

このドキュメントは AI によって自動翻訳されています。不正確な部分がある場合は、英語版 を参照してください。データソースプラグインは Dify 1.9.0 で導入され、ナレッジパイプラインにドキュメントを供給する、パイプライン全体の起点です。 このガイドでは、データソースプラグインの構築とリリースに必要なプラグインアーキテクチャ、コード例、デバッグ方法を解説します。
前提条件
ナレッジパイプラインとプラグイン開発について基本的な理解が必要です:データソースプラグインの種類
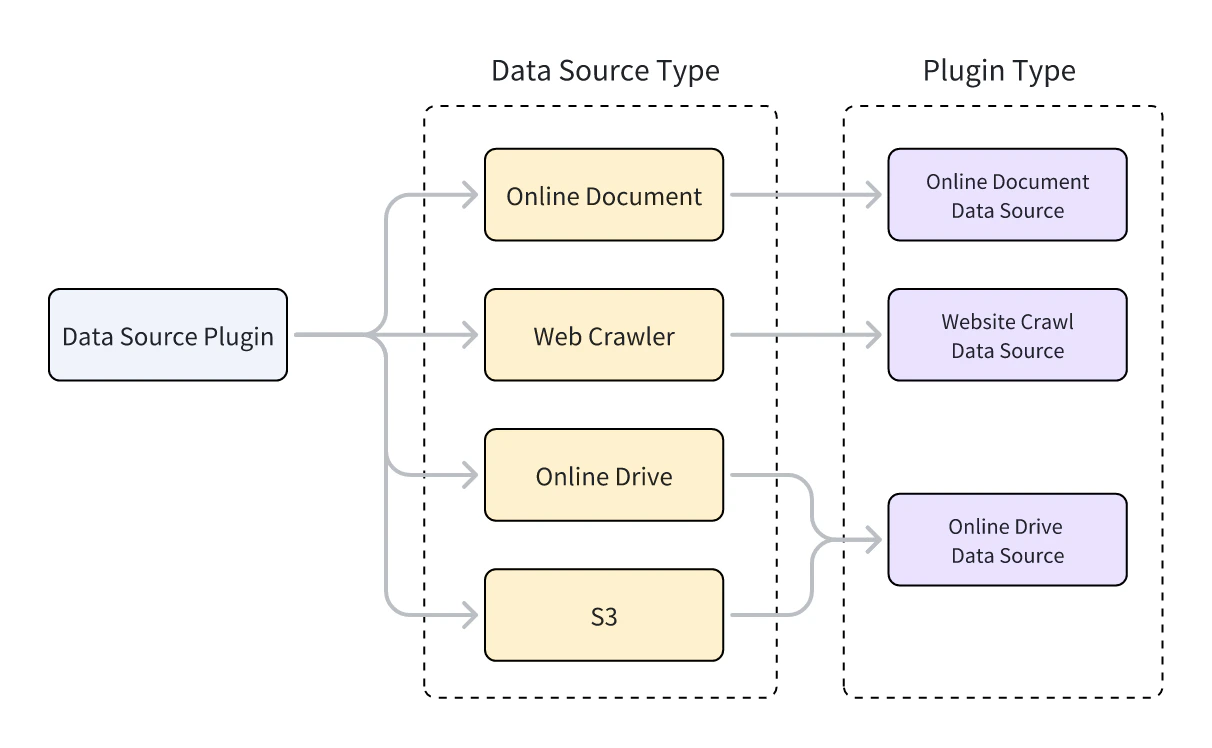
Dify は 3 種類のデータソースプラグインをサポートしています:Web クローラー、オンラインドキュメント、オンラインドライブ。各タイプは異なる親クラスに対応し、プラグイン機能を実装するクラスは対応する親クラスを継承する必要があります。親クラスを継承してプラグイン機能を実装する方法については、ツールプラグイン:ツールコードの準備 を参照してください。
- Web クローラー:Jina Reader、FireCrawl
- オンラインドキュメント:Notion、Confluence、GitHub
- オンラインドライブ:OneDrive、Google Drive、Box、AWS S3、Tencent COS
データソースプラグインの開発
データソースプラグインの作成
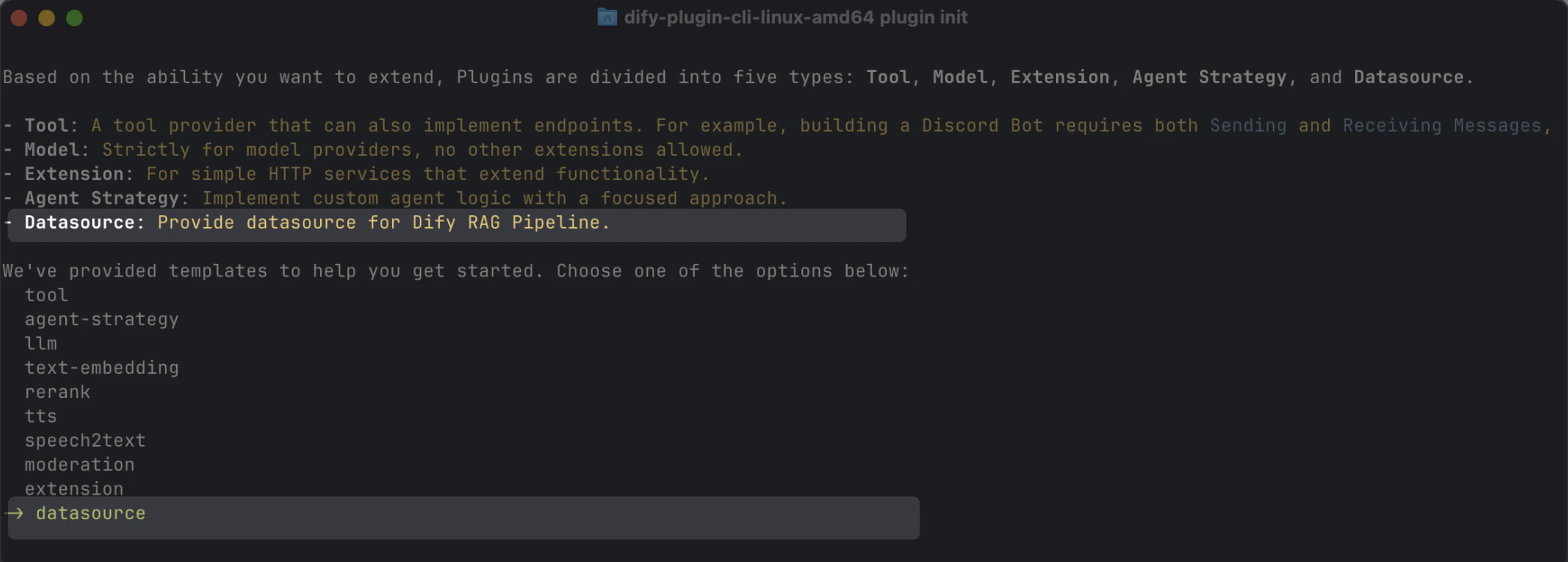
スキャフォールディングコマンドラインツールでdatasource タイプを選択してデータソースプラグインを作成します。セットアップが完了すると、ツールがプラグインプロジェクトコードを生成します。
通常、データソースプラグインはDifyプラットフォームの他の機能を使用する必要がないため、追加の権限は必要ありません。
データソースプラグインの構造
データソースプラグインは3つの主要コンポーネントで構成されています:manifest.yamlファイル:プラグインの基本情報を記述します。providerディレクトリ:プラグインプロバイダーの説明と認証実装コードを含みます。datasourcesディレクトリ:データソースからデータを取得するための説明とコアロジックを含みます。
正しいバージョンとタグの設定
-
manifest.yamlファイルで、最小サポート Dify バージョンを設定します: -
同じファイルで、プラグインを Dify マーケットプレイスのデータソースカテゴリに表示するために以下のタグを追加します:
-
requirements.txtファイルで、プラグイン SDK バージョンを設定します:
データソースプロバイダーの追加
プロバイダーYAMLファイルの作成
プロバイダーYAMLファイルの内容は基本的にツールプラグインと同じですが、以下の2点のみ異なります:プロバイダー YAML ファイルの作成について詳しくは、ツールプラグイン:サードパーティサービス認証情報の完成 を参照してください。
データソースプラグインはOAuth 2.0またはAPIキーによる認証をサポートしています。OAuthの設定については、ツールプラグインにOAuthサポートを追加するを参照してください。
プロバイダーコードファイルの作成
-
API キー認証を使用する場合、プロバイダーコードファイルはツールプラグインと同一です。プロバイダークラスの親クラスを
DatasourceProviderに変更するだけです。 -
OAuth 認証を使用する場合、データソースプラグインはツールプラグインとわずかに異なります。OAuth でアクセス権限を取得する際、フロントエンドに表示するユーザー名とアバターも返すことができます。そのため、
_oauth_get_credentialsと_oauth_refresh_credentialsはname、avatar_url、expires_at、credentialsを含むDatasourceOAuthCredentialsオブジェクトを返す必要があります。DatasourceOAuthCredentialsクラスは以下のように定義されています:
_oauth_get_authorization_url、_oauth_get_credentials、_oauth_refresh_credentialsの関数シグネチャは以下の通りです:
- _oauth_get_credentials
- _oauth_refresh_credentials
データソースの追加
YAMLファイル形式とデータソースコード形式は、3種類のデータソースによって異なります。Webクローラー
WebクローラーデータソースプラグインのプロバイダーYAMLファイルでは、output_schemaは常に4つのパラメータを返す必要があります:source_url、content、title、description。
WebsiteCrawlDatasource を継承し、_get_website_crawl メソッドを実装する必要があります。create_crawl_message メソッドを使用してクロール結果を返します。
複数の Web ページをクロールしてバッチで返すには、WebSiteInfo.status を processing に設定し、クロールした各バッチのページに対して create_crawl_message を呼び出します。すべてのページのクロールが完了した後、WebSiteInfo.status を completed に設定します。
オンラインドキュメント
オンラインドキュメントデータソースプラグインの戻り値には、ドキュメントの内容を表すcontentフィールドを少なくとも含める必要があります。例えば:
OnlineDocumentDatasourceを継承し、2つのメソッドを実装する必要があります:_get_pagesと_get_content。
ユーザーがプラグインを実行すると、まず_get_pagesメソッドを呼び出してドキュメントのリストを取得します。ユーザーがリストからドキュメントを選択した後、_get_contentメソッドを呼び出してドキュメントのコンテンツを取得します。
- _get_pages
- _get_content
オンラインドライブ
オンラインドライブデータソースプラグインはファイルを返すため、以下の仕様に準拠する必要があります:OnlineDriveDatasourceを継承し、2つのメソッドを実装する必要があります:_browse_filesと_download_file。
ユーザーがプラグインを実行すると、まず _browse_files を呼び出してファイルリストを取得します。この時点で prefix は空であり、ルートディレクトリのファイルリストを要求していることを示します。リストにはフォルダとファイルの両方のエントリが含まれます。ユーザーがフォルダを開くと _browse_files が再度呼び出され、この時点で OnlineDriveBrowseFilesRequest の prefix はそのフォルダ内のファイルリストを取得するために使用されるフォルダ ID になります。
ユーザーがファイルを選択した後、プラグインは_download_fileメソッドとファイルIDを使用してファイルのコンテンツを取得します。_get_mime_type_from_filenameメソッドを使用してファイルのMIMEタイプを取得でき、パイプラインが異なるファイルタイプを適切に処理できるようになります。
ファイルリストに複数のファイルが含まれている場合、OnlineDriveFileBucket.is_truncated を True に設定し、OnlineDriveFileBucket.next_page_parameters を次のページを取得するために必要なパラメータ(サービスプロバイダーに応じて次のページのリクエスト ID や URL など)に設定できます。
- _browse_files
- _download_file
prefix、bucket、id変数には特別な用途があり、開発中に必要に応じて柔軟に適用できます:
prefix:ファイルパスのプレフィックスを表します。例えば、prefix=container1/folder1/はcontainer1バケット内のfolder1フォルダからファイルまたはファイルリストを取得します。bucket:ファイルバケットを表します。例えば、bucket=container1はcontainer1バケット内のファイルまたはファイルリストを取得します。このフィールドは、非標準S3プロトコルドライブでは空白のままにできます。id:_download_fileメソッドはprefix変数を使用しないため、完全なファイルパスをidに含める必要があります。例えば、id=container1/folder1/file1.txtはcontainer1バケット内のfolder1フォルダからfile1.txtファイルを取得することを示します。
プラグインのデバッグ
データソースプラグインは、リモートデバッグとプラグインのローカルインストールという 2 つのデバッグ方法をサポートしています。以下の点に注意してください:- プラグインがOAuth認証を使用している場合、リモートデバッグの
redirect_uriはローカルプラグインのものとは異なります。サービスプロバイダーのOAuth Appの関連設定を適宜更新してください。 - データソースプラグインはシングルステップデバッグをサポートしていますが、完全な機能を確保するために、完全なナレッジパイプラインでテストすることをお勧めします。
最終チェック
パッケージ化と公開の前に、以下のすべてを完了していることを確認してください:- 最小サポートDifyバージョンを
1.9.0に設定。 - SDKバージョンを
dify-plugin>=0.5.0,<0.6.0に設定。 README.mdとPRIVACY.mdファイルを作成。- コードファイルには英語のコンテンツのみを含める。
- デフォルトアイコンをデータソースプロバイダーのロゴに置き換える。
パッケージ化と公開
プラグインディレクトリで以下のコマンドを実行して.difypkgプラグインパッケージを生成します:
- Dify環境にプラグインをインポートして使用する。
- プルリクエストを送信して Dify マーケットプレイスにプラグインを公開する。
プラグイン公開プロセスについては、プラグインの公開を参照してください。