

⚠️ このドキュメントは AI によって自動翻訳されています。不正確な部分がある場合は、英語版 を参照してください。
インデックス方法の選択
検索エンジンが効率的なインデックスアルゴリズムを使用してユーザーのクエリに最も関連する検索結果をマッチングするのと同様に、選択したインデックス方法はLLMの検索効率とナレッジベースコンテンツに対する回答の正確性に直接影響します。 ナレッジベースでは、高品質とエコノミーの2種類のインデックス方法を提供しており、それぞれ異なる検索設定オプションがあります。- 高品質
- エコノミー
高品質インデックス方法で作成されたナレッジベースは、後からエコノミーに切り替えることはできません。
クロスモーダル検索(テキストと画像を意味的関連性に基づいて取得)を有効にするには、マルチモーダル埋め込みモデル(Visionアイコン付き)を選択してください。ドキュメントから抽出された画像もベクトル化され、検索用にインデックス化されます。このような埋め込みモデルを使用するナレッジベースは、カード上でMultimodalとラベル付けされます。
Q&Aモード
Q&Aモードはセルフホスト環境でのみ利用可能です。
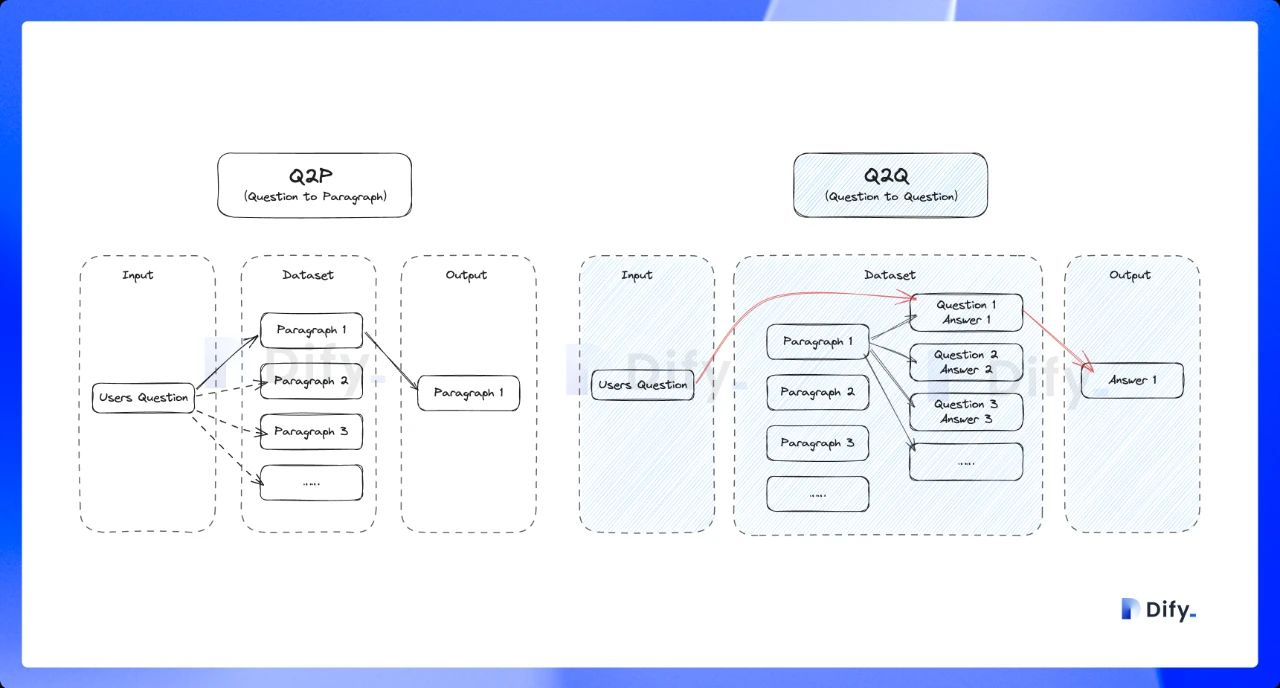
Q to Q戦略により、質問と回答のマッチングがより明確になり、高頻度または類似度の高い質問のシナリオにも適切に対応できます。
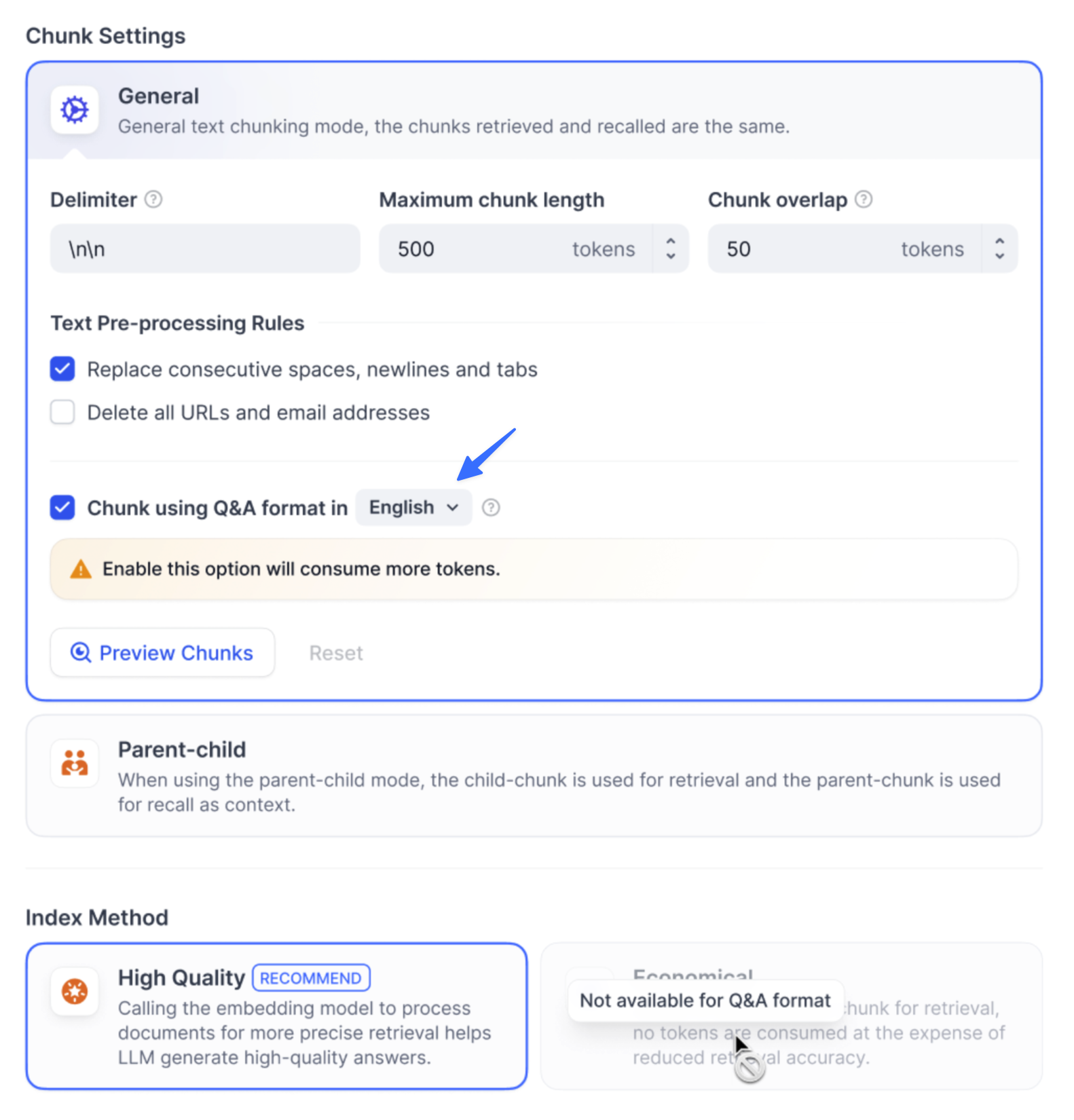

検索設定の指定
ナレッジベースはユーザーのクエリを受け取った後、事前設定された検索方法に従って既存のドキュメントを検索し、高度に関連するコンテンツチャンクを抽出します。これらのチャンクはLLMに不可欠なコンテキストを提供し、最終的に回答の正確性と信頼性に影響を与えます。 一般的な検索方法には以下があります:- ベクトル類似度に基づく意味検索 - テキストチャンクとクエリをベクトルに変換し、類似度スコアリングでマッチングします。
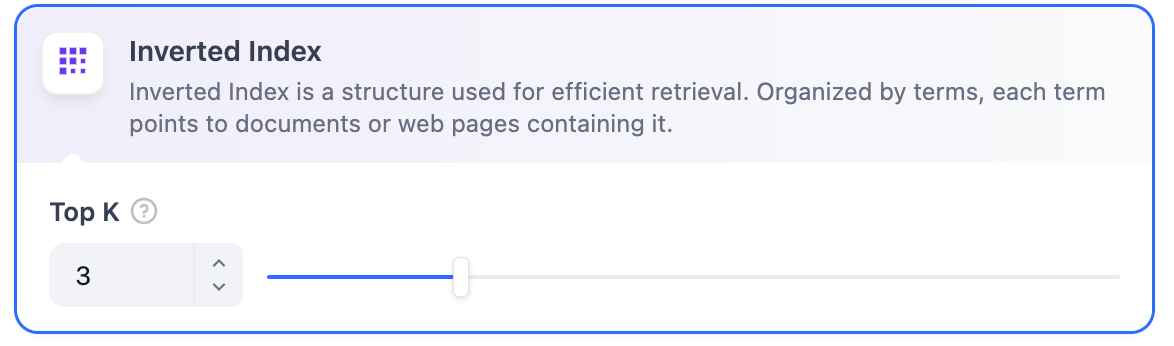
- 逆引きインデックス(標準的な検索エンジン技術)を使用したキーワードマッチング。両方の方法がDifyのナレッジベースでサポートされています。
- 高品質
- エコノミー
高品質高品質インデックス方法では、Difyはベクトル検索、全文検索、ハイブリッド検索の3つの検索設定を提供しています。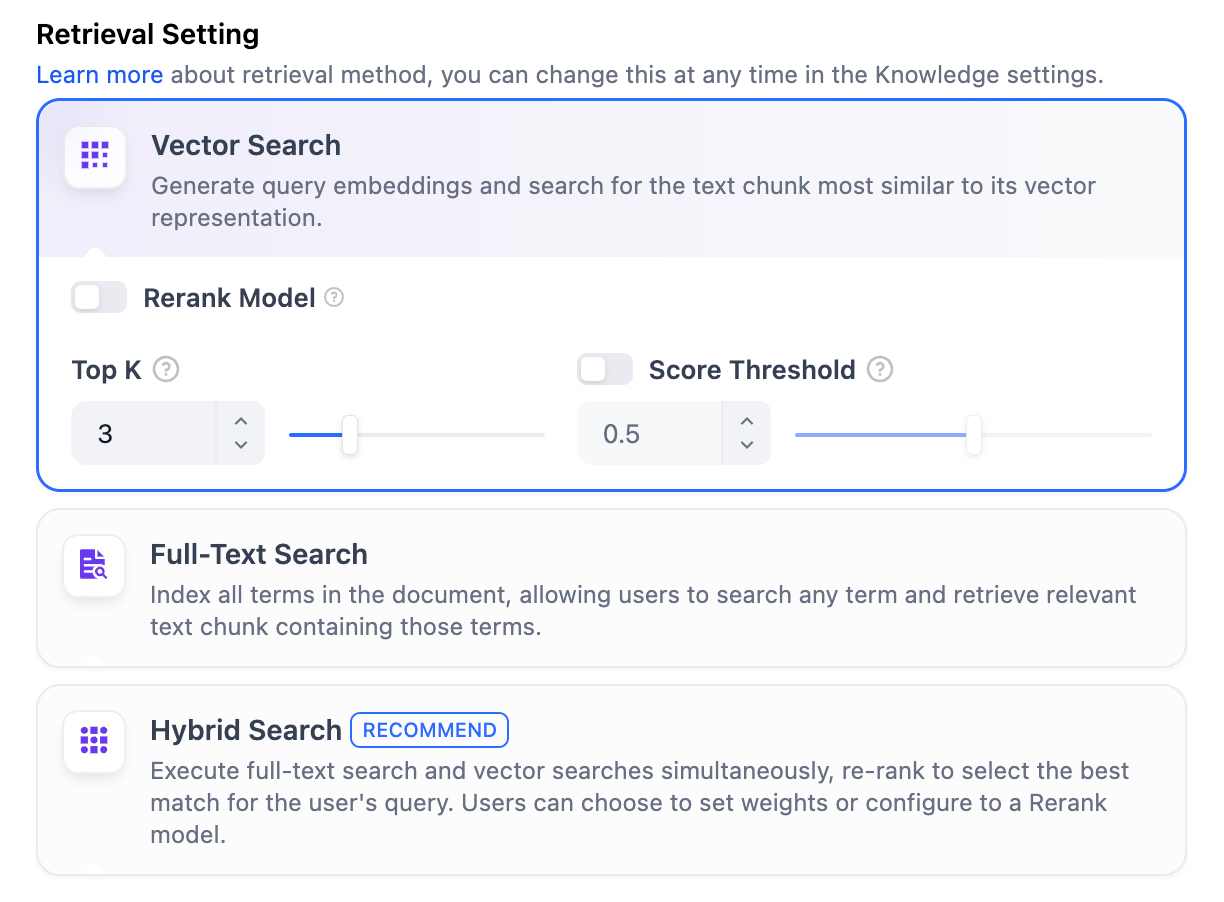 ベクトル検索定義: ユーザーの質問をベクトル化してクエリベクトルを生成し、ナレッジベース内の対応するテキストベクトルと比較して、最も近いチャンクを見つけます。
ベクトル検索定義: ユーザーの質問をベクトル化してクエリベクトルを生成し、ナレッジベース内の対応するテキストベクトルと比較して、最も近いチャンクを見つけます。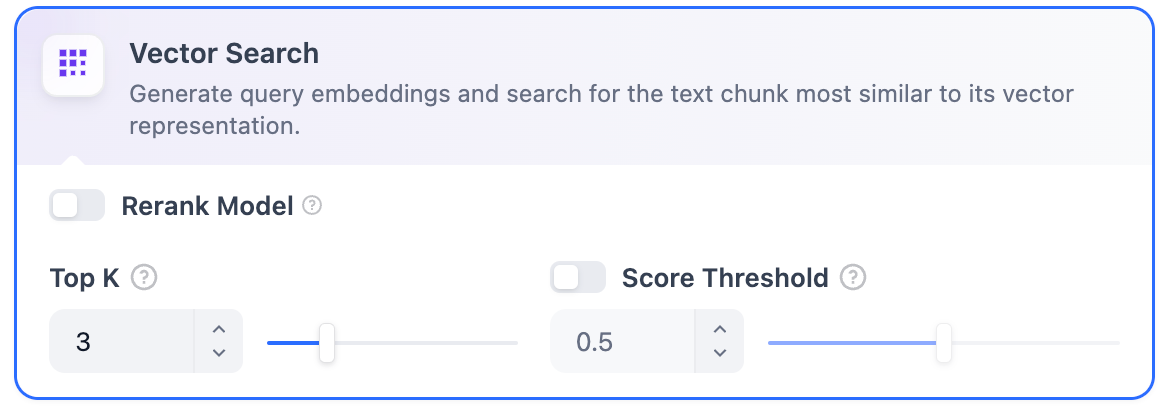 ベクトル検索設定:Rerankモデル: デフォルトでは無効です。有効にすると、サードパーティのRerankモデルがベクトル検索によって返されたテキストチャンクを並べ替えて結果を最適化します。これにより、LLMがより正確な情報にアクセスし、出力品質を向上させることができます。このオプションを有効にする前に、設定 → モデルプロバイダーに移動してRerankモデルのAPIキーを設定してください。
ベクトル検索設定:Rerankモデル: デフォルトでは無効です。有効にすると、サードパーティのRerankモデルがベクトル検索によって返されたテキストチャンクを並べ替えて結果を最適化します。これにより、LLMがより正確な情報にアクセスし、出力品質を向上させることができます。このオプションを有効にする前に、設定 → モデルプロバイダーに移動してRerankモデルのAPIキーを設定してください。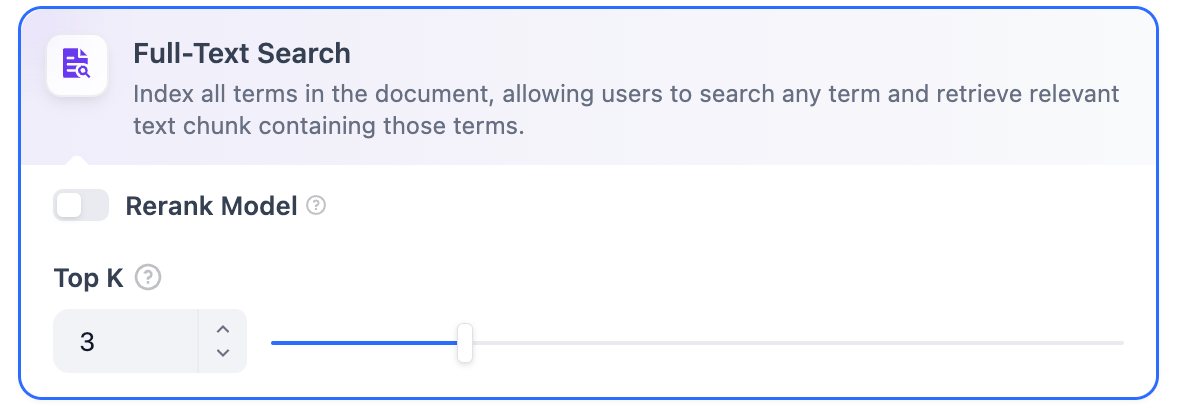 Rerankモデル: デフォルトでは無効です。有効にすると、サードパーティのRerankモデルが全文検索によって返されたテキストチャンクを並べ替えて結果を最適化します。これにより、LLMがより正確な情報にアクセスし、出力品質を向上させることができます。このオプションを有効にする前に、設定 → モデルプロバイダーに移動してRerankモデルのAPIキーを設定してください。
Rerankモデル: デフォルトでは無効です。有効にすると、サードパーティのRerankモデルが全文検索によって返されたテキストチャンクを並べ替えて結果を最適化します。これにより、LLMがより正確な情報にアクセスし、出力品質を向上させることができます。このオプションを有効にする前に、設定 → モデルプロバイダーに移動してRerankモデルのAPIキーを設定してください。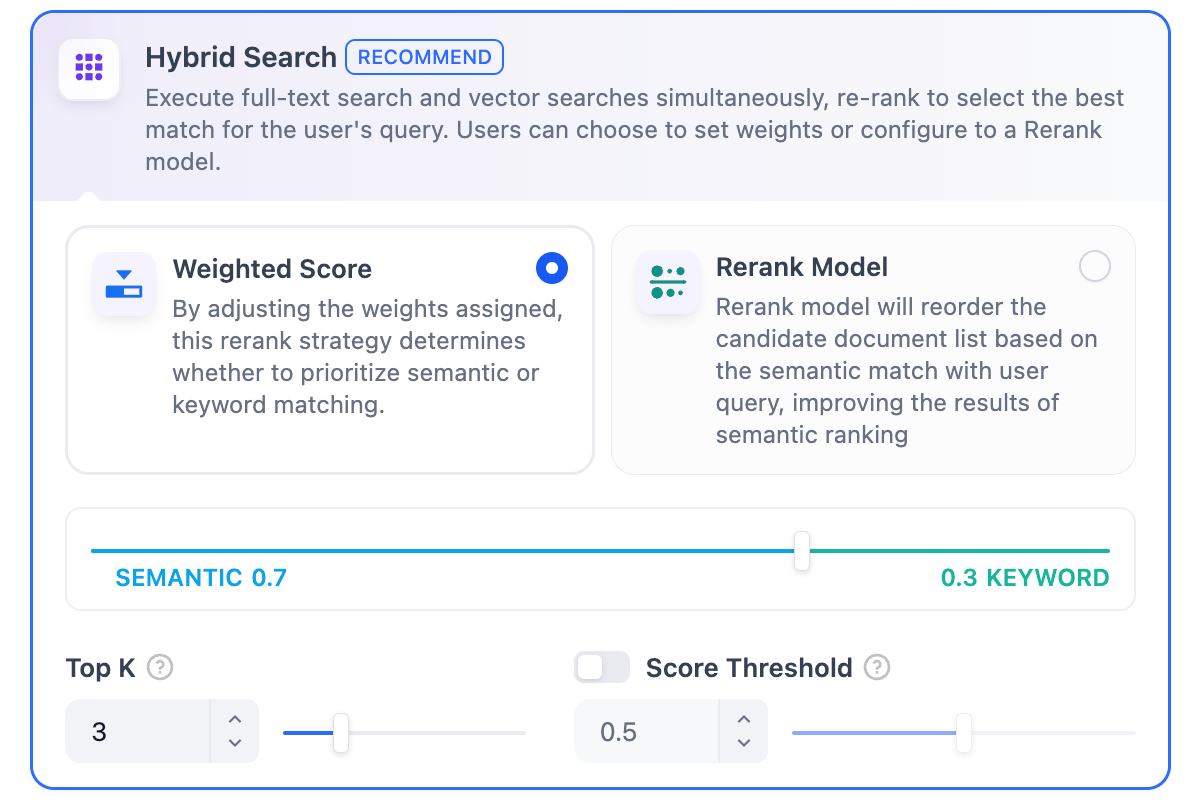 このモードでは、RerankモデルAPIを設定せずに**「重み付け設定」**を指定するか、Rerankモデルを有効にして検索を行うことができます。
このモードでは、RerankモデルAPIを設定せずに**「重み付け設定」**を指定するか、Rerankモデルを有効にして検索を行うことができます。
選択した埋め込みモデルがマルチモーダルの場合は、マルチモーダルRerankモデル(Visionアイコン付き)も選択してください。そうでない場合、検索された画像はリランキングと検索結果から除外されます。
この機能を有効にすると、Rerankモデルのトークンが消費されます。詳細については、関連するモデルの価格ページを参照してください。TopK: ユーザーのクエリに最も類似していると判断されたテキストチャンクの取得数を決定します。選択したモデルのコンテキストウィンドウに基づいてチャンク数を自動的に調整します。デフォルト値は3で、値が高いほど多くのテキストチャンクが呼び出されます。Scoreしきい値: チャンクが取得されるために必要な最小類似度スコアを設定します。このスコアを超えるチャンクのみが取得されます。デフォルト値は0.5です。しきい値が高いほど類似度の要求が高くなり、取得されるチャンク数が少なくなります。
TopKとScore設定はRerankフェーズでのみ有効です。したがって、これらの設定を適用するには、Rerankモデルを追加して有効にする必要があります。全文検索定義: ドキュメント内のすべての用語をインデックス化し、ユーザーが任意の用語をクエリして、それらの用語を含むテキストフラグメントを返すことができます。
選択した埋め込みモデルがマルチモーダルの場合は、マルチモーダルRerankモデル(Visionアイコン付き)も選択してください。そうでない場合、検索された画像はリランキングと検索結果から除外されます。
この機能を有効にすると、Rerankモデルのトークンが消費されます。詳細については、関連するモデルの価格ページを参照してください。TopK: ユーザーのクエリに最も類似していると判断されたテキストチャンクの取得数を決定します。選択したモデルのコンテキストウィンドウに基づいてチャンク数を自動的に調整します。デフォルト値は3で、値が高いほど多くのテキストチャンクが呼び出されます。Scoreしきい値: チャンクが取得されるために必要な最小類似度スコアを設定します。このスコアを超えるチャンクのみが取得されます。デフォルト値は0.5です。しきい値が高いほど類似度の要求が高くなり、取得されるチャンク数が少なくなります。
TopKとScore設定はRerankフェーズでのみ有効です。したがって、これらの設定を適用するには、Rerankモデルを追加して有効にする必要があります。ハイブリッド検索定義: 全文検索とベクトル検索を同時に実行し、リオーダリングステップを含めて、ユーザーのクエリに基づいて両方の検索結果から最もマッチする結果を選択します。
-
重み付け設定
この機能により、ユーザーは意味優先度とキーワード優先度にカスタム重みを設定できます。キーワード検索はナレッジベース内での全文検索を指し、意味検索はナレッジベース内でのベクトル検索を指します。
- 意味値を1にする 意味検索モードのみを有効にします。埋め込みモデルを活用することで、クエリに含まれる正確な用語がナレッジベースになくても、ベクトル距離を計算することで検索の深度を高め、関連コンテンツを返すことができます。また、多言語コンテンツを処理する場合、意味検索は異なる言語間の意味をキャプチャし、より正確なクロス言語検索結果を提供できます。
- キーワード値を1にする キーワード検索モードのみを有効にします。ナレッジベース内で入力テキストとの完全一致を実行し、ユーザーが正確な情報や用語を知っているシナリオに適しています。この方法は消費する計算リソースが比較的少なく、大量のドキュメントを含むナレッジベース内での迅速な検索に適しています。
- キーワードと意味の重みをカスタマイズする 意味検索またはキーワード検索のみを有効にするだけでなく、柔軟なカスタム重み設定を提供しています。両方の方法の重みを継続的に調整して、ビジネスシナリオに合った最適な重み比率を見つけることができます。 Rerankモデル
選択した埋め込みモデルがマルチモーダルの場合は、マルチモーダルRerankモデル(Visionアイコン付き)も選択してください。そうでない場合、検索された画像はリランキングと検索結果から除外されます。この機能を有効にすると、Rerankモデルのトークンが消費されます。詳細については、関連するモデルの価格ページを参照してください。
リファレンス
検索設定を指定した後、以下のドキュメントを参照して、さまざまなシナリオでのキーワードとコンテンツチャンクのマッチング状況を確認できます。ナレッジ検索テスト
ナレッジベース検索のテストと引用方法を学ぶ