

本文档由 AI 自动翻译。如有任何不准确之处,请参考 英文原版。知识库可以作为外部知识提供给大语言模型用于精确回复用户问题,你可以在 Dify 的所有应用类型内关联已创建的知识库。 以聊天助手为例,使用流程如下:
- 进入 知识库,创建 即用型知识库 并上传文件
- 进入 工作室,创建应用并选择 聊天助手
- 进入 上下文设置 点击 添加 选择已创建的知识库
- 在 上下文设置 — 参数设置 内配置 召回策略
- 在 元数据筛选 板块中配置元数据的筛选条件,使用元数据功能筛选知识库内的文档
- 在 添加功能 内打开 引用和归属
- 在 调试与预览 内输入与知识库相关的用户问题进行调试
- 调试完成之后 保存并发布 为一个 AI 知识库问答类应用
关联知识库并指定召回模式
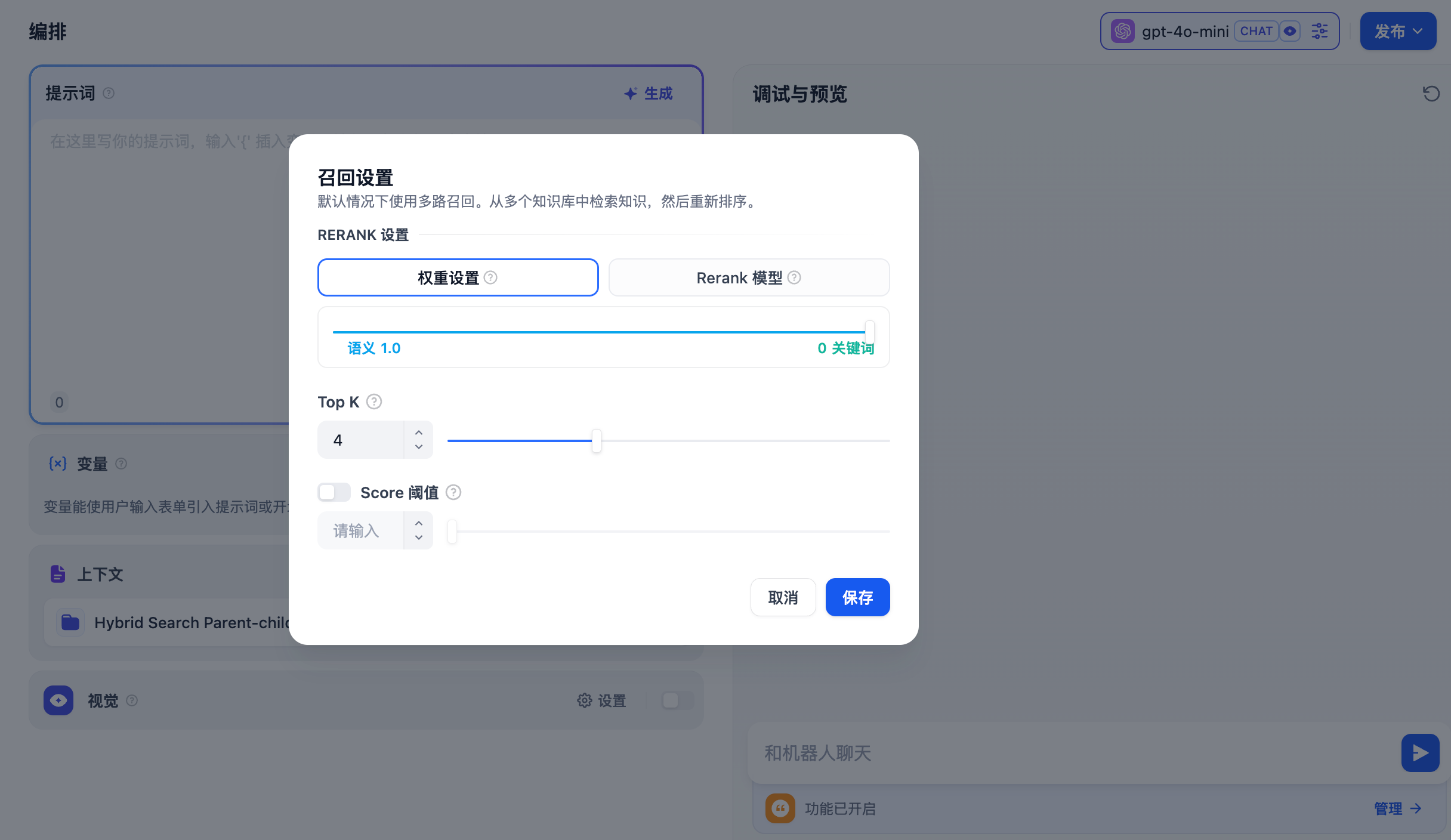
如果当前应用的上下文涉及多个知识库,需要设置召回模式以使得检索的内容更加精确。进入 上下文 — 参数设置 — 召回设置。召回设置
检索器会在所有与应用关联的知识库中去检索与用户问题相关的文本内容,并将多路召回的相关文档结果合并,以下是召回策略的技术流程图: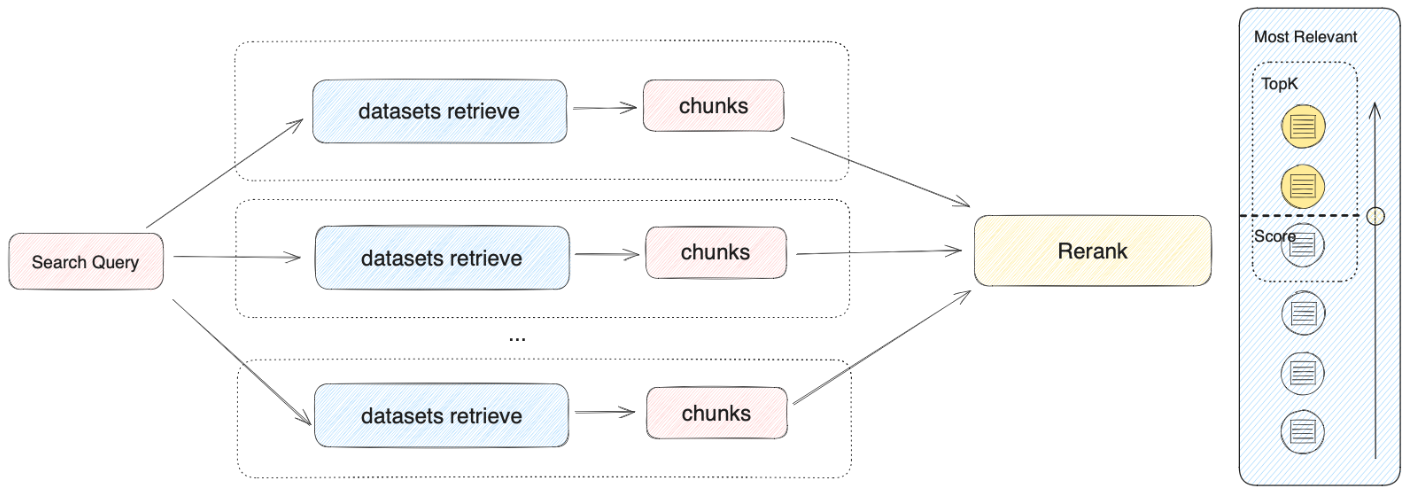
-
语义值为 1
仅启用语义检索模式。借助 Embedding 模型,即便知识库中没有出现查询中的确切词汇,也能通过计算向量距离的方式提高搜索的深度,返回正确内容。此外,当需要处理多语言内容时,语义检索能够捕捉不同语言之间的意义转换,提供更加准确的跨语言搜索结果。
语义检索指的是比对用户问题与知识库内容中的向量距离。距离越近,匹配的概率越大。参考阅读:《Dify:Embedding 技术与 Dify 数据集设计/规划》。
- 关键词值为 1 仅启用关键词检索模式。通过用户输入的信息文本在知识库全文匹配,适用于用户知道确切的信息或术语的场景。该方法所消耗的计算资源较低,适合在大量文档的知识库内快速检索。
- 自定义关键词和语义权重 除了仅启用语义检索或关键词检索模式,我们还提供了灵活的自定义权重设置。你可以通过不断调试二者的权重,找到符合业务场景的最佳权重比例。
在模型供应商内配置 Rerank 模型
- TopK 用于筛选与用户问题相似度最高的文本片段。系统同时会根据选用模型上下文窗口大小,动态调整分段数量。数值越高,预期被召回的文本分段数量越多。
- Score 阈值 用于设置文本片段筛选的相似度阈值。向量检索的相似度分数需要超过设置的分数后才会被召回,数值越高,预期被召回的文本数量越少。
使用元数据筛选知识
Chatflow/Workflow
在 Chatflow/Workflow 的 知识检索 节点中,你可以使用 元数据筛选 功能精确检索文档。该功能有助于你根据文档的元数据字段(如标签、类别或访问权限)优化检索结果。配置步骤
-
选择筛选模式
- 禁用模式(默认):禁用 元数据筛选 功能,不配置任何筛选条件。
- 自动模式:系统会根据传输给该 知识检索 节点的 查询变量 自动配置筛选条件,适用于简单的筛选需求。
启用自动模式后,你依然需要在 模型 栏中选择合适的大模型以执行文档检索任务。
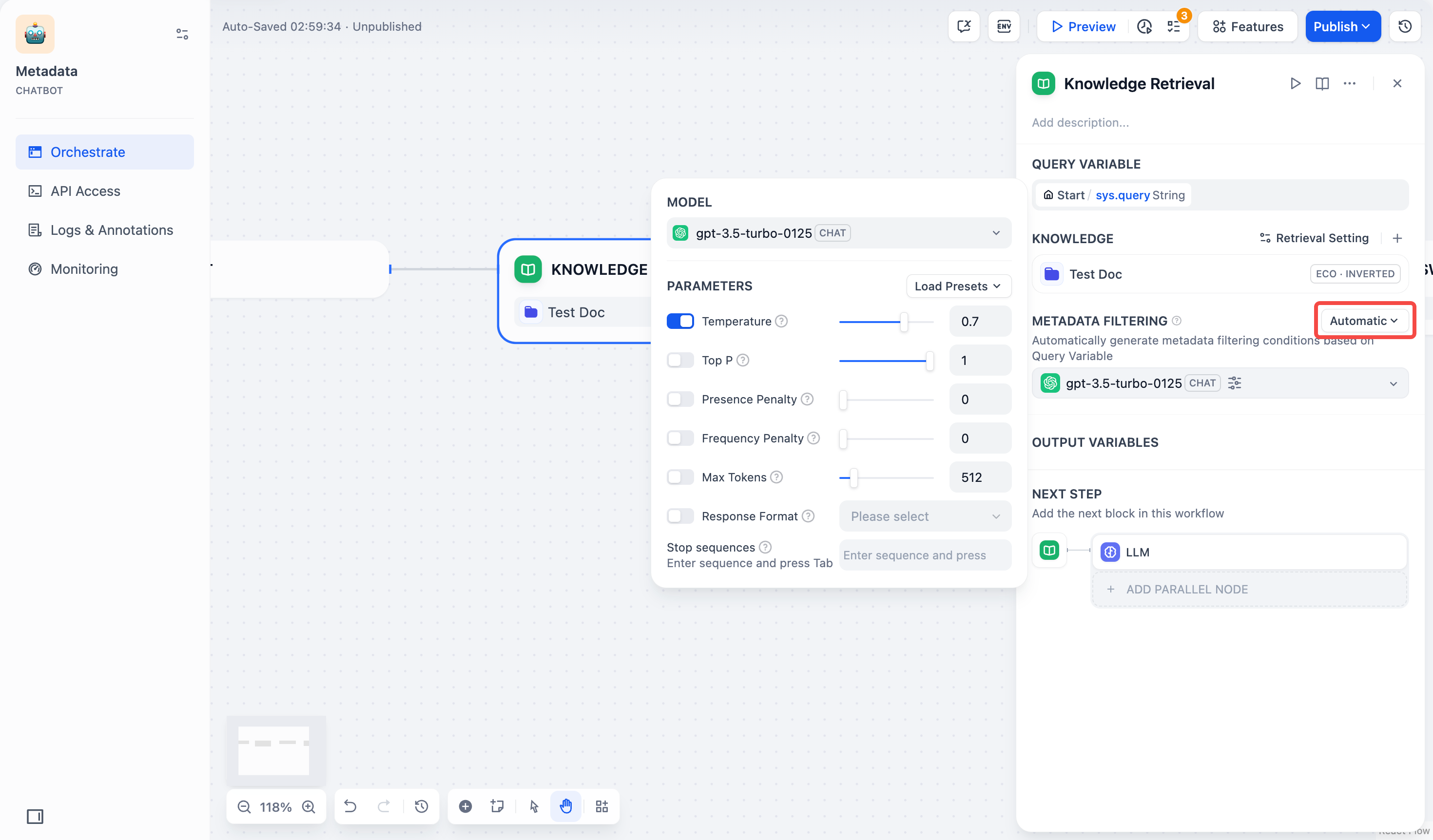
- 手动模式:用户可以手动配置筛选条件,自由设置筛选规则,适用于复杂的筛选需求。
-
如果你选择了 手动模式,请参照以下步骤配置筛选条件:
- 点击 条件 按钮,弹出配置框。
-
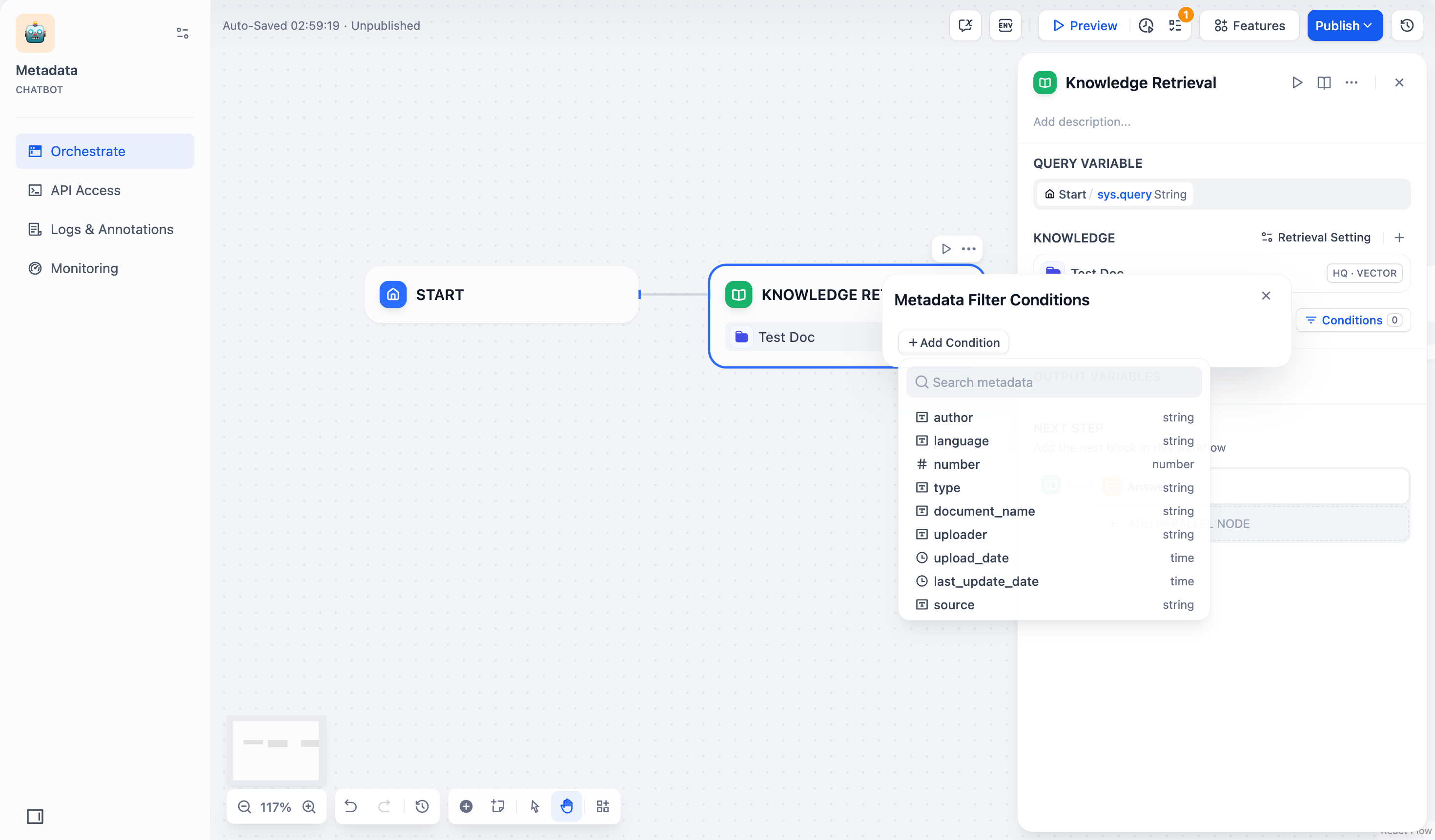
点击配置框中的 +添加条件 按钮:
- 可以从下拉列表中选择一个已选中知识库内的元数据字段,添加到筛选条件列表中。
如果你同时选择了多个知识库,下拉列表只会显示这些知识库共有的元数据字段。
- 可以在 搜索元数据 搜索框中搜索你需要的字段,添加到筛选条件列表中。
- 如果需要添加多条字段,可以重复点击 +添加条件 按钮。
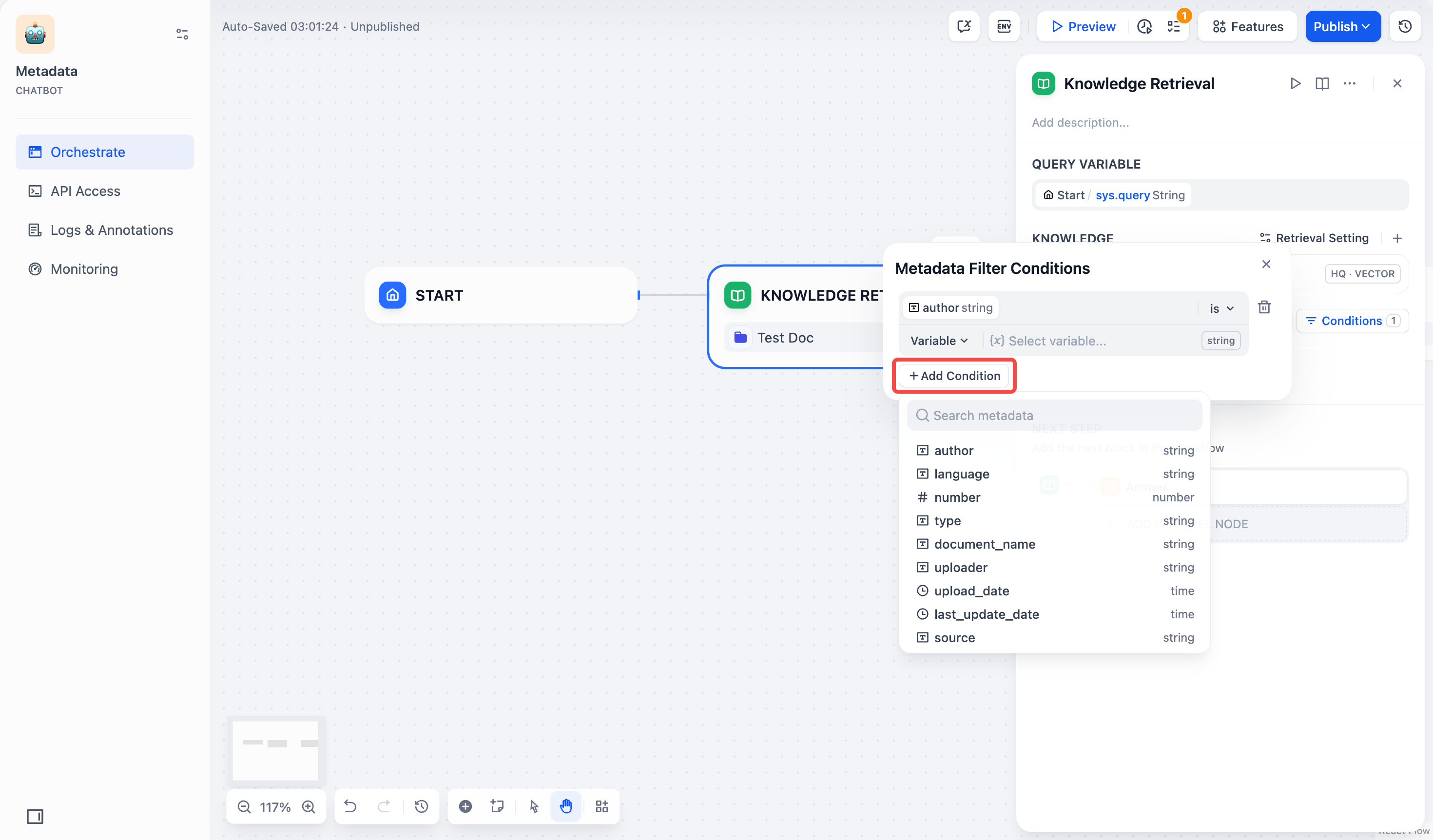
- 配置字段类型的筛选条件:
- 选择并添加元数据筛选值:
- 变量:选择 变量(Variable),并选择该 Chatflow/Workflow 中需要用于筛选文档的变量。
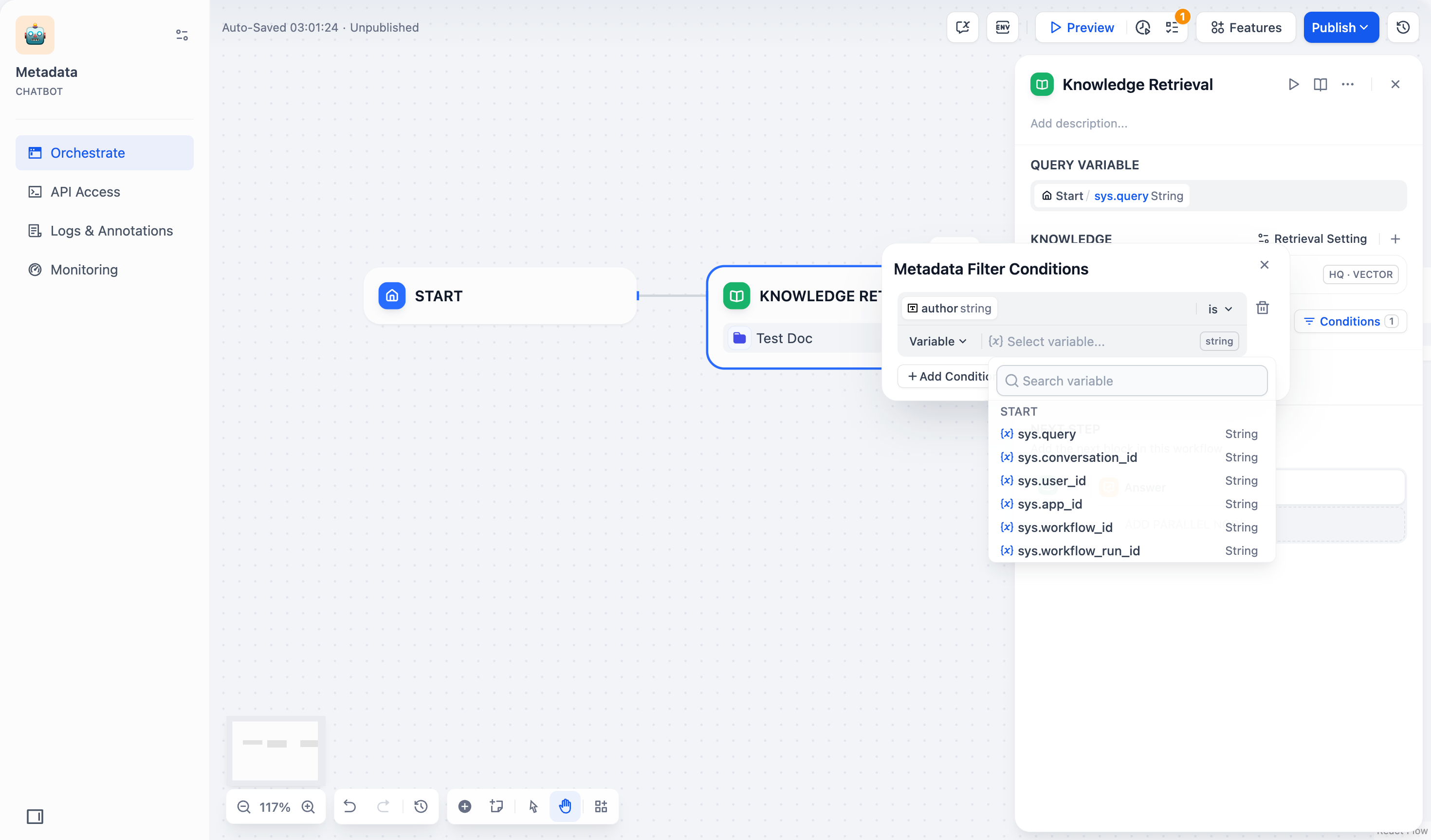
- 常量:选择 常量(Constant),并手动输入你需要的常量值。
时间 字段类型仅支持使用常量筛选文档。如果你选用时间字段筛选文档,系统会弹出时间选择器,供你选择具体的时间节点。
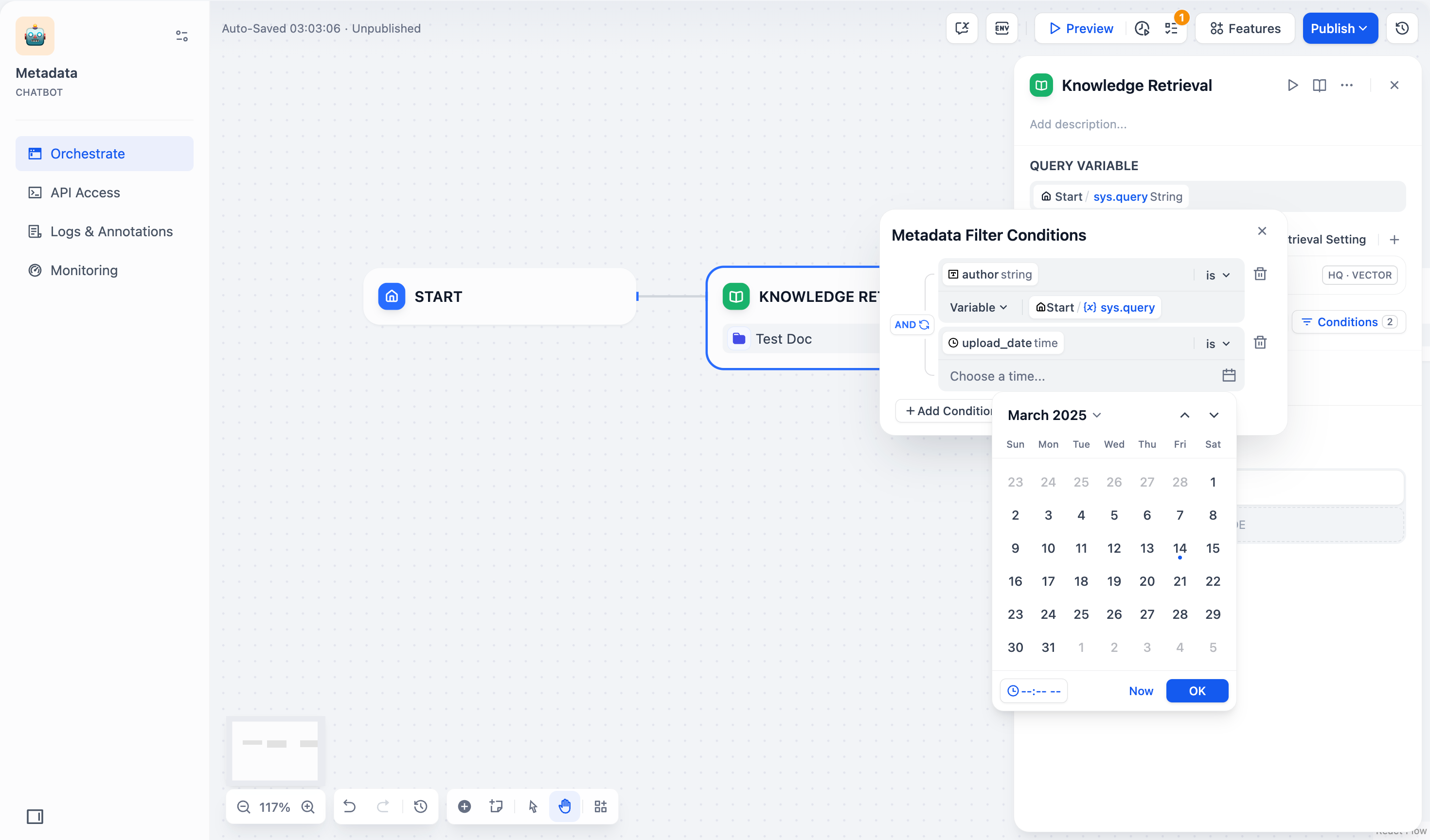
- 配置筛选条件之间的逻辑关系
AND或OR。AND:当一个文档满足所有筛选条件时,才能检索到该文档。OR:只要一个文档满足其中任意一个筛选条件,就可以检索到该文档。
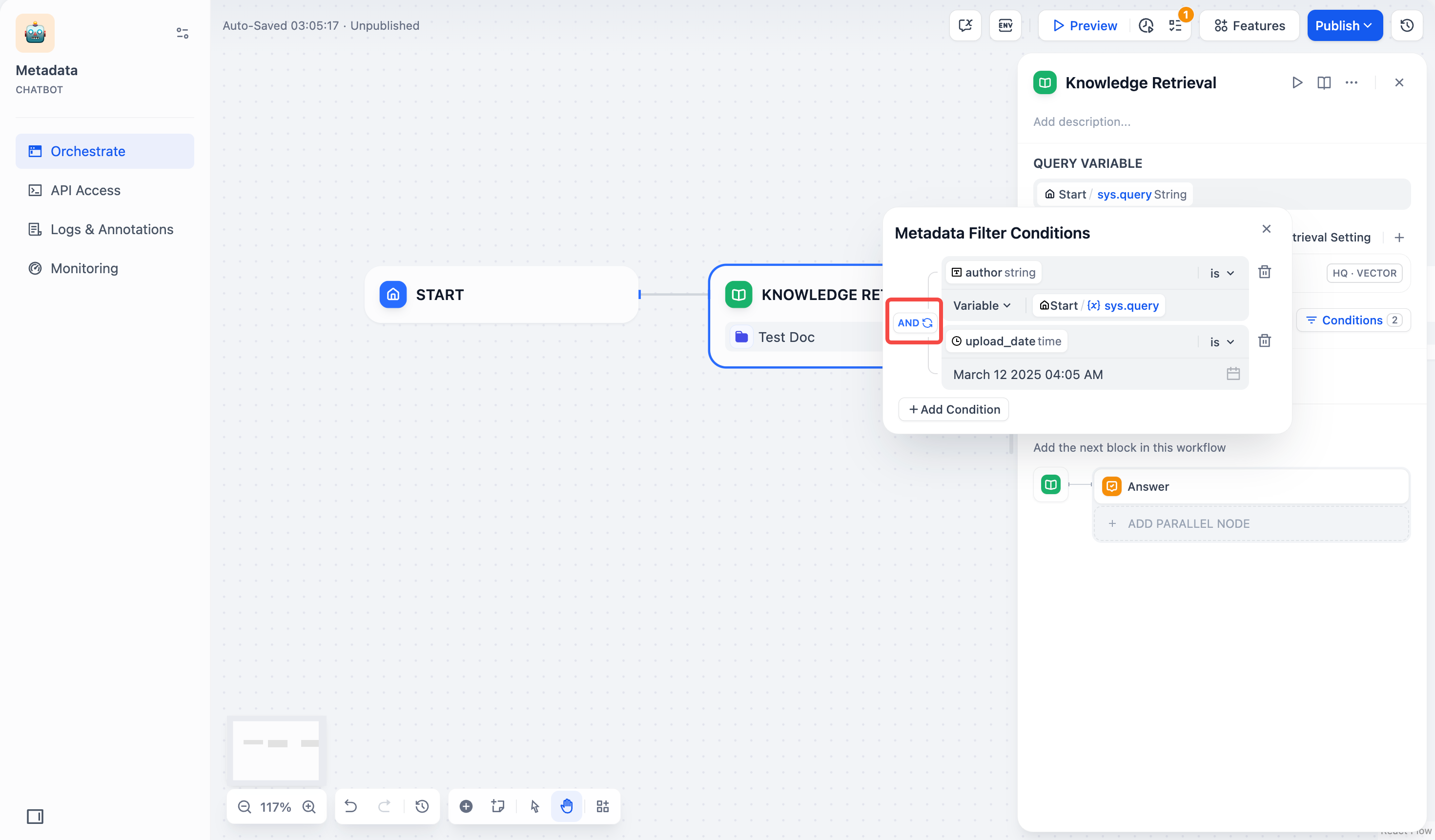
- 关闭弹窗,系统将自动保存你的选择。
聊天助手
在 聊天助手 中,元数据筛选 功能位于界面左下方的 上下文 板块下方,配置方法与 Chatflow/Workflow 中的操作一致。你可以按照相同的步骤配置元数据筛选条件。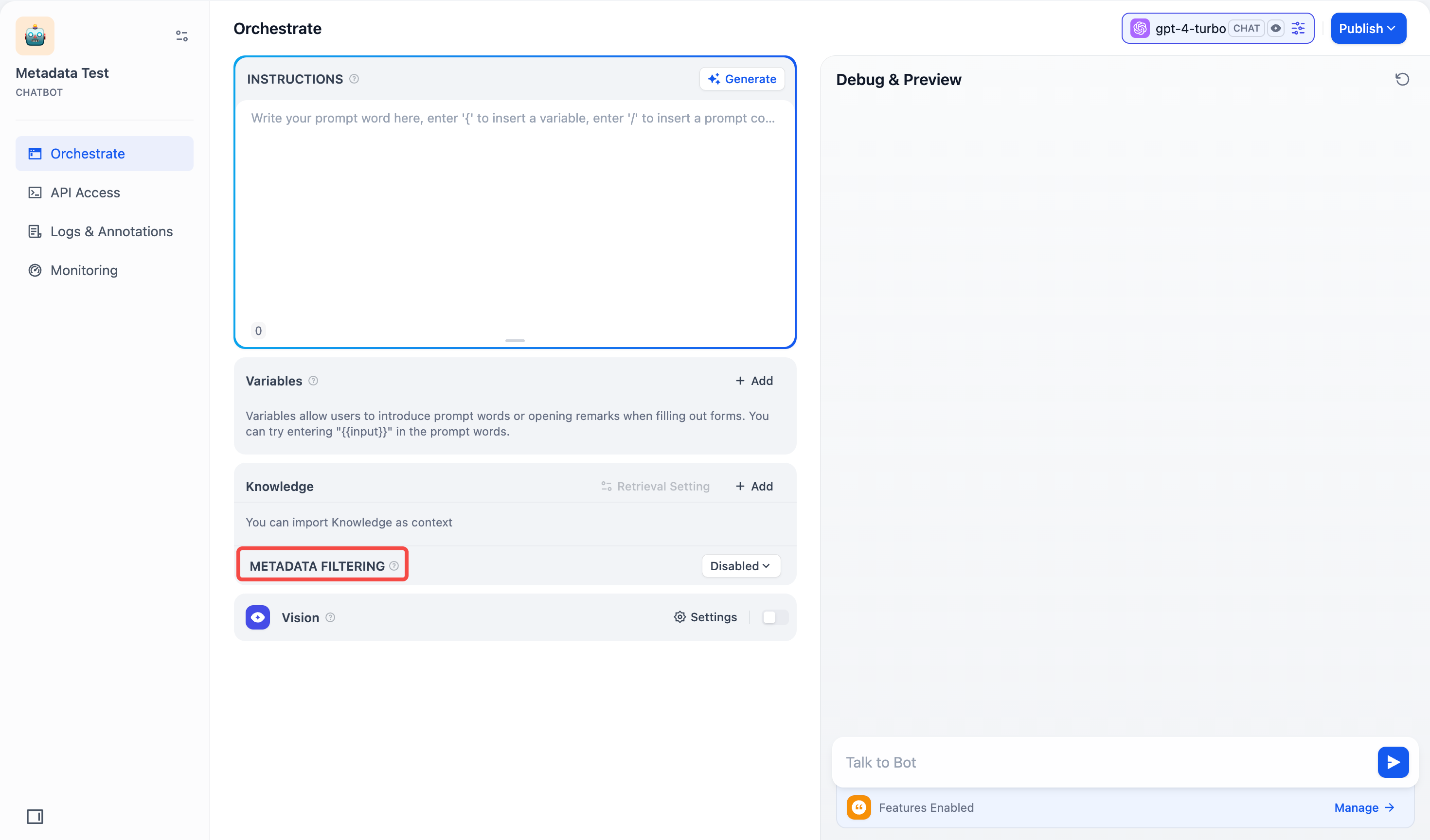
在知识库内查看已关联的应用
知识库将会在左侧信息栏中显示已关联的应用数量。将鼠标悬停至圆形信息图标时将显示所有已关联的 Apps 列表,点击右侧的跳转按钮即可快速查看对应的应用。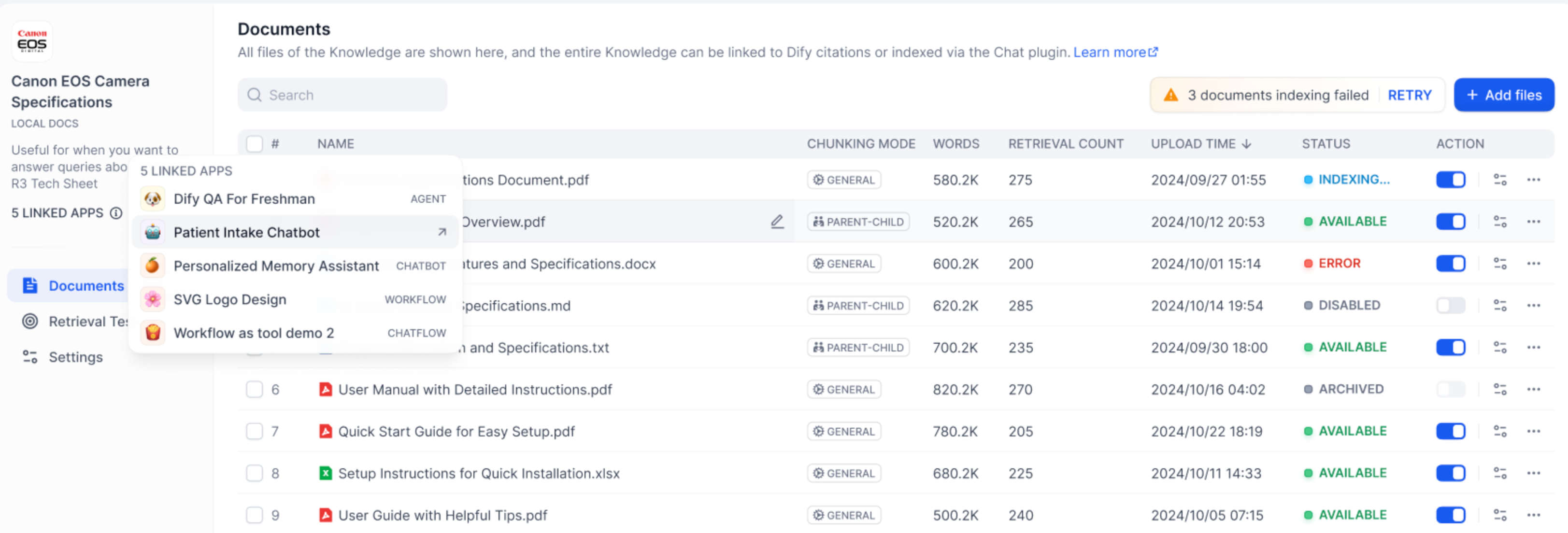
常见问题
- 如何选择多路召回中的 Rerank 设置?
- 为什么会出现找不到“权重设置”或要求必须配置 Rerank 模型等情况,应该如何处理?
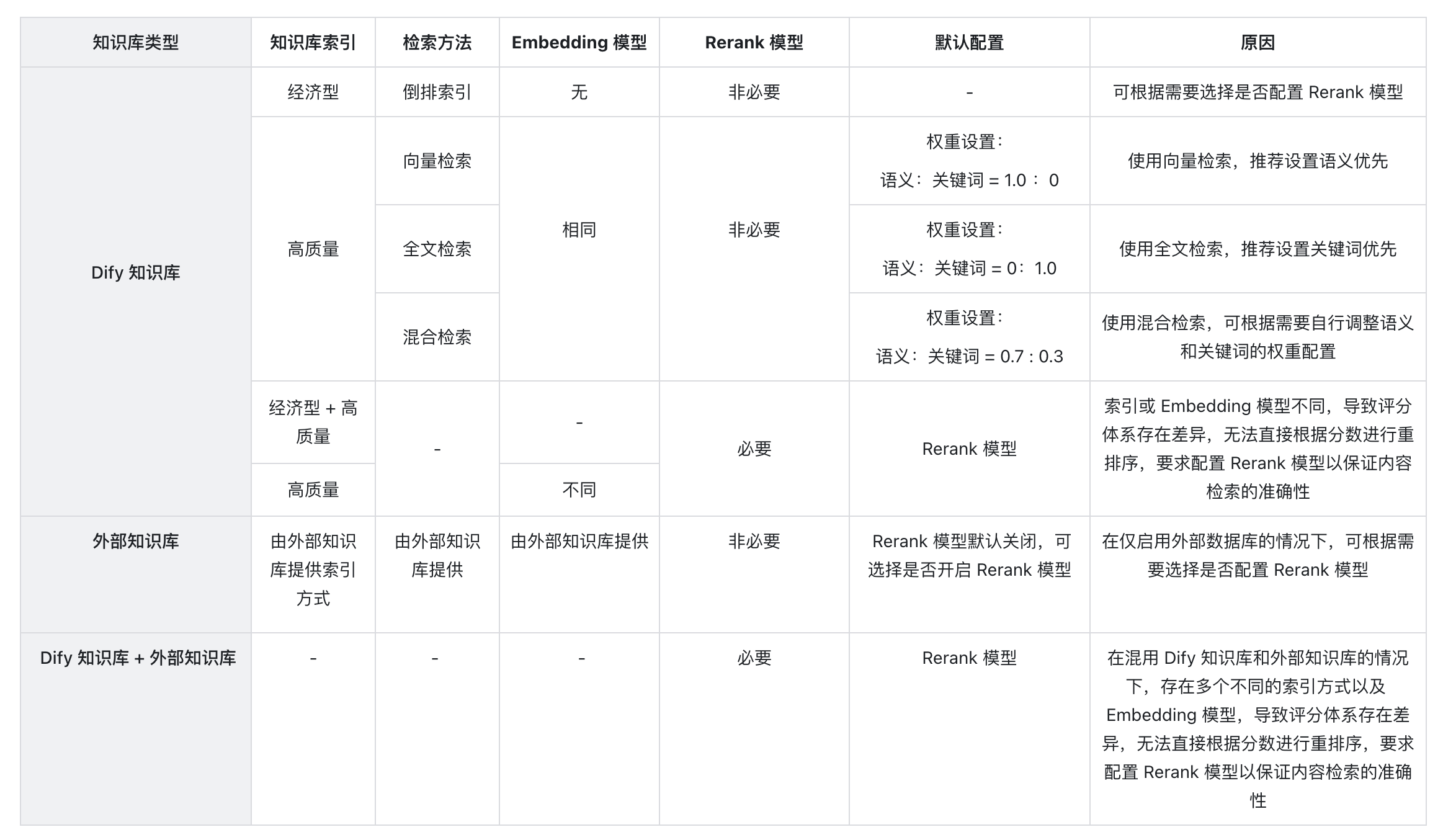
- 引用多个知识库时,无法调整“权重设置”,提示错误应如何处理?
- 为什么在多路召回模式下找不到“权重设置”选项,只能看到 Rerank 模型?