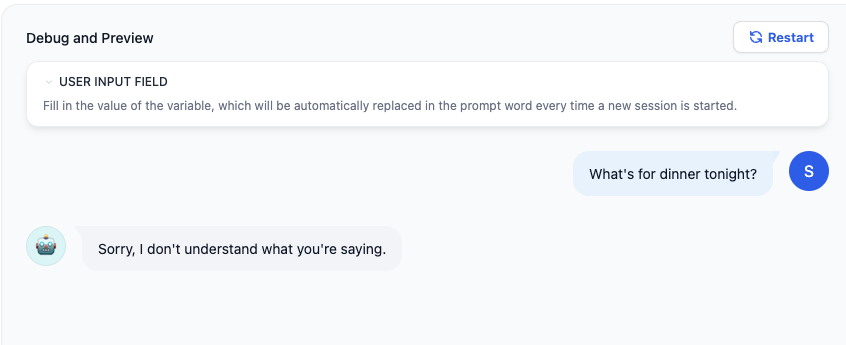
このドキュメントは AI によって自動翻訳されています。不正確な部分がある場合は、英語版 を参照してください。画像生成技術の発展に伴い、Dall-e、Flux、Stable Diffusion などの優れた画像生成ツールが多数登場しています。 本記事では、Dify を使用して AI 画像生成アプリを開発する方法について学びます。
今回の学ぶポイント
- Dify を使用してエイジェントの作り方
- エイジェントの基本的なコンセプト
- プロンプトエンジニアリングの基本
- ツールの使用方法
- 大規模モデルの幻覚の概念
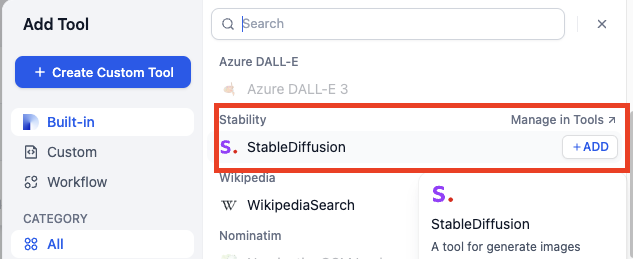
1. Stablility API キーの設定
こちら をクリックして、ステイビリティ API キー管理ページに移動します。まだ登録していない場合は、API 管理ページに入る前に登録を求められます。管理ページに入ったら、キーをコピーするためにコピーをクリックします。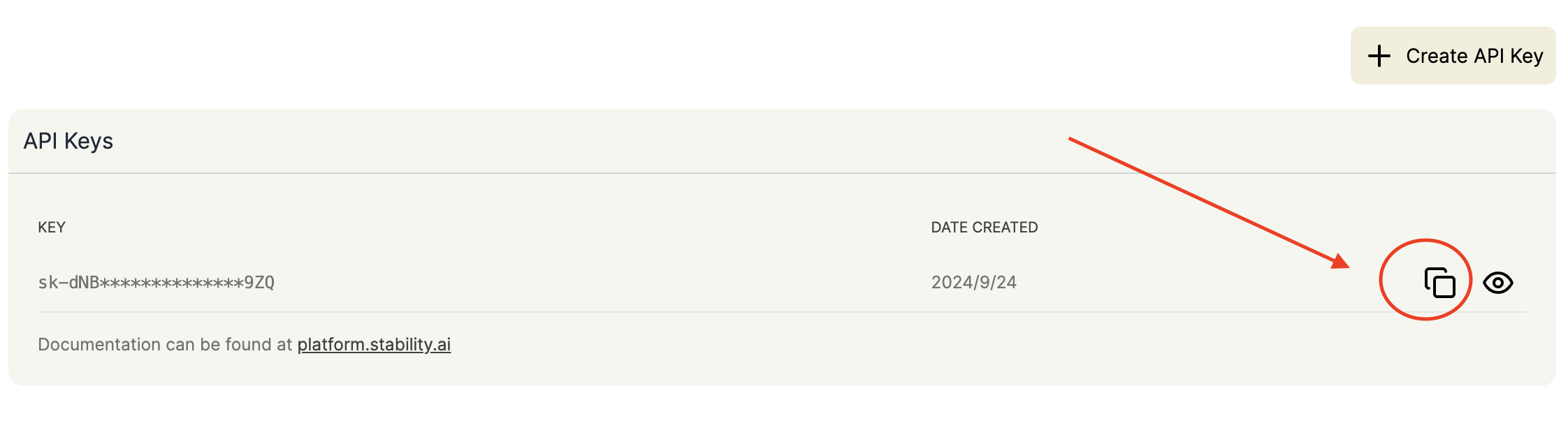
- Dify にログインする
- ツールに入る
- ステイビリティを選択する
- 承認をクリック
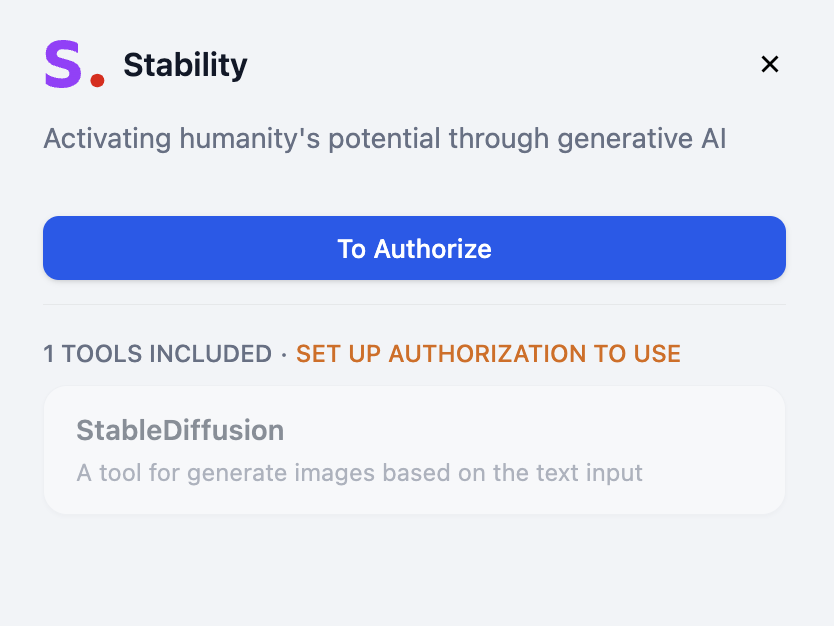
- キーを入力して保存
2. モデルプロバイダの設定
インタラクションを最適化するために、ユーザーの指示を具体化するための大規模言語モデル(LLM)が必要です。つまり、画像生成のためのプロンプトを記述します。次に、Dify でモデルプロバイダを設定します。以下の手順に従って、モデルプロバイダを追加します:統合 > モデルプロバイダー に移動します。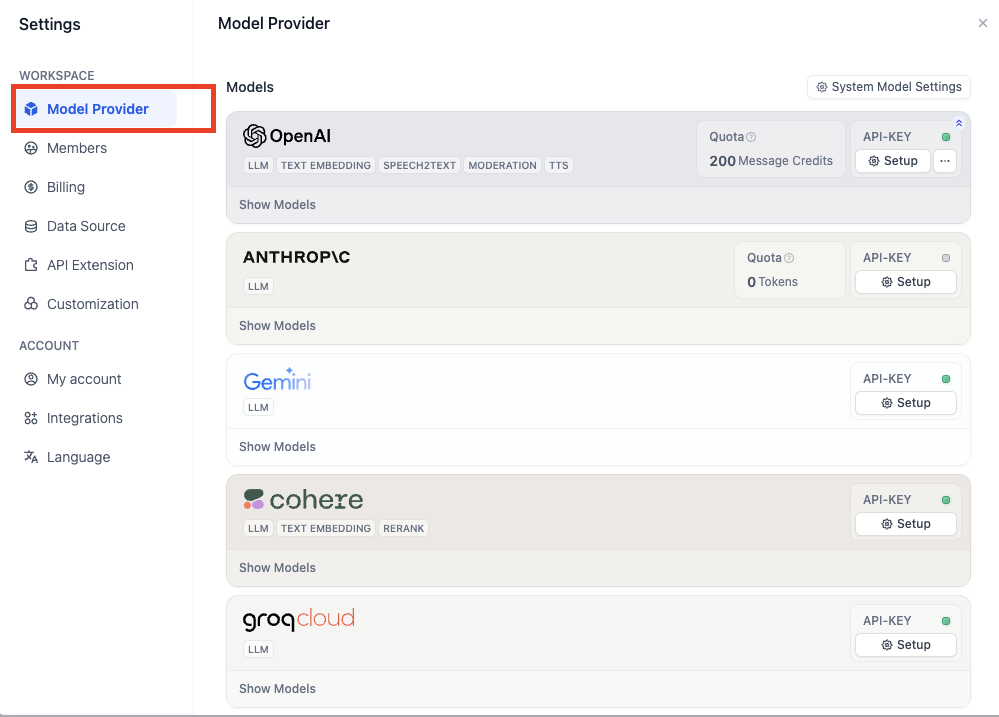
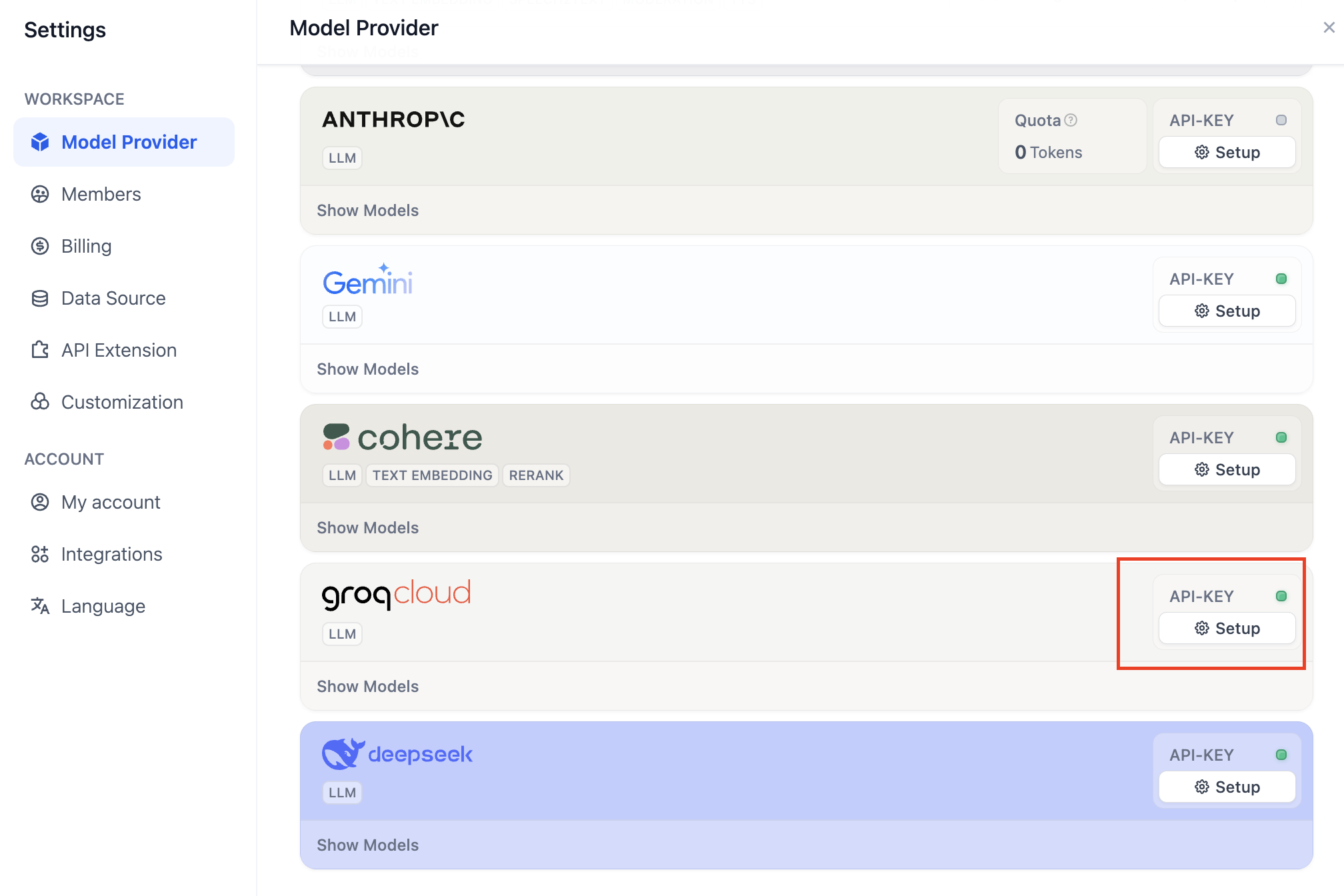
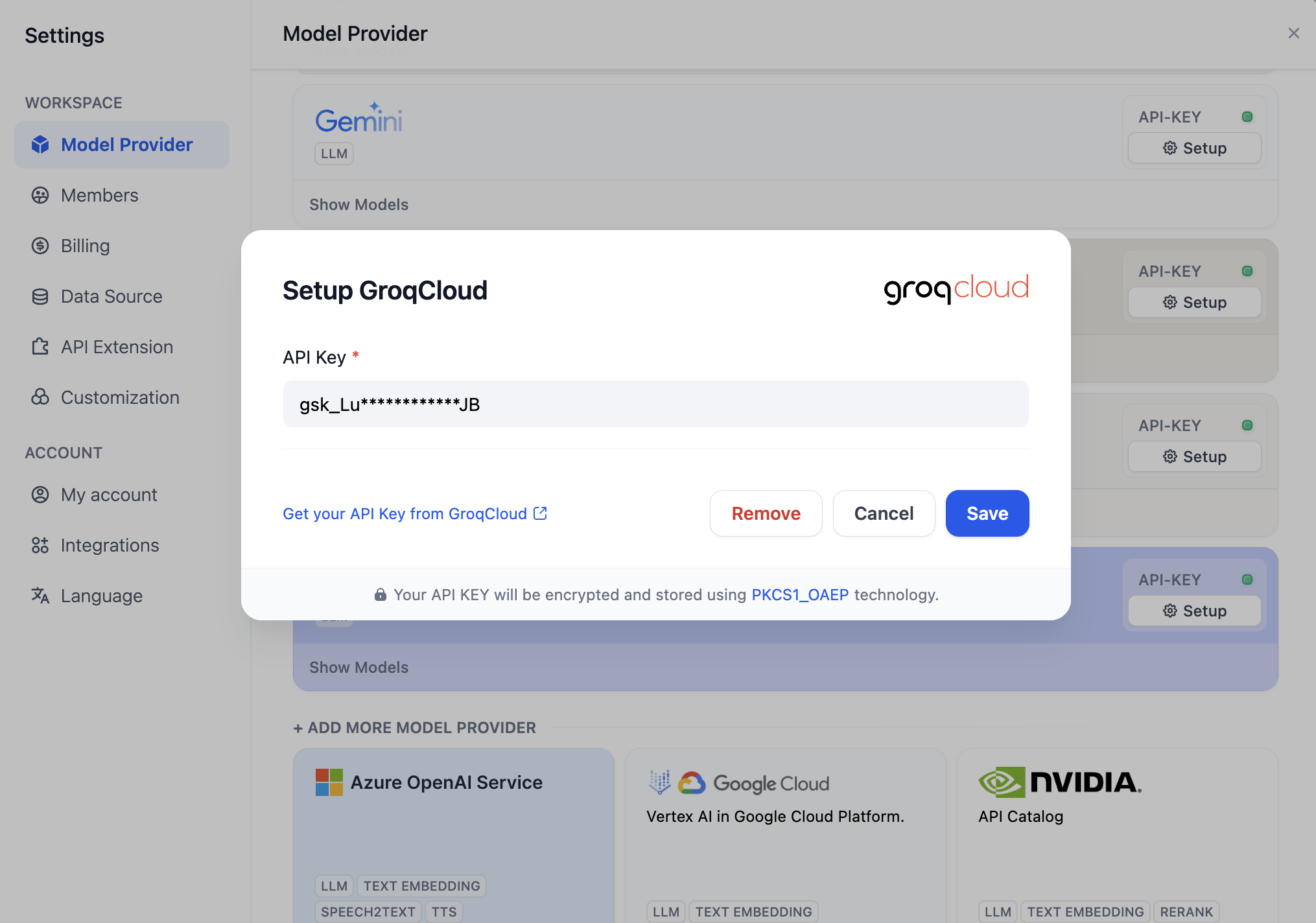
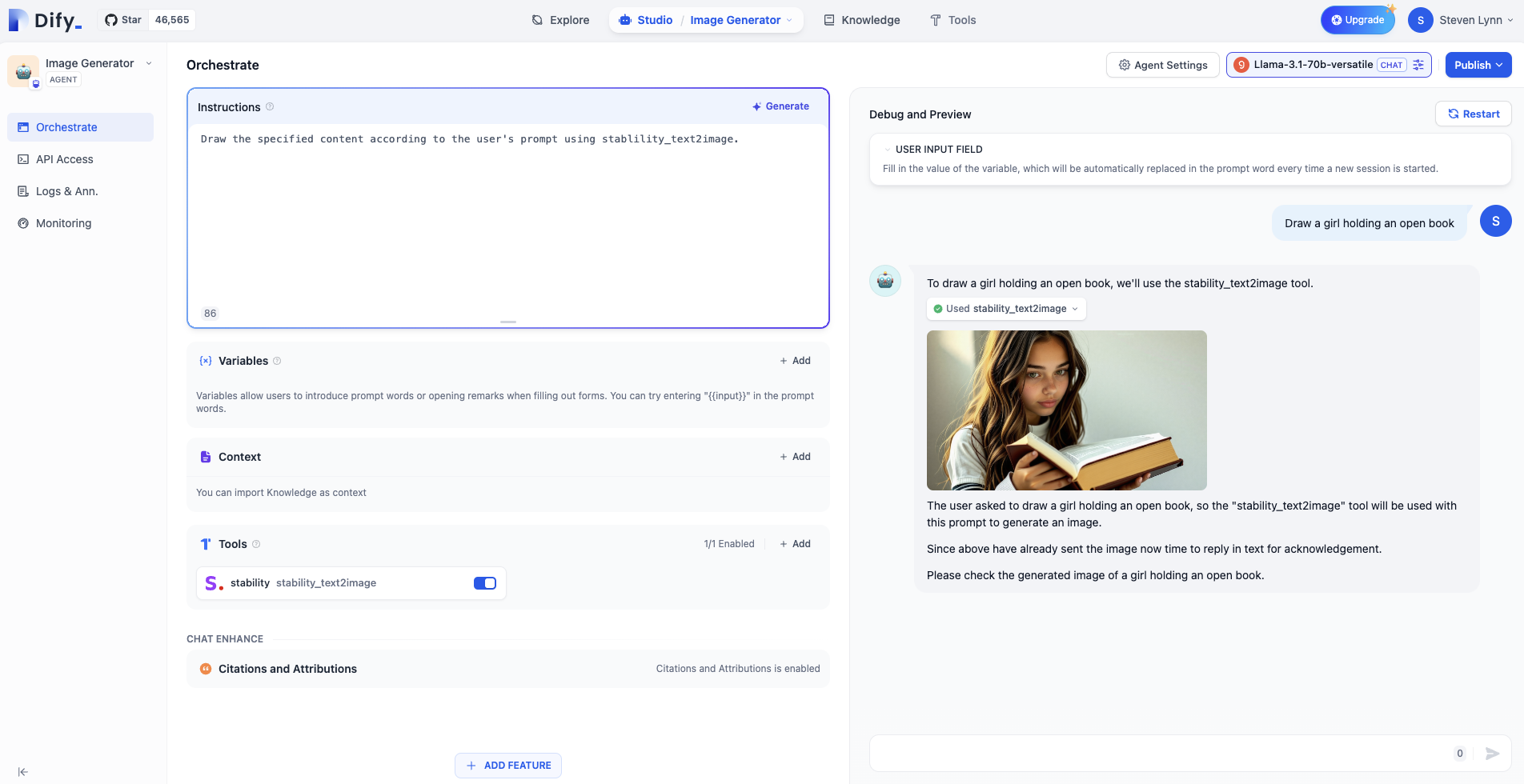
3. エイジェントを作る
Dify - スタジオ に戻り、最初から作成 を選択します。
エージェントとは?エージェントは、人間の行動と能力をシミュレートする AI システムです。自然言語処理を通じて環境とやり取りし、入力情報を理解し、対応する出力を生成します。エージェントはまた「知覚」能力を持ち、さまざまな形式のデータを処理し・分析し、さまざまな外部ツールや API を呼び出して使用してタスクを完了することができます。この設計により、エージェントはより柔軟に複雑な状況を処理し、ある程度人間の思考や行動パターンをシミュレートできるようになります。
プロンプトの書き方
プロンプトはエージェントの核心であり、出力結果に直接的な影響を与えます。一般的に、プロンプトが具体的であればあるほど、出力も向上しますが、過度に長いプロンプトは逆効果になることもあります。 プロンプトを調整する技術は「プロンプトエンジニアリング」と呼ばれています。 この実験では、プロンプトエンジニアリングを完全に習得していなくても心配する必要はありません。後で段階的に学ぶことができます。 まずは、最もシンプルなプロンプトから始めましょう:プロンプトを書くのかしなくても可能ですか?もちろん可能です!
プロンプトの上部にある 自動 をクリックしてください。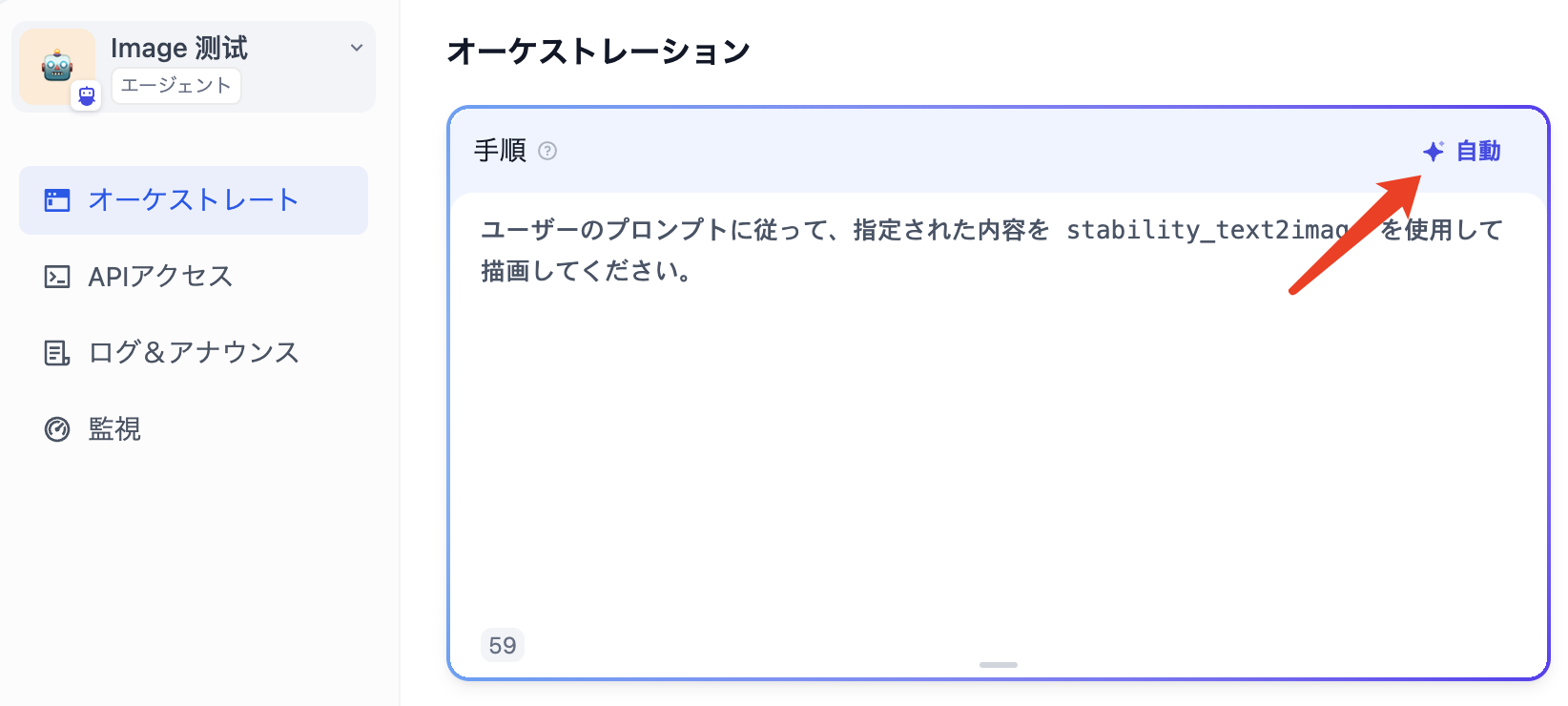
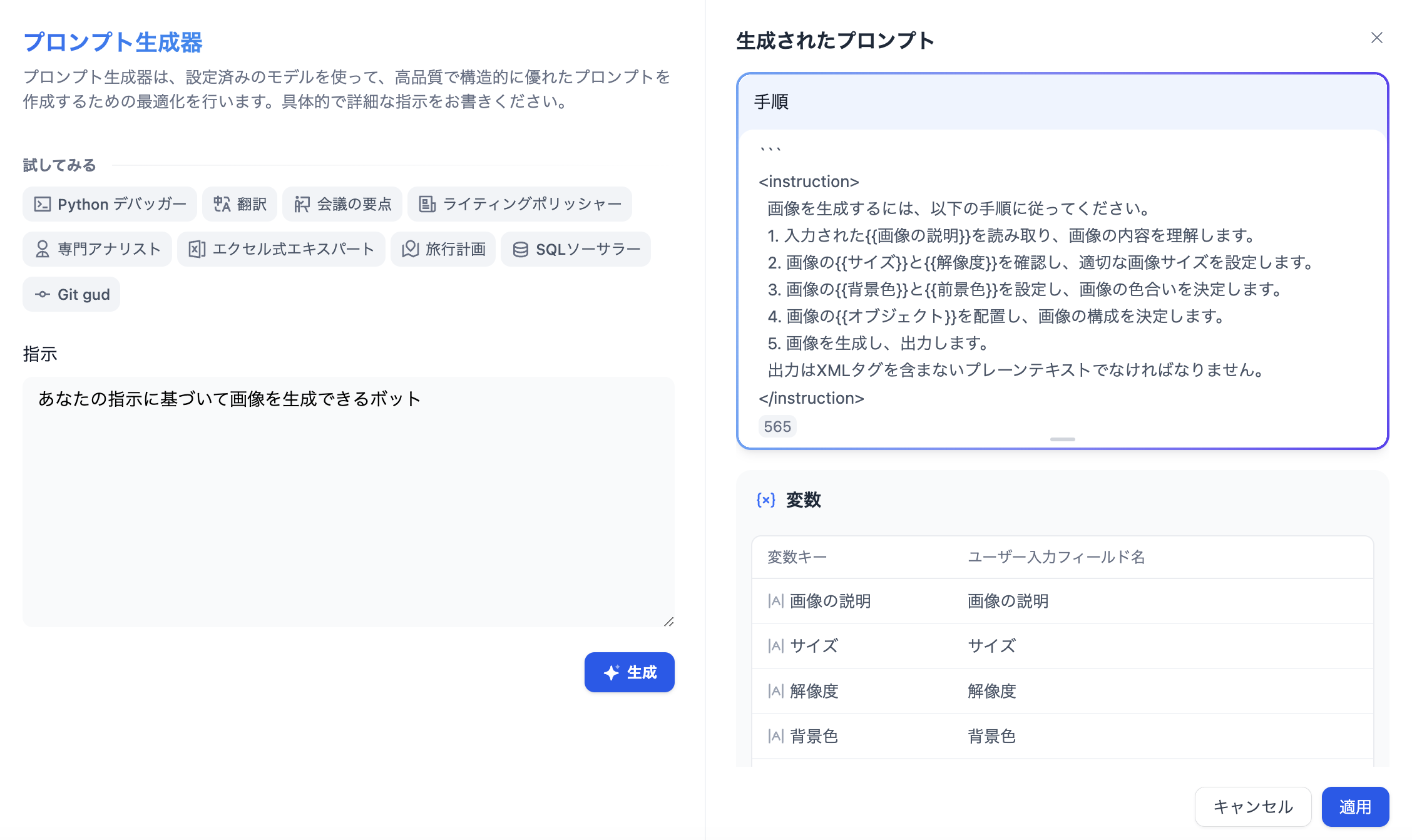
発表
右上の公開ボタンをクリックし、公開後に Run を選択して、オンラインで実行されるエージェント用の Web ページを取得します。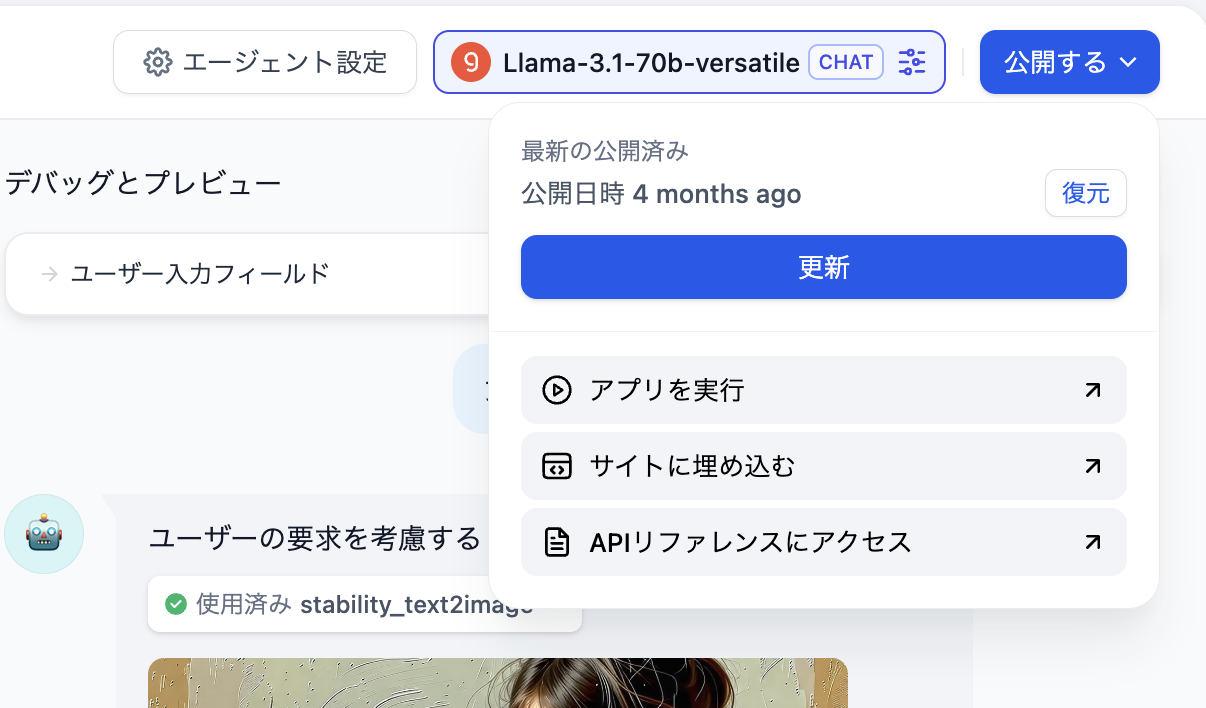
質問 1:生成された画像のスタイルを指定する方法は?
ユーザーの入力コマンドにスタイル指示を追加することができます。例えば:「アニメスタイルで、女の子が開いた本を描いてください。」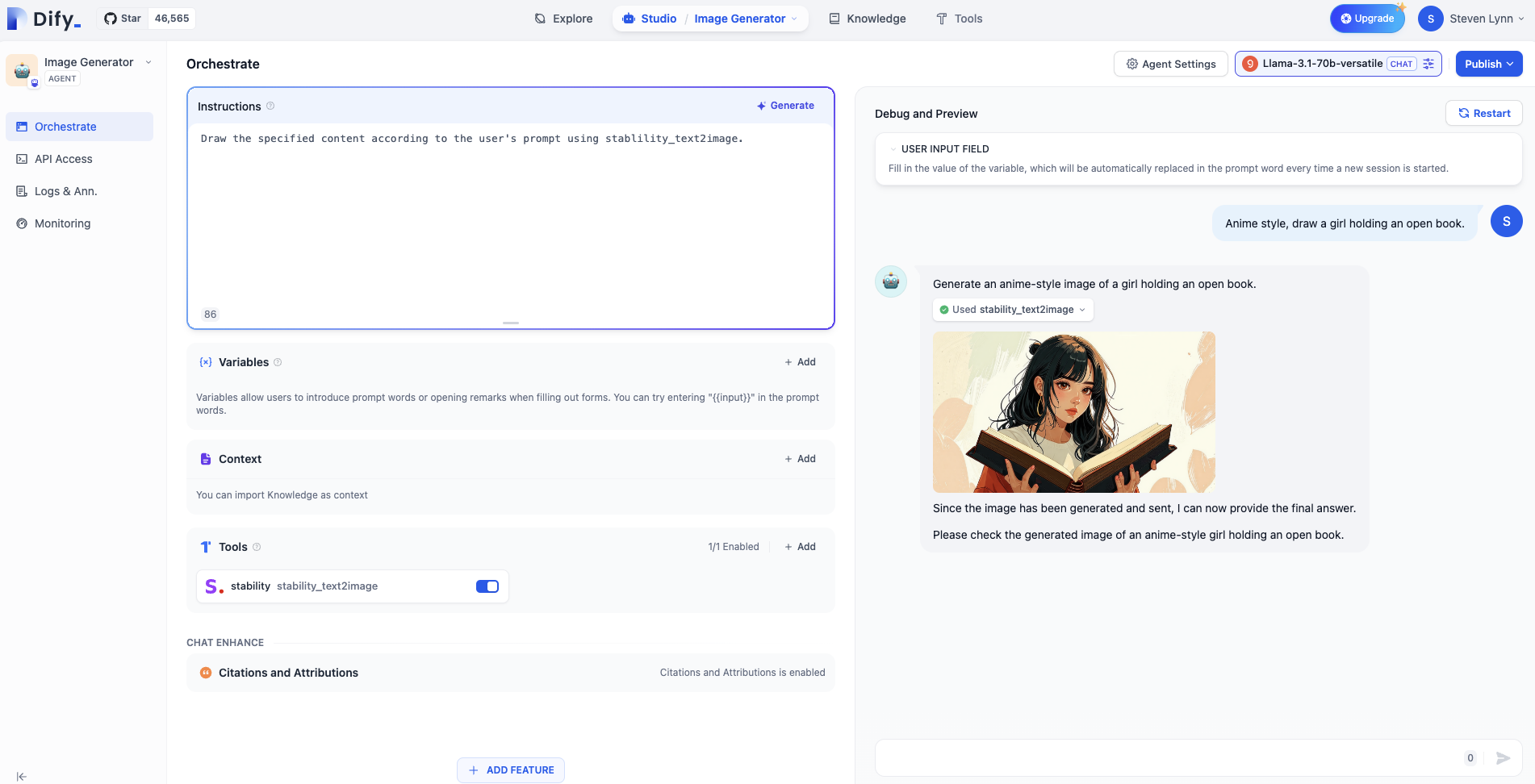
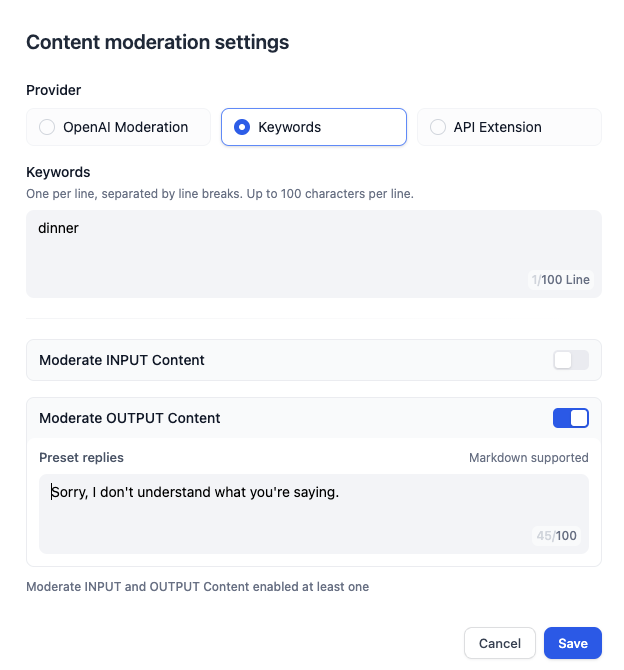
質問 2:特定のユーザーからのリクエストを拒否する方法は?
多くのビジネスシナリオでは、いくつかの不適切なコンテンツの出力を避ける必要がありますが、LLM はしばしば「無知」であり、出力コンテンツが間違っていてもユーザーの指示に従います。このように、モデルが間違ったコンテンツを作り出してユーザーに答えようとする現象を「モデルの幻覚」と呼びます。したがって、必要に応じてモデルがユーザーのリクエストを拒否できることが重要です。 さらに、ユーザーがビジネスに関係のないコンテンツを要求することもあり、エージェントがそのようなリクエストを拒否する必要があります。 異なるプロンプトをカテゴリ別に整理するために、マークダウン形式を使用して、エージェントに不適切なコンテンツを拒否する方法を教えるプロンプトを「制約」のセクションに記述します。もちろん、このフォーマットは標準化のためのものであり、独自のフォーマットを持つこともできます。