

⚠️ このドキュメントは AI によって自動翻訳されています。不正確な部分がある場合は、英語版 を参照してください。
Agent は会話ごとに最大 500 メッセージまたは 2,000 token の履歴を保持します。いずれかの上限を超えた場合、新しいメッセージのために古いメッセージから順に削除されます。
設定
プロンプトの作成
プロンプトは、モデルに何をすべきか、どのように応答すべきか、どのような制約に従うべきかを伝えます。Agent の場合、プロンプトはモデルがタスクをどのように推論し、いつツールを使用するかのガイドにもなるため、期待するワークフローを具体的に記述してください。 効果的なプロンプトを書くためのヒント:- ペルソナを定義する: モデルが誰として振る舞い、どのような専門知識を活用すべきかを記述します。
- 出力形式を指定する: 期待する構造、長さ、スタイルを記述します。
- 制約を設定する: モデルが避けるべきことや従うべきルールを伝えます。
-
ツール使用をガイドする: 特定のツールを名前で指定し、いつ使用すべきかを記述します。
- ワークフローを概説する: 複雑なタスクを、モデルが従うべき論理的なステップに分解します。
変数を使った動的プロンプトの作成
毎回プロンプトを書き直すことなく、異なるユーザーやコンテキストに Agent を適応させるには、変数を追加して必要な情報を事前に収集します。 変数はプロンプト内のプレースホルダーです。各変数は入力フィールドとして表示され、ユーザーが会話開始前に入力し、その値が実行時にプロンプトに挿入されます。ユーザーは会話中に変数の値を更新することもでき、プロンプトはそれに応じて調整されます。 たとえば、データ分析 Agent ではdomain 変数を使用して、ユーザーがフォーカスする領域を指定できます:
- 短文
- 段落
- 選択
- 数値
- チェックボックス
- API ベースの変数
最大 256 文字まで入力可能です。名前、メールアドレス、タイトルなど、1 行に収まる短いテキスト入力に使用します。
ラベル名 は、エンドユーザーに各入力フィールドとして表示される名前です。
AI でプロンプトを生成・改善する
何から始めればよいかわからない場合や、既存のプロンプトを改善したい場合は、生成 をクリックして LLM にドラフトを作成させましょう。 ゼロから望む内容を記述するか、current_prompt を参照して改善点を指定します。より的確な結果を得るには、理想的な出力 にサンプルを追加してください。
生成のたびにバージョンとして保存されるため、自由に実験してロールバックできます。
Dify ツールで Agent を拡張する
Dify ツールを追加して、テキスト生成以外のタスク(ライブデータの取得、Web 検索、データベースクエリなど)でモデルが外部サービスや API と連携できるようにします。 モデルは各クエリに基づいて、いつどのツールを使用するかを判断します。これをより正確にガイドするには、プロンプトで特定のツール名を記述し、いつ使用すべきかを説明してください。 追加したツールの無効化や削除、設定の変更が可能です。ツールに認証が必要な場合は、既存の認証情報を選択するか、新しい認証情報を作成してください。デフォルトの認証情報を変更するには、ツール または プラグイン に移動してください。
最大イテレーション数
エージェント設定 の 最大イテレーション数 は、1 回のリクエストに対してモデルが推論とアクションのサイクル(考える、ツールを呼び出す、結果を処理する)を繰り返せる回数の上限です。 複数のツール呼び出しが必要な複雑なマルチステップタスクでは、この値を増やしてください。値を大きくするとレイテンシと token コストが増加します。独自データに基づいた回答
一般的な知識ではなく独自のデータに基づいてモデルの回答を生成するには、ナレッジベースを追加します。 モデルはナレッジベースの説明文を参照して各ユーザークエリを評価し、検索が必要かどうかを判断します。プロンプトでナレッジベースに言及する必要はありません。 ナレッジベースの説明が詳細であるほど、モデルは関連性をより正確に判断でき、より的確でターゲットを絞った検索結果が得られます。アプリレベルの検索設定
検索結果の処理方法を微調整するには、検索設定 をクリックします。検索設定にはナレッジベースレベルとアプリレベルの 2 つのレイヤーがあります。2 つの連続するフィルターと考えてください。ナレッジベース設定が結果の初期プールを決定し、アプリ設定がさらに結果をリランクまたはプールを絞り込みます。
-
リランク設定
- ウェイト設定 リランク時の、セマンティック類似度とキーワードマッチングの相対的な重みです。セマンティックの重みを高くすると意味的な関連性が重視され、キーワードの重みを高くすると完全一致が重視されます。 ウェイト設定は、追加されたすべてのナレッジベースが 高品質 モードでインデックスされている場合のみ利用可能です。
-
Rerank モデル
クエリとの関連性に基づいてすべての結果を再スコアリングし、並べ替えるリランクモデルです。
マルチモーダルのナレッジベースが追加されている場合は、マルチモーダルリランクモデル(Vision タグ付き)も選択してください。そうしないと、検索された画像がリランクと最終出力から除外されます。
- Top K リランク後に返す上位結果の最大数です。 リランクモデルが選択されている場合、この値はモデルの最大入力容量(モデルが一度に処理できるテキスト量)に基づいて自動的に調整されます。
- スコアしきい値 返される結果の最小類似度スコアです。このしきい値を下回る結果は除外されます。厳密な関連性にはより高いしきい値を、より広範なマッチングにはより低いしきい値を使用してください。
特定ドキュメント内の検索
デフォルトでは、検索はナレッジベース全体を対象とします。検索を特定のドキュメントに制限するには、手動または自動のメタデータフィルタリングを有効にします。 これにより検索精度が向上します。特にナレッジベースが大規模な場合や、異なるコンテキストのコンテンツが含まれている場合に有効です。 ドキュメントメタデータの作成と管理については、メタデータを参照してください。マルチモーダル入力の処理
エンドユーザーがファイルをアップロードできるようにするには、対応するマルチモーダル機能を持つモデルを選択します。モデルがサポートしている場合、関連するファイルタイプのトグル(ビジョン、音声、ドキュメント)が表示され、必要に応じて有効にできます。モデルのサポートするモダリティはタグで簡単に確認できます。
-
解像度: 画像 処理のみの詳細レベルを制御します。
- 高: 複雑な画像ではより高い精度が得られますが、より多くの token を使用します
- 低: シンプルな画像では、より少ない token で高速に処理します
- アップロード方法: ユーザーがデバイスからアップロード、URL の貼り付け、またはその両方を選択できます。
- アップロード制限: ユーザーが 1 メッセージあたりにアップロードできるファイルの最大数です。
セルフホスト環境では、以下の環境変数でファイルサイズの上限を調整できます:
UPLOAD_IMAGE_FILE_SIZE_LIMIT(デフォルト: 10 MB)UPLOAD_FILE_SIZE_LIMIT(デフォルト: 15 MB)UPLOAD_AUDIO_FILE_SIZE_LIMIT(デフォルト: 50 MB)
デバッグとプレビュー
右側のプレビューパネルで Agent をリアルタイムにテストできます。モデルを選択し、メッセージを入力して送信すると、Agent がどのように応答するかを確認できます。 モデルのパラメータを調整して応答の生成方法を制御できます。利用可能なパラメータとプリセットはモデルによって異なります。異なるモデル間で出力を比較するには、複数モデルでデバッグ をクリックして最大 4 つのモデルを同時に実行できます。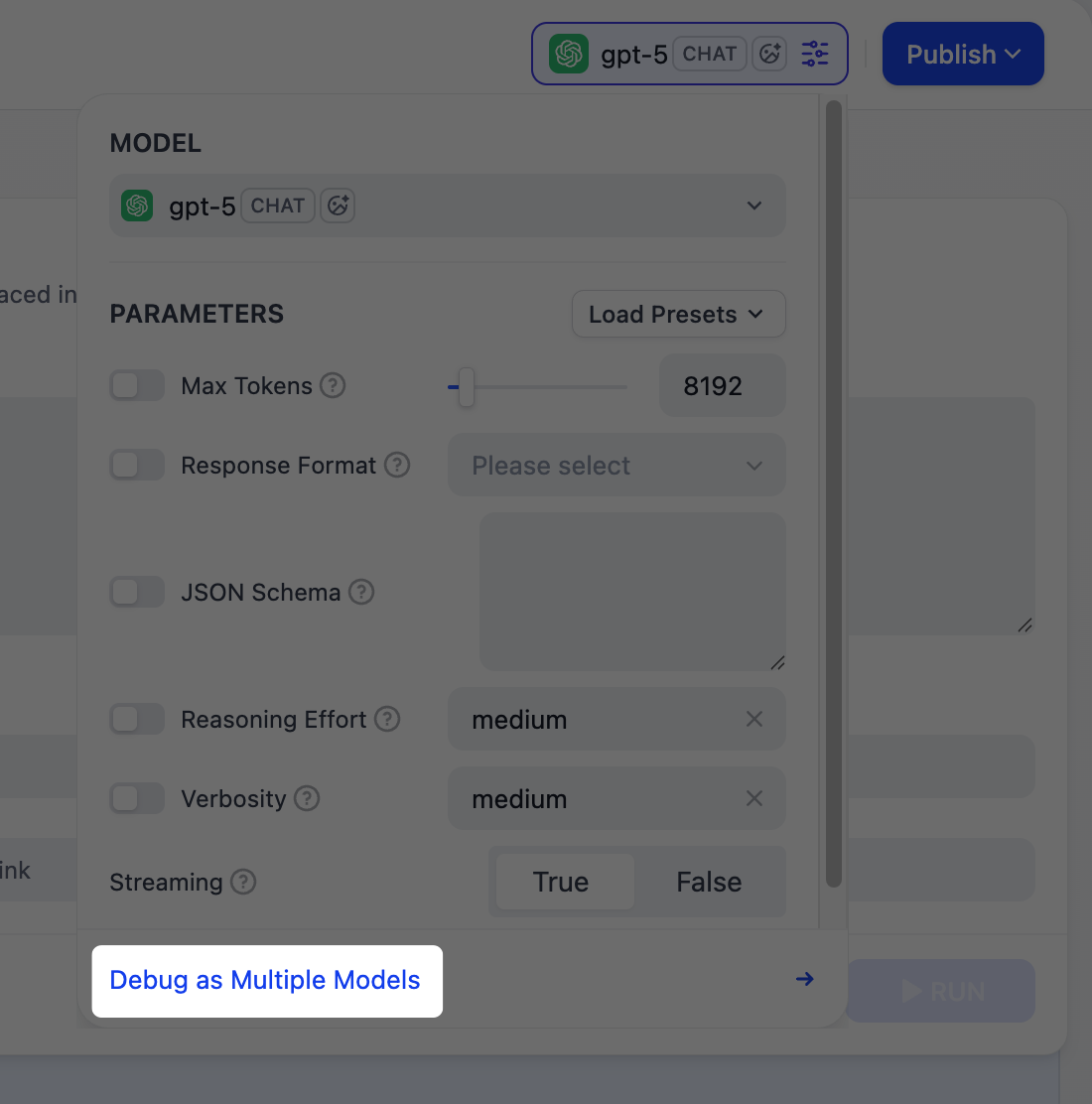
なぜこれが重要なのか
なぜこれが重要なのか
Agent はツールを使うべきタイミング、どのツールがタスクに適しているか、結果をどのように解釈するかを判断する必要があります。これはモデルの推論能力に依存します。ツール呼び出しを内蔵サポートしているモデルは、これらの判断をより確実に実行します。
- Function Calling はネイティブサポートを持つモデル用で、ツールを直接呼び出すことができます。
- ReAct はその他のモデル用で、Dify がプロンプト戦略を通じてツールの使用を誘導します。