

イントロダクション
LLMベンダーとの接続が完了したら、次にベンダーの下でモデルのインテグレーションを行います。ここでは、全体のプロセスを理解するために、例としてXinferenceを使用し、段階的にベンダーのインテグレーションを行います。
注意: カスタムモデルの場合、各モデルのインテグレーションにはベンダー認証情報(API Keyなど)の記入が必要です。
事前定義モデルとは異なり、カスタムベンダーのインテグレーション時には常に以下の2つのパラメータが存在していますが、ベンダー yaml に定義する必要はありません。
 前述したように、ベンダーは
前述したように、ベンダーはvalidate_provider_credentialを実装する必要はなく、ユーザーが選択したモデルタイプとモデル名に基づいて、Runtimeが対応するモデル層のvalidate_credentialsを呼び出して検証を行います。
ベンダー yaml の作成
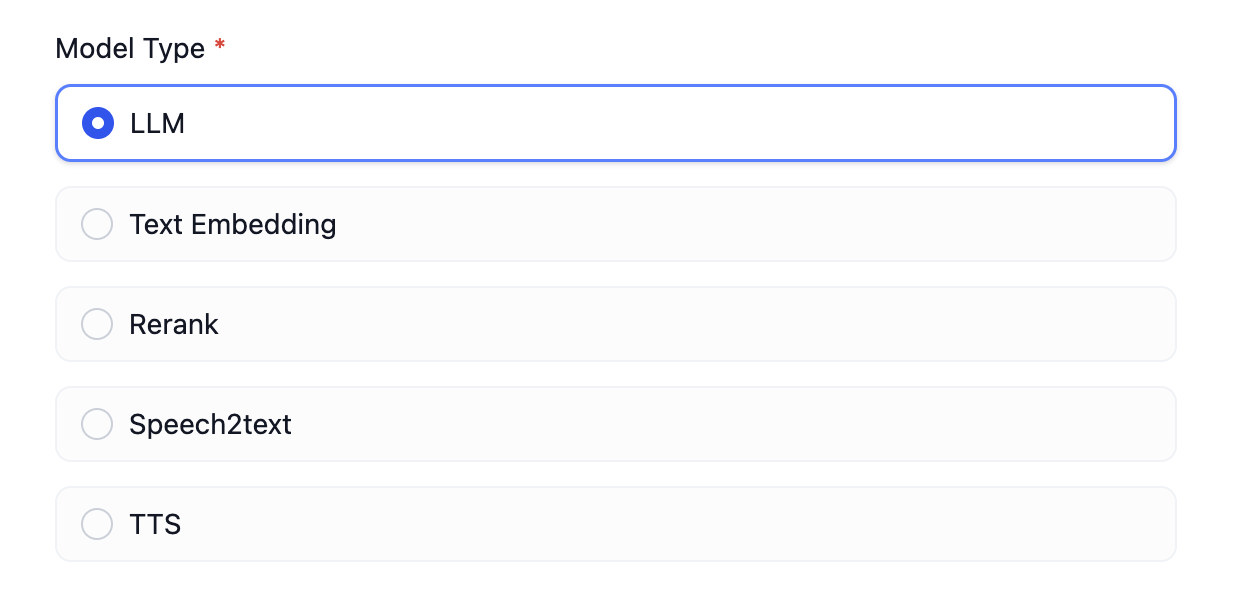
まず、インテグレーションを行うベンダーがどのタイプのモデルをサポートしているかを確認します。 現在サポートされているモデルタイプは以下の通りです:llmテキスト生成モデルtext_embeddingテキスト Embedding モデルrerankRerank モデルspeech2text音声からテキスト変換ttsテキストから音声変換moderationモデレーション
XinferenceはLLM、Text Embedding、Rerankをサポートしているため、xinference.yamlを作成します。
- 3つの異なるモデルをサポートするため、
model_typeを使用してこのモデルのタイプを指定する必要があります。3つのタイプがあるので、次のように記述します。
- 各モデルには
model_nameという独自の名称が必要なため、ここで定義してください。
- Xinferenceのローカルデプロイのアドレスを記入します。
- 各モデルには一意の model_uid があるため、ここで定義する必要があります。
モデルコードの作成
次に、llmタイプを例にとって、xinference.llm.llm.pyを作成します。
llm.py内で、Xinference LLM クラスを作成し、XinferenceAILargeLanguageModel(任意の名前)と名付けて、__base.large_language_model.LargeLanguageModel基底クラスを継承し、以下のメソッドを実装します:
-
LLM 呼び出し
LLM 呼び出しのコアメソッドを実装し、ストリームレスポンスと同期レスポンスの両方をサポートします。
実装時には、同期レスポンスとストリームレスポンスを処理するために2つの関数を使用してデータを返す必要があります。Pythonは
yieldキーワードを含む関数をジェネレータ関数として認識し、返されるデータ型は固定でジェネレーターになります。そのため、同期レスポンスとストリームレスポンスは別々に実装する必要があります。今回は以下のように実装します(例では簡略化されたパラメータを使用していますが、実際の実装では上記のパラメータリストに従って実装してください): -
必要なトークン数の予測計算
モデルが予測トークン数の計算インターフェースを提供していない場合、直接0を返すことができます。
直接0を返す必要がない場合は
self._get_num_tokens_by_gpt2(text: str)を使用して予測トークン数を取得することができます。このメソッドはAIModel基底クラスにあり、GPT2のTokenizerを使用して計算を行いますが、代替方法として使用されるものであり、正確ではないのであくまでも参考として使用してください。 -
モデルクレデンシャル検証
ベンダークレデンシャル検証と同様に、ここでは個々のモデルについて検証を行います。
-
モデルパラメータスキーマ
カスタムタイプとは異なり、yamlファイルでモデルがサポートするパラメータを定義していないため、動的にモデルパラメータのスキーマを生成する必要があります。
例えば、Xinferenceは
max_tokens、temperature、top_pの3つのモデルパラメータをサポートしています。 しかし、ベンダーによっては各モデルによってサポートしているパラメータが異なる場合があります。例えば、ベンダーOpenLLMはtop_kをサポートしていますが、全てのモデルがtop_kをサポートしているわけではありません。ここでは、例としてAモデルがtop_kをサポートし、Bモデルがtop_kをサポートしていない場合を考えます。その場合以下のように動的にモデルパラメータのスキーマを生成します: -
呼び出し時のエラーマッピング
モデル呼び出し時にエラーが発生した場合、Runtimeが指定する
InvokeErrorタイプにマッピングする必要があります。これにより、Difyはそれぞれのエラーに対して異なる後続処理を行うことができます。 Runtime Errors:InvokeConnectionError呼び出し接続エラーInvokeServerUnavailableError呼び出しサービスが利用不可InvokeRateLimitError呼び出し回数制限に達したInvokeAuthorizationError認証エラーInvokeBadRequestError不正なリクエストパラメータ