

定義
ナレッジベースからユーザーの質問に関連するテキスト内容を検索し、それを下流のLLMノードのコンテキストとして使用することができます。シナリオ
一般的なシナリオ:外部データ/ナレッジに基づくAI質問応答システム(RAG)の構築。RAGに関してより知りたい方は基本概念をご覧ください。 下図は最も基本的なナレッジベース質問応答アプリケーションの例です。このプロセスの実行ロジックは、ユーザーの質問がLLMノードに渡される前に、ナレッジ検索ノードでユーザーの質問に最も関連するテキスト内容を検索し、召喚することです。その後、LLMノード内でユーザーの質問と検索されたコンテキストを一緒に入力し、LLMが検索内容に基づいて質問に答えるようにします。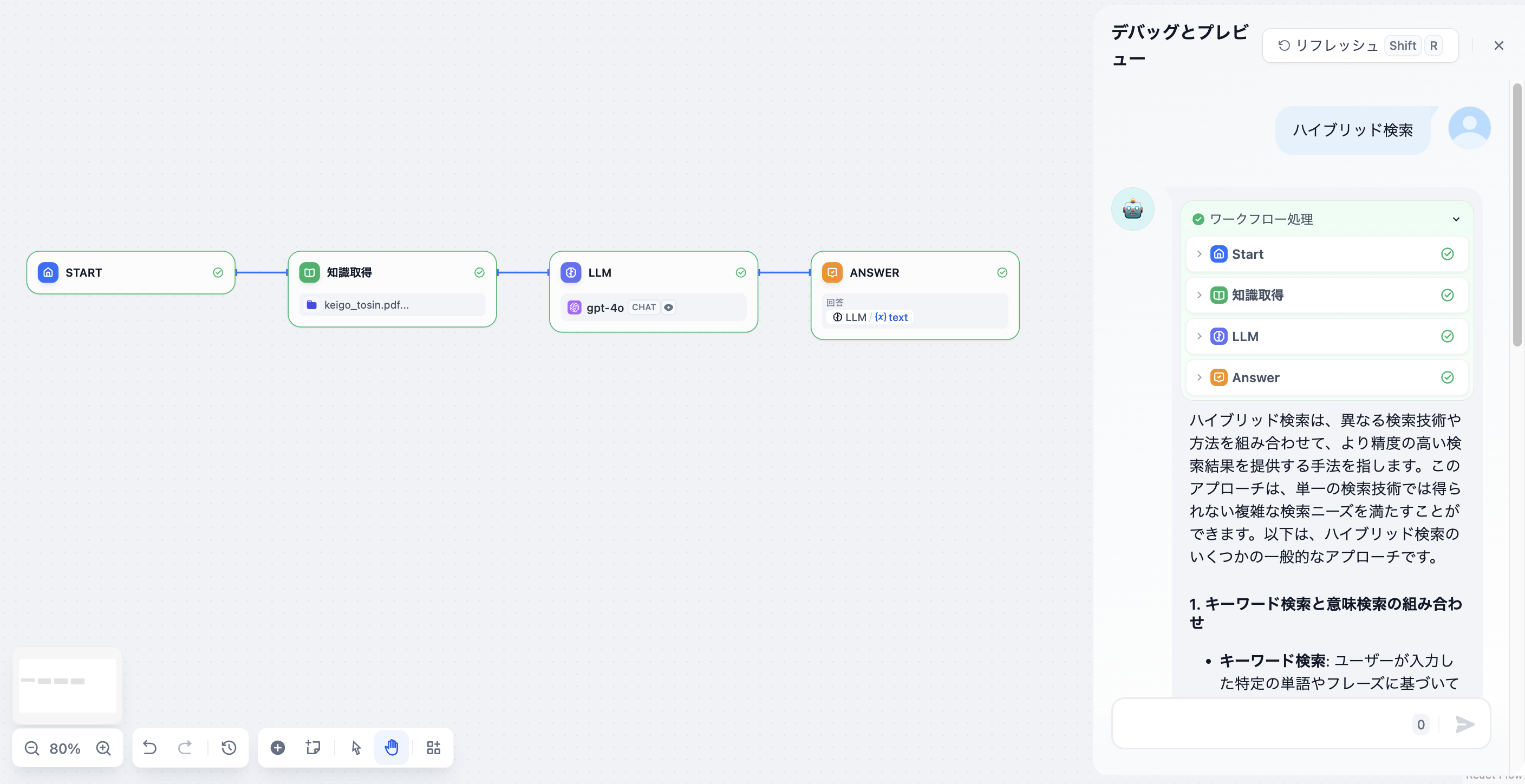
ナレッジベース質問応答アプリケーションの例
設定方法
設定プロセス:- クエリ変数を選択し、ナレッジベース内の関連するテキストセグメントを検索するための入力として使用します。一般的な対話型アプリケーションでは、開始ノードの
sys.queryをクエリ変数として使用します。ナレッジ ベースが受け入れることができる最大クエリ コンテンツは 200 文字です。 - 検索するナレッジベースを選択します。オプションとして選択可能なナレッジベースは、Difyナレッジベース内で事前に作成する必要があります。
- リコールモードとナレッジベース設定を設定します。
- 下流ノードを接続し設定します。一般的にはLLMノードです。
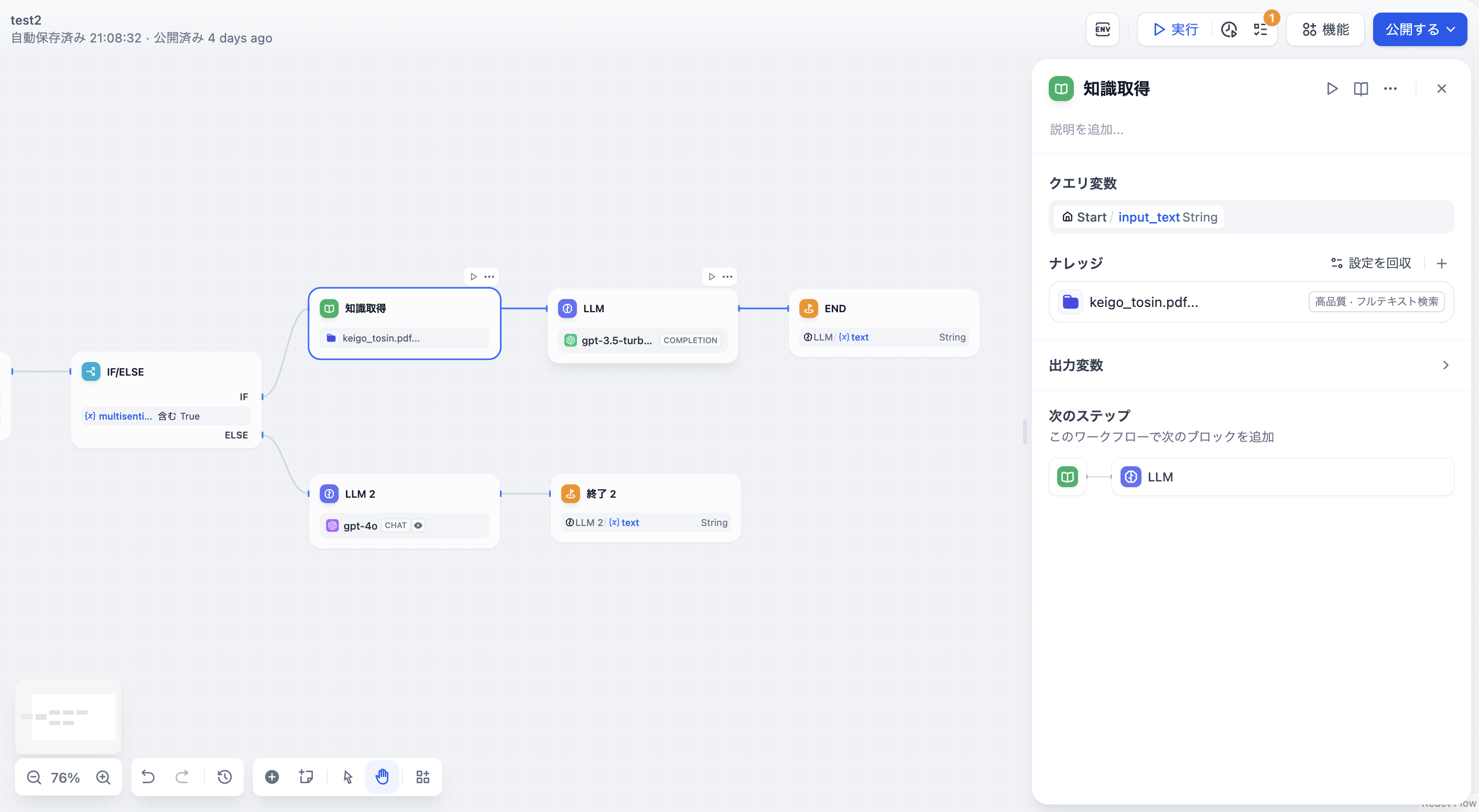
ナレッジ検索の設定

出力変数
resultは、ナレッジベースから検索された関連テキストセグメントです。この変数のデータ構造には、セグメント内容、タイトル、リンク、アイコン、メタデータ情報が含まれています。
下流ノードの設定
一般的な対話型アプリケーションでは、ナレッジベース検索の下流ノードは通常LLMノードであり、ナレッジ検索の出力変数resultはLLMノード内のコンテキスト変数に関連付けられて設定されます。関連付け後、プロンプトの適切な位置にコンテキスト変数を挿入することができます。
コンテキスト変数は、LLMノード内で定義された特殊な変数タイプで、プロンプト内に外部検索されたテキスト内容を挿入するために使用されます。
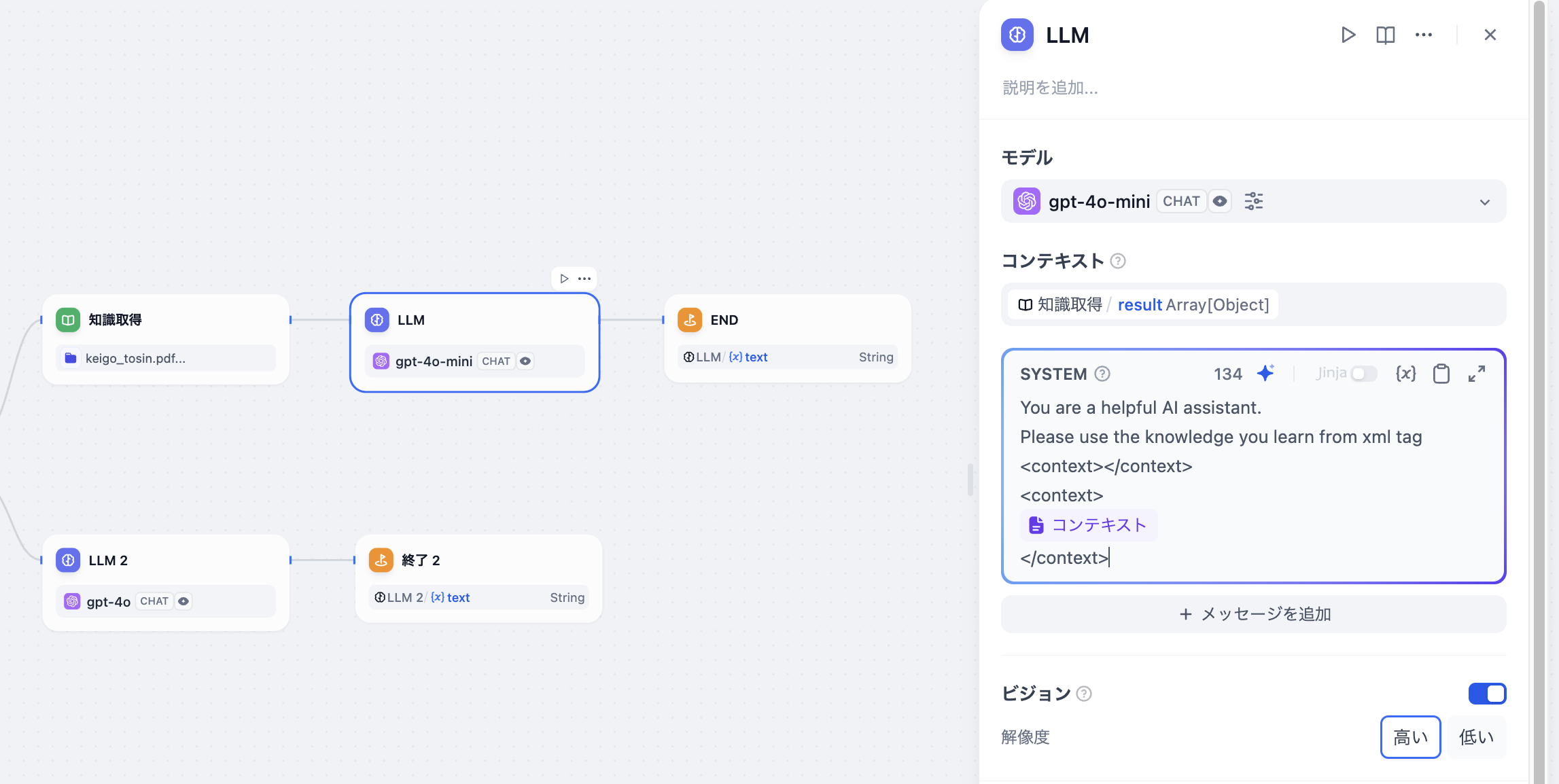
下流LLMノードの設定