このドキュメントは AI によって自動翻訳されています。不正確な部分がある場合は、英語版 を参照してください。
Dify では、ナレッジベースツールを利用して、エージェントが大量のテキストコンテンツから正確な情報を取得することが可能です。しかし、多くの場合、理解する必要があるローカルファイルはそれほど大きくないため、ナレッジベースを使用する必要はありません。このような場合には、ファイルアップロード機能を活用して、LLM がローカルファイルをコンテキストとして理解できるようにします。
本実験では、資料理解アシスタントを例に取り上げます。このアシスタントは、アップロードされたドキュメントに基づいてユーザーに質問を行い、論文などの資料を読みながらの理解をサポートします。
今回の学ぶポイント
- ファイルアップロード機能
- Chatflow の基本操作
- プロンプトの作成
- イテレーションの使用
- 文書抽出器とリスト操作ノード
前提条件
Dify で Chatflow を作成し、モデルプロバイダーを追加して、十分な残高があることを確認してください。
ノードの追加
この実験では、以下の 4 つのノードが必要です:開始ノード、文書抽出器ノード、LLM ノード、返信ノード。
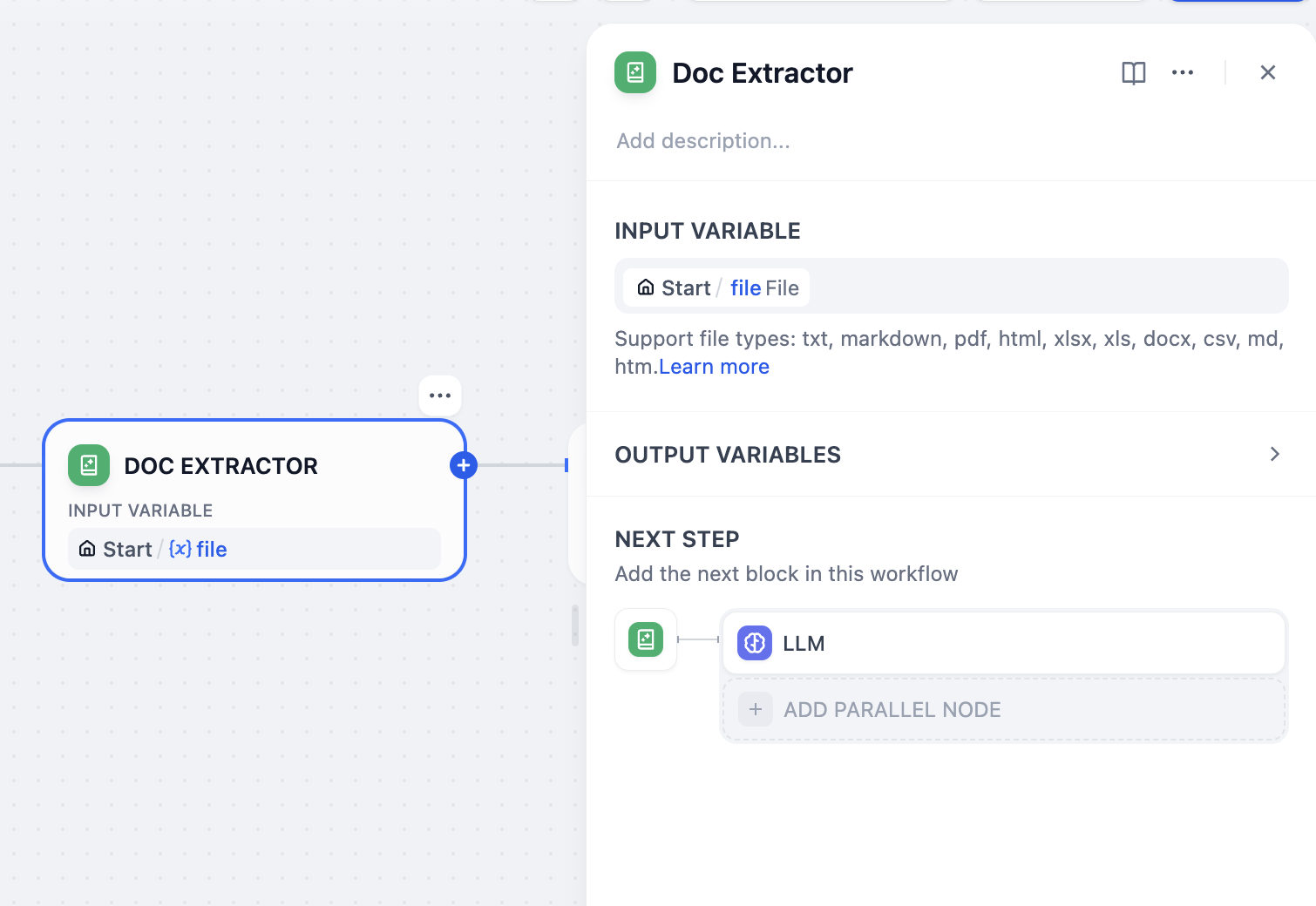
開始ノード
開始ノードでは、ファイル変数を追加する必要があります。Dify の 0.10.0 バージョンでは、ファイルのアップロード機能をサポートしており、ファイルを変数として追加できます。
開始ノードにファイル変数を追加し、サポートされているファイルタイプの中でドキュメントにチェックを入れる必要があります。
一部の読者は、システム変数にsys.filesが存在することに気づくかもしれません。この変数は、ユーザーがダイアログボックスでアップロードしたファイルやファイルリストを示します。
自分でファイル変数を作成することとの違いは、この機能がファイルのアップロードを行い、アップロードされたファイルのタイプを設定し、対話中に新しいファイルをアップロードするたびにこの変数が上書きされる点です。
ビジネスシーンに応じて、適切なファイルアップロード方法を選択してください。
テキスト抽出
LLM はファイルを直接読み取ることができません。これは、多くのユーザーがファイルアップロード機能を初めて使用する際に抱く誤解であり、ファイルを変数として LLM ノードに適用すればよいと考えがちですが、実際には LLM が読み取る内容は何もありません。
そのため、Dify ではテキスト抽出ノードを導入しており、このノードはファイル変数からテキストを抽出し、テキスト形式の変数を出力します。
開始ノードのファイル変数を入力として、テキスト抽出ノードはドキュメント形式のファイルをテキスト形式の変数に変換します。
LLM
この実験では、構造抽出ノードと問題提起ノードの 2 つの LLM ノードを設計する必要があります。
構造抽出
構造抽出ノードは、元文書から文章の構造を抽出し、重要な内容を要約することができます。
ヒントの内容は以下の通りです:
問題提起
問題提起ノードは、構造抽出ノードが要約した内容から記事の問題を抽出し、読者が読む中で問いかけるのを支援します。
ヒントは以下の通りです:
問題 1:複数のアップロードファイルの処理
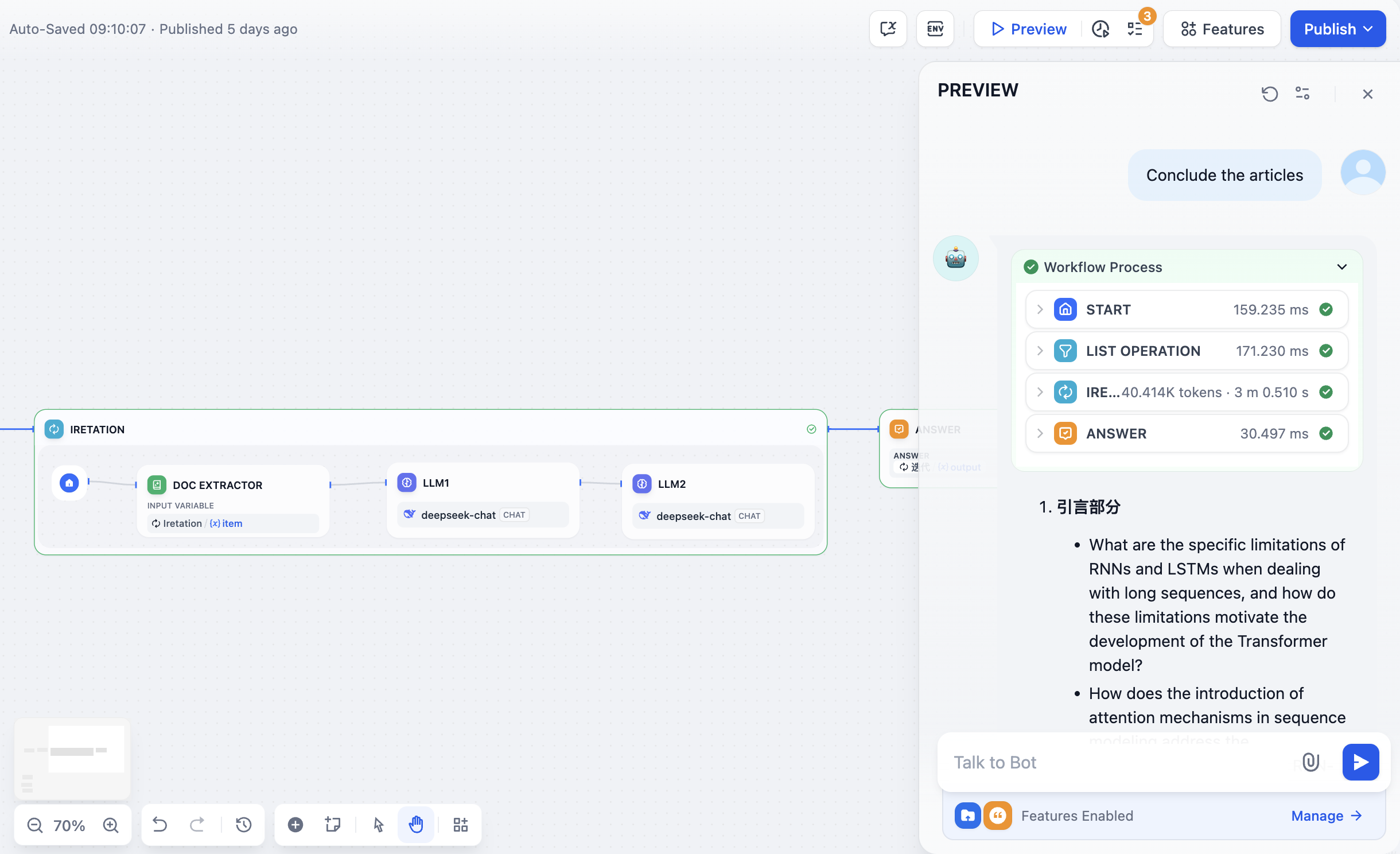
複数のアップロードファイルを処理するためには、イテレーションノードを使用する必要があります。
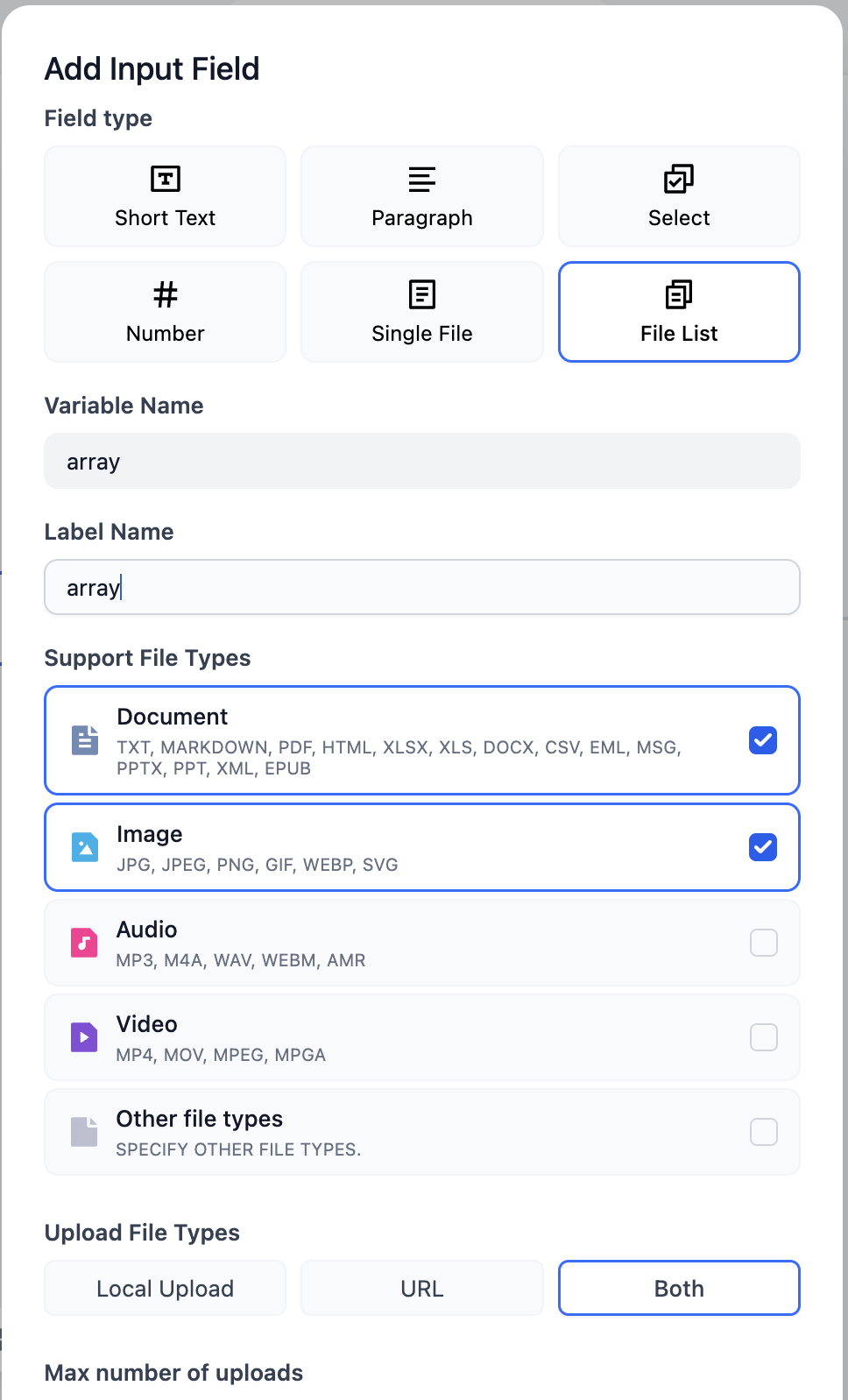
イテレーションノードは、一般的なプログラミング言語の while ループに似ていますが、Dify では条件制限がなく、入力変数はarray型(リスト)のみ使用できます。これは、Dify がリスト内のすべての項目を実行するからです。
そのため、開始ノードのファイル変数をarray型に調整する必要があります。つまり、ファイルリストに変更します。
開始ノードの後にイテレーションノードを追加し、入力変数と出力変数を設定します。イテレーションノード内では、各ループで実行する内容を設定します。この部分は前述の内容と完全に一致します。
問題 2:特定のファイルのみを処理する
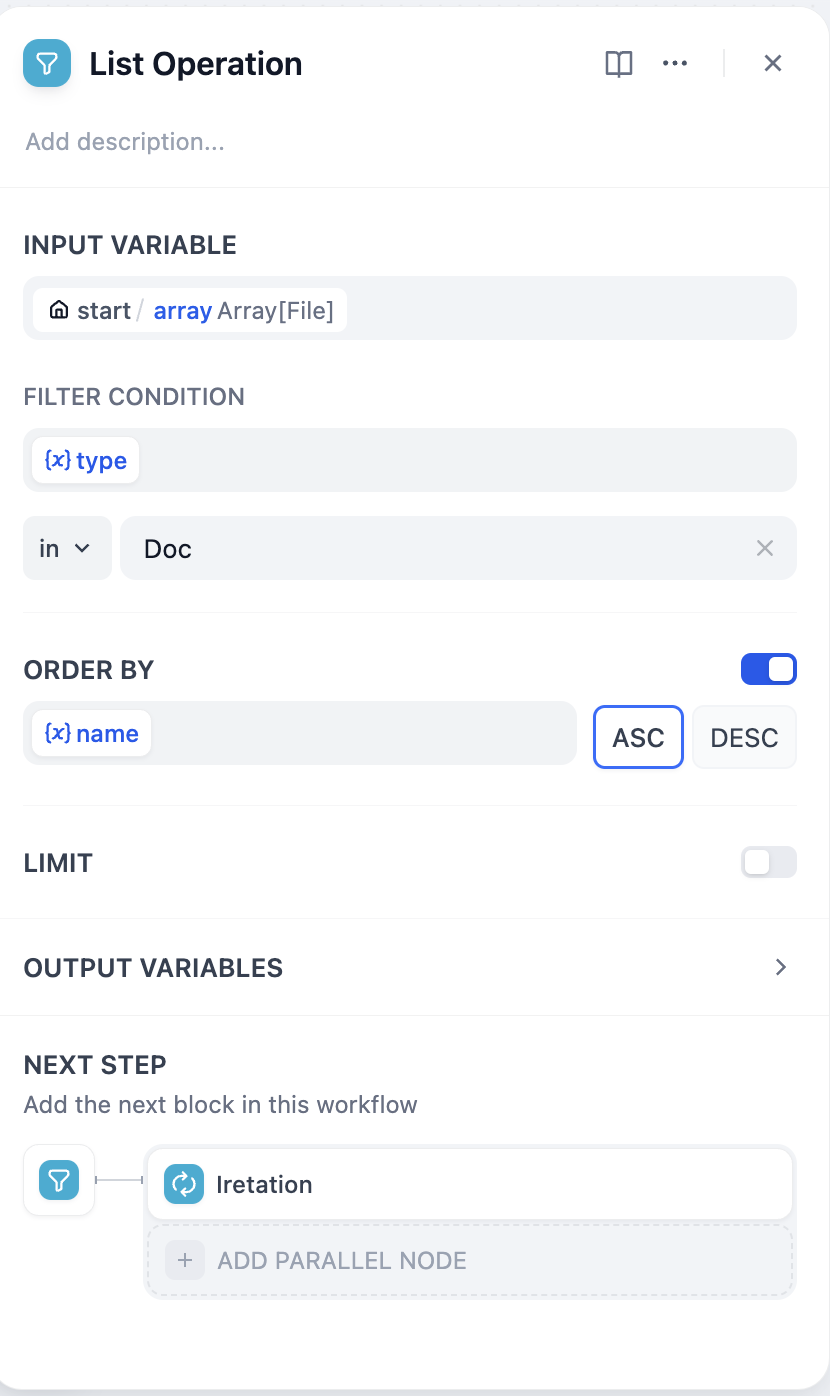
問題 1 において、Dify はすべてのファイルを処理してからループを終了するため、一部のファイルだけを操作したい場合があります。この問題に対処するために、ファイルリストをフィルタリングする必要があります。Dify では、リストに対して操作を行うノードを 「リスト操作」 と呼びます。リスト操作は、ファイルリストだけでなく、すべてのarray型変数に対して適用できます。
例えば、ドキュメントタイプのファイルのみを分析し、処理するファイルをファイル名でソートすることができます。
イテレーションノードの前にリスト操作を追加し、フィルタ条件 やソート を調整し、その後、イテレーションノードの入力をリスト操作ノードの出力に変更します。
Last modified on June 22, 2026