パラメータなど)を収集し、パイプラインが正確な結果を提供するために必要なすべての情報を確保します。 これにより、さまざまなユースケースシナリオに特化した入力フォームを作成でき、さまざまなデータソースやドキュメント処理ステップに対するパイプラインの柔軟性と使いやすさを向上できます。フォームの作成方法
ユーザー入力フィールドを作成する方法は 2 つあります:-
パイプライン構築インターフェース
入力フィールド をクリックして入力フォームの作成と設定を開始します。\
-
ノードパラメータパネル
ノードを選択します。次に、右側パネルのパラメータ入力で、新しい入力項目のために「+ ユーザー入力を作成」をクリックします。新しい入力項目は入力フィールドにも収集されます。
ユーザー入力フィールドの追加
各エントランス固有の入力
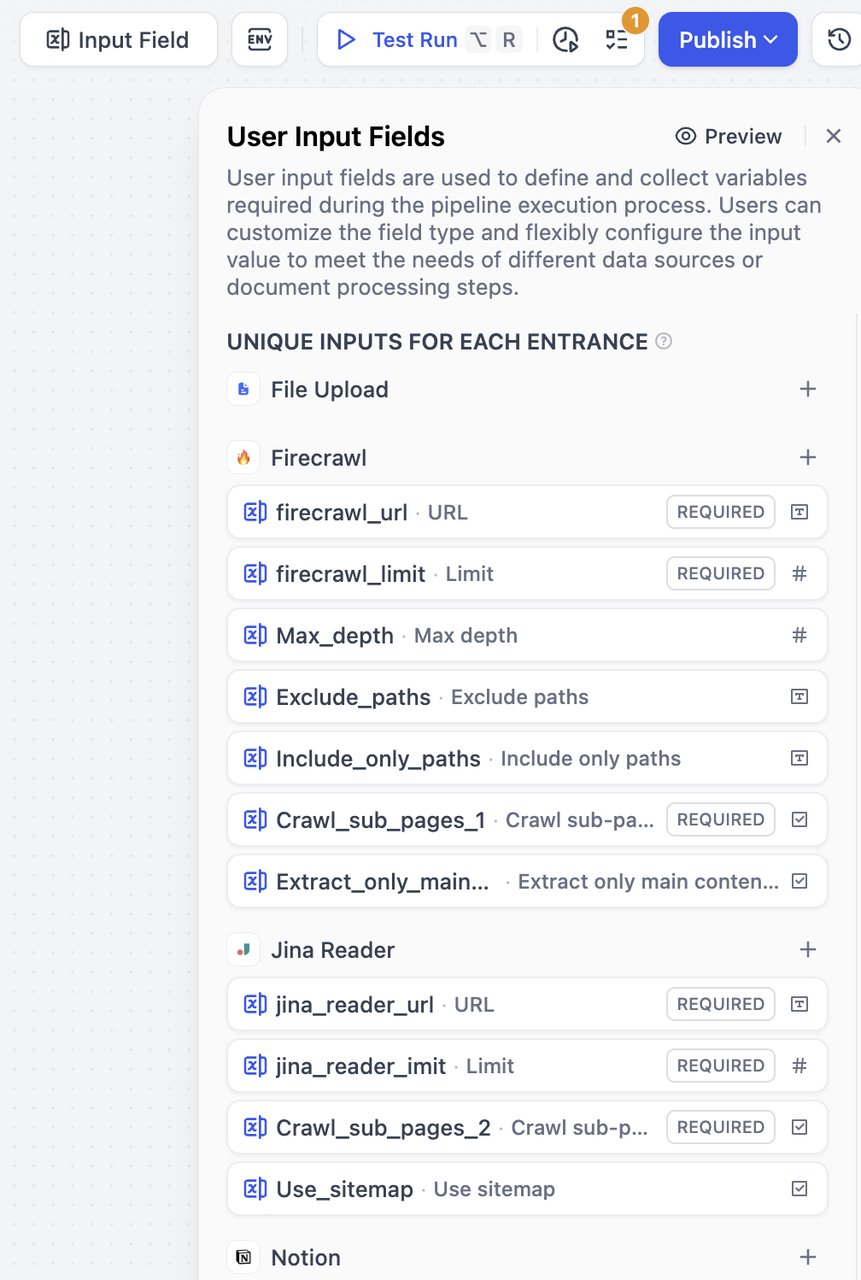
+ボタンをクリックして、その特定のデータソース用のフィールドを追加します。これらのフィールドは、そのデータソースとその後続の接続ノードからのみ参照できます。
すべてのエントランス用のグローバル入力
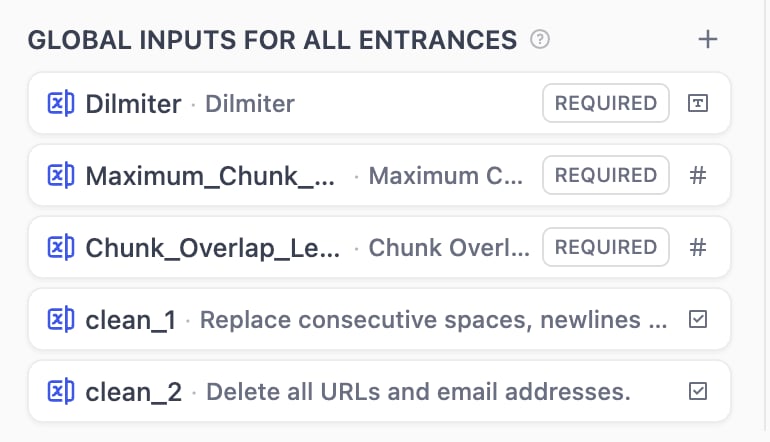
+ボタンをクリックして、任意のノードから参照できるフィールドを追加します。
サポートされる入力フィールドタイプ
ナレッジパイプラインは 7 種類の入力変数をサポートします: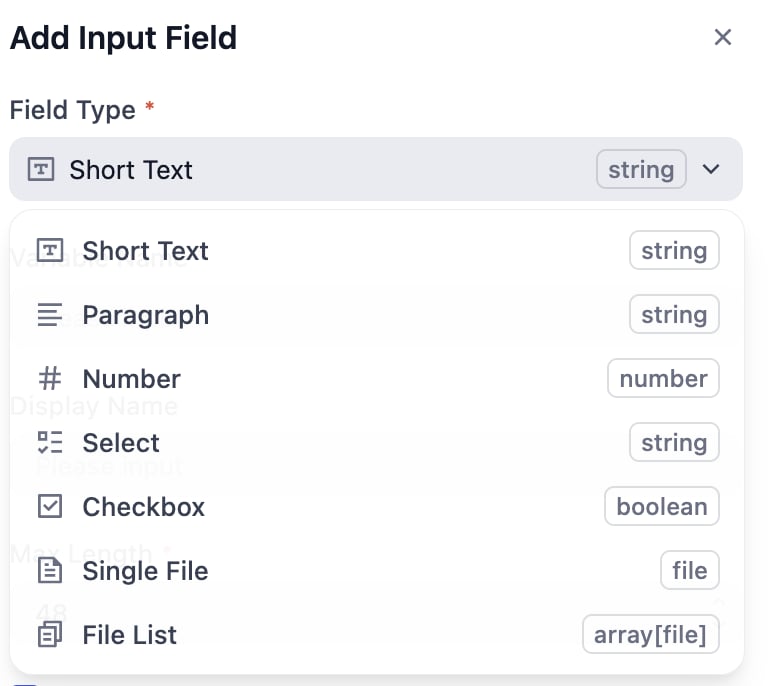
フィールド設定オプション
すべての入力フィールドタイプには、必須、任意、および追加設定があります。適切なオプションをチェックしてフィールドを必須にするかどうかを設定できます。
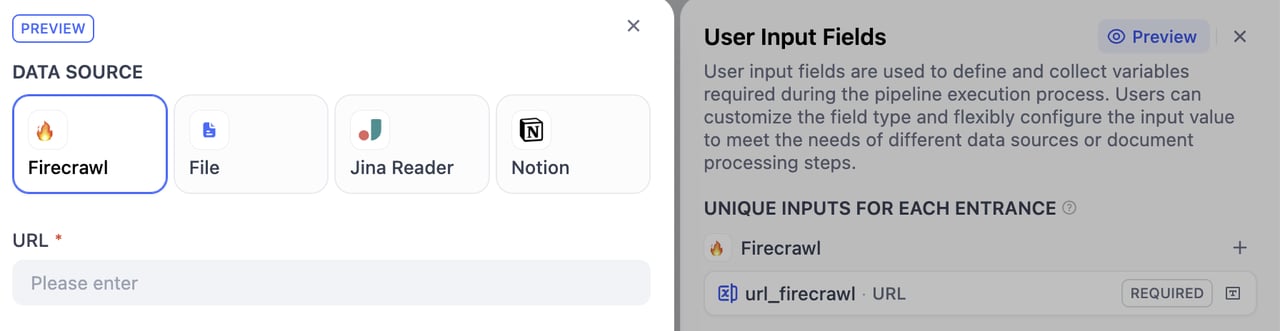
設定完了後、右上のプレビューボタンをクリックしてフォームプレビューインターフェースを閲覧できます。フィールドのグループ化をドラッグして調整できます。感嘆符が表示された場合は、移動後に参照が無効になっていることを示します。
ステップ 5:ナレッジベースの命名
- 名前とアイコン
ナレッジベースの名前を決定します。
絵文字を選択、画像をアップロード、または画像 URL を貼り付けてこのナレッジベースのアイコンとして設定できます。 - ナレッジベース説明
ナレッジベースの簡単な説明を入力してください。これにより AI がデータをより適切に理解し検索できるようになります。空のままにすると、Dify はデフォルトの検索戦略を適用します。 - 権限
ドロップダウンメニューから適切なアクセス権限を選択してください。
ステップ 6:テスト
いよいよ最終工程です!これがナレッジパイプラインオーケストレーションの最終ステップです。 オーケストレーションが完了したら、まずすべての設定を検証する必要があります。次に、いくつかの実行テストを行い、すべての設定を確認します。最後に、ナレッジパイプラインを公開します。設定完全性チェック
テスト前に、設定の不備によるテスト失敗を避けるため、設定の完全性をチェックすることをお勧めします。 右上のチェックリストボタンをクリックすると、システムが不足している部分を表示します。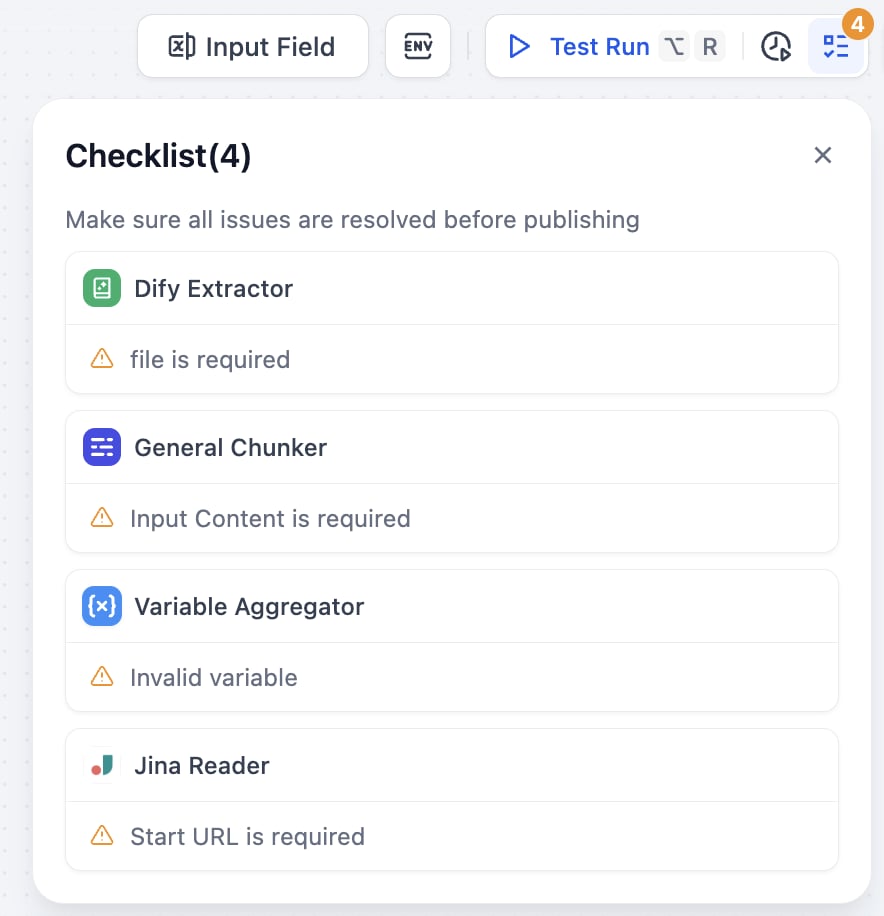
テスト実行

- テスト開始:右上の「テスト実行」ボタンをクリック
- テストファイルインポート:右側にポップアップするデータソースウィンドウでファイルをインポート
- パラメータ入力:インポート成功後、先に設定したユーザー入力フォームに従って対応するパラメータを入力
- テスト実行開始:次のステップをクリックしてパイプライン全体のテストを開始