

⚠️ 本文档由 AI 自动翻译。如有任何不准确之处,请参考 英文原版。
Agent 每次对话最多保留 500 条消息或 2,000 token 的历史记录。超出任一限制后,最早的消息将被移除以为新消息腾出空间。
配置
编写提示词
提示词告诉模型该做什么、如何回应以及需要遵循的约束条件。对于 Agent,提示词还应该指导模型如何推理任务以及何时使用工具,因此需要明确描述你期望的工作流程。 以下是编写有效提示词的一些技巧:- 定义角色:描述模型应扮演的角色及其应运用的专业知识。
- 指定输出格式:描述你期望的结构、长度或风格。
- 设定约束:告诉模型应避免什么或遵循什么规则。
-
引导工具使用:提及具体工具名称,并描述何时应使用它们。
- 概述工作流程:将复杂任务拆分为模型应遵循的逻辑步骤。
使用变量创建动态提示词
为了让 Agent 适应不同用户或场景而无需每次重写提示词,可以添加变量来预先收集必要的信息。 变量是提示词中的占位符。每个变量都会显示为一个输入字段,用户在对话开始前填写,其值在运行时注入提示词。用户也可以在对话过程中更新变量值,提示词会随之调整。 例如,数据分析 Agent 可以使用domain 变量,让用户指定关注的领域:
- 文本
- 段落
- 下拉选项
- 数字
- 复选框
- 基于 API 的变量
接受最多 256 个字符。适用于姓名、电子邮件地址、标题或任何适合单行显示的简短文本输入。
显示名称 是终端用户看到的每个输入字段的名称。
使用 AI 生成或改进提示词
如果不确定从何开始或想优化现有提示词,点击 生成 让 LLM 帮助你起草。 从零开始描述你的需求,或引用current_prompt 并指定需要改进的内容。要获得更精准的结果,可以在 理想输出 中添加示例。
每次生成都会保存为一个版本,因此你可以自由尝试和回滚。
使用 Dify 工具扩展 Agent
添加 Dify 工具,使模型能够与外部服务和 API 交互,执行文本生成之外的任务,如获取实时数据、搜索网页或查询数据库。 模型会根据每个查询决定何时使用以及使用哪些工具。要更精确地引导工具使用,可在提示词中提及具体工具名称,并描述何时应使用它们。要更改默认凭证,前往 工具 或 插件。
最大迭代次数
Agent 设置 中的 最大迭代次数 限制了模型在单次请求中可以重复推理-行动循环(思考、调用工具、处理结果)的次数。 对于需要多次工具调用的复杂多步任务,可以增大此值。较高的值会增加延迟和 token 消耗。基于你的数据生成回复
要让模型的回复基于你自己的数据而非通用知识,可以添加知识库。 模型会评估每条用户查询与知识库描述的相关性,并决定是否需要检索。你无需在提示词中提及知识库。 知识库描述越详细,模型判断相关性就越准确,从而实现更精准的检索。配置应用级检索设置
要微调检索结果的处理方式,点击 检索设置。检索设置有两个层级,即知识库级别和应用级别。可以将它们理解为两个连续的过滤器:知识库设置决定初始结果池,应用设置进一步重排序结果或缩小结果范围。
-
重排序设置
- 权重设置 重排序过程中,语义相似度与关键词匹配之间的相对权重。较高的语义权重偏向语义相关性,较高的关键词权重偏向精确匹配。 权重设置仅在所有已添加的知识库均以 高质量 模式索引时可用。
-
重排序模型
重排序模型会根据结果与查询的相关性重新打分和排序所有结果。
如果添加了多模态知识库,还需选择多模态重排序模型(标有 Vision 标签)。否则,检索到的图片将被排除在重排序和最终输出之外。
- Top K 重排序后返回的最大结果数量。 选择重排序模型后,此值将根据模型的最大输入容量(模型一次能处理的文本量)自动调整。
- 分数阈值 返回结果的最低相似度分数。低于此阈值的结果将被排除。使用较高阈值获得更严格的相关性,使用较低阈值包含更广泛的匹配。
在特定文档中搜索
默认情况下,检索会在整个知识库中进行。要将检索限制在特定文档中,可启用手动或自动元数据过滤。 这可以提高检索精度,特别是当知识库较大或包含不同场景的内容时。 关于创建和管理文档元数据,详见 元数据。处理多模态输入
要允许终端用户上传文件,需选择具有相应多模态能力的模型。相关文件类型开关(视觉、音频 或 文档)会在模型支持时显示,你可以根据需要启用。你可以通过模型的标签快速识别其支持的模态。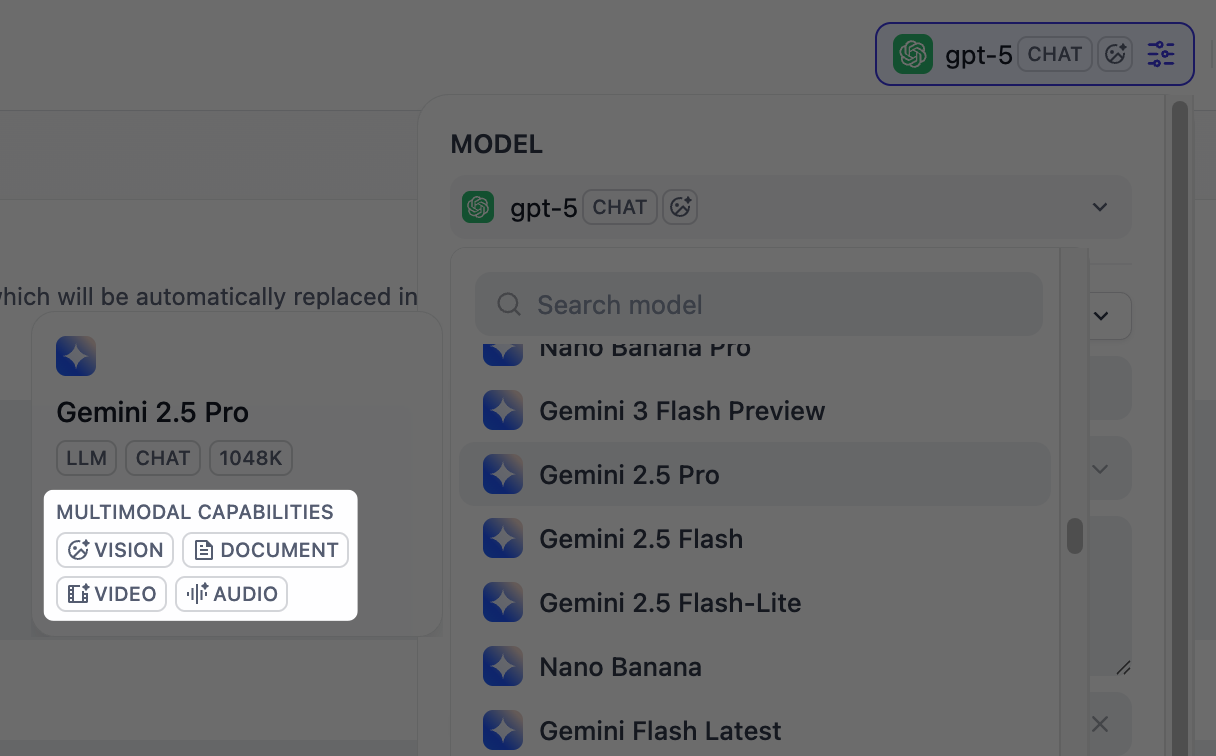
-
分辨率:仅控制 图片 处理的细节级别。
- 高:对复杂图片有更高的准确性,但消耗更多 token
- 低:对简单图片处理更快,消耗更少 token
- 上传方式:选择用户是通过设备上传、粘贴 URL 还是两者兼可。
- 上传数量限制:用户每条消息可上传的最大文件数量。
对于自托管部署,可通过以下环境变量调整文件大小限制:
UPLOAD_IMAGE_FILE_SIZE_LIMIT(默认:10 MB)UPLOAD_FILE_SIZE_LIMIT(默认:15 MB)UPLOAD_AUDIO_FILE_SIZE_LIMIT(默认:50 MB)
调试与预览
在右侧的预览面板中,实时测试你的 Agent。选择一个模型,输入消息并发送,查看 Agent 的响应。 你可以调整模型参数来控制生成方式。可用参数和预设因模型而异。要比较不同模型的输出,点击 多个模型进行调试 同时运行最多 4 个模型。
为什么这很重要
为什么这很重要
Agent 需要判断何时使用工具、哪个工具适合当前任务,以及如何解读结果,这取决于模型的推理能力。具有内置工具调用支持的模型在执行这些决策时也更加可靠。
- Function Calling 适用于原生支持的模型,意味着它们可以直接调用工具。
- ReAct 适用于其他模型,Dify 通过提示词策略引导它们使用工具。