

紹介
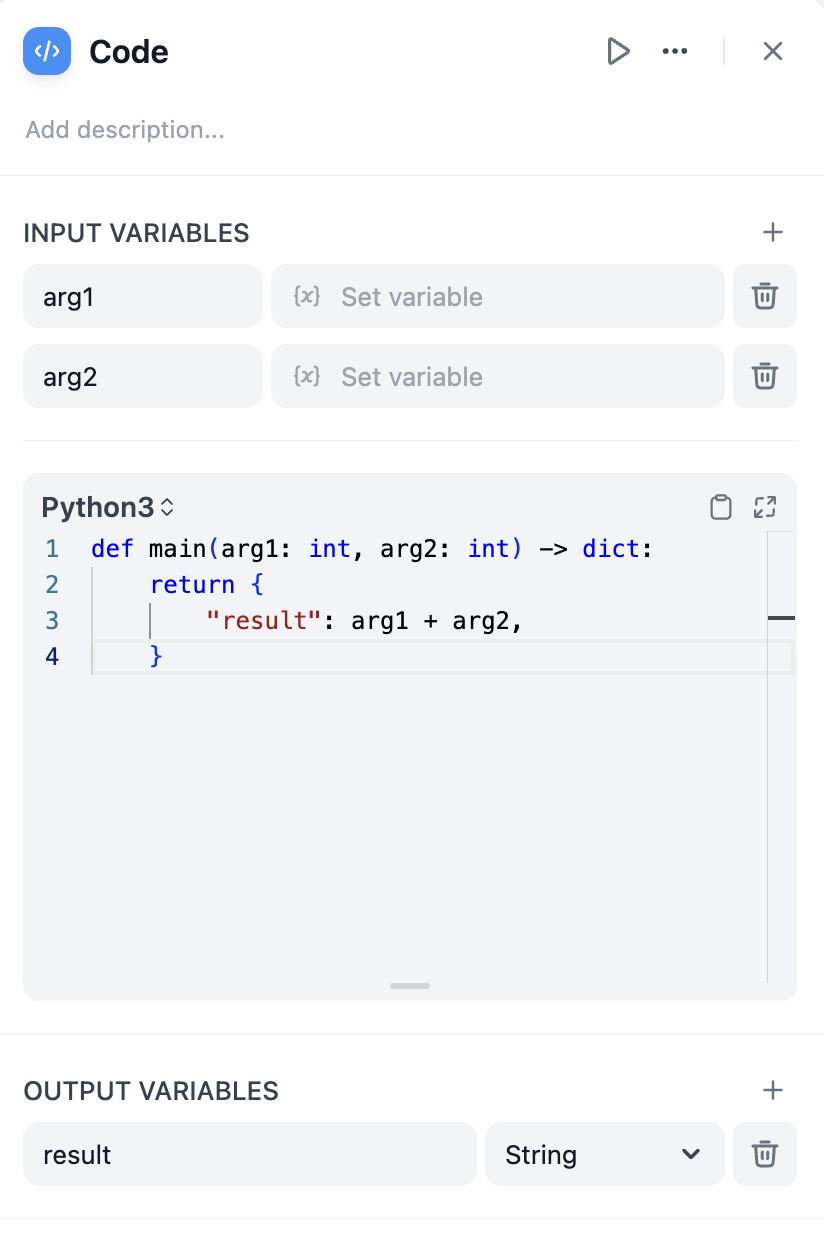
コードノードを使用すると、カスタムのPythonまたはJavascriptスクリプトをワークフローに埋め込み、組み込みノードでは実現できない方法で変数を操作できます。コードノードは、算術、JSON変換、テキスト処理などのシナリオに適しており、ワークフローを簡素化できます。 コードノードで他のノードの変数を使用するには、まず入力変数でその変数を選択してから、コード内で参照する必要があります。
使用シナリオ
コードノードを使用することで、構造化データの処理、数学計算、データの連結などの操作を実現できます。構造化データ処理
ワークフローでは、JSON文字列の解析、抽出、変換など、非構造化データを頻繁に処理する必要があります。最も典型的な例は、HTTPノードのデータ処理です。一般的なAPIの戻り値の構造では、データが複数階層のJSONオブジェクトにネストされている可能性があり、その中から特定のフィールドを抽出する必要があります。コードノードは、これらの操作を完了するのに役立ちます。 例えば、以下のコードを使用して、HTTPノードから返されたJSON文字列からdata.name フィールドを抽出できます。
数学計算
ワークフローで複雑な数学計算(複雑な数式の計算やデータの統計分析など)が必要な場合も、コードノードを使用できます。 例えば、次のコードを使用して、配列の二乗和を計算できます。データの結合
複数のデータソース(複数のナレッジ検索、データ検索、API呼び出しなど)を連結する必要がある場合、コードノードを使用してこれらのデータソースを統合できます。 例えば、次のコードを使用して、2つのナレッジベースのデータを統合できます。ローカルデプロイ
ローカル環境にデプロイしているユーザーの場合、悪意のあるコードが実行されないようにサンドボックスサービス(Sandbox)を起動する必要があります。 サンドボックスサービスの起動にはDockerが必要です。docker-compose を使用して直接サービスを起動できます。お使いのシステムに Docker Compose V2 がインストールされている場合は、
docker-compose の代わりに docker compose を使用してください。バージョン情報は $ docker compose version で確認できます。
詳細については、Docker 公式ドキュメント をお読みください。セキュリティポリシー
Python3とJavascriptのいずれであっても、その実行環境は安全性を確保するために厳密に隔離(サンドボックス化)されています。これにより、ファイルシステムへの直接アクセス、ネットワークリクエストの実行、OSレベルのコマンドの実行など、システムリソースを大量に消費する可能性がある機能を使用することはできません。これらの制限により、コードの安全な実行が保証され、システムリソースの過剰消費が防止されます。高度な機能
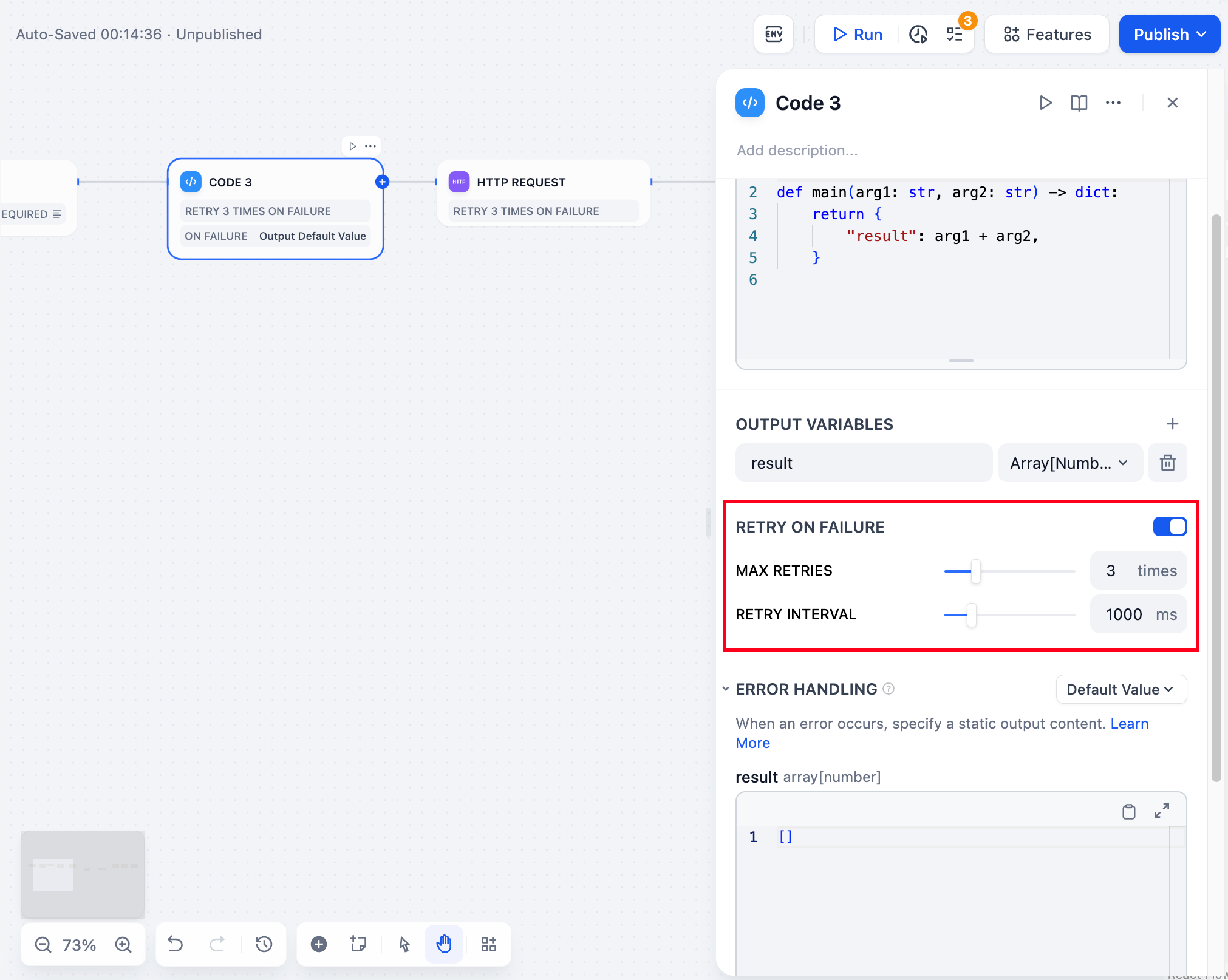
エラーリトライ
ノードで発生する一部の例外的な状況については、通常、ノードを再実行することで解決できます。エラーリトライ機能を有効にすると、ノードはエラー発生時に事前に設定されたポリシーに従って自動的にリトライします。 最大リトライ回数と各リトライの間隔を調整できます。- 最大リトライ回数は10回です
- 最大リトライ間隔は5000msです
例外処理
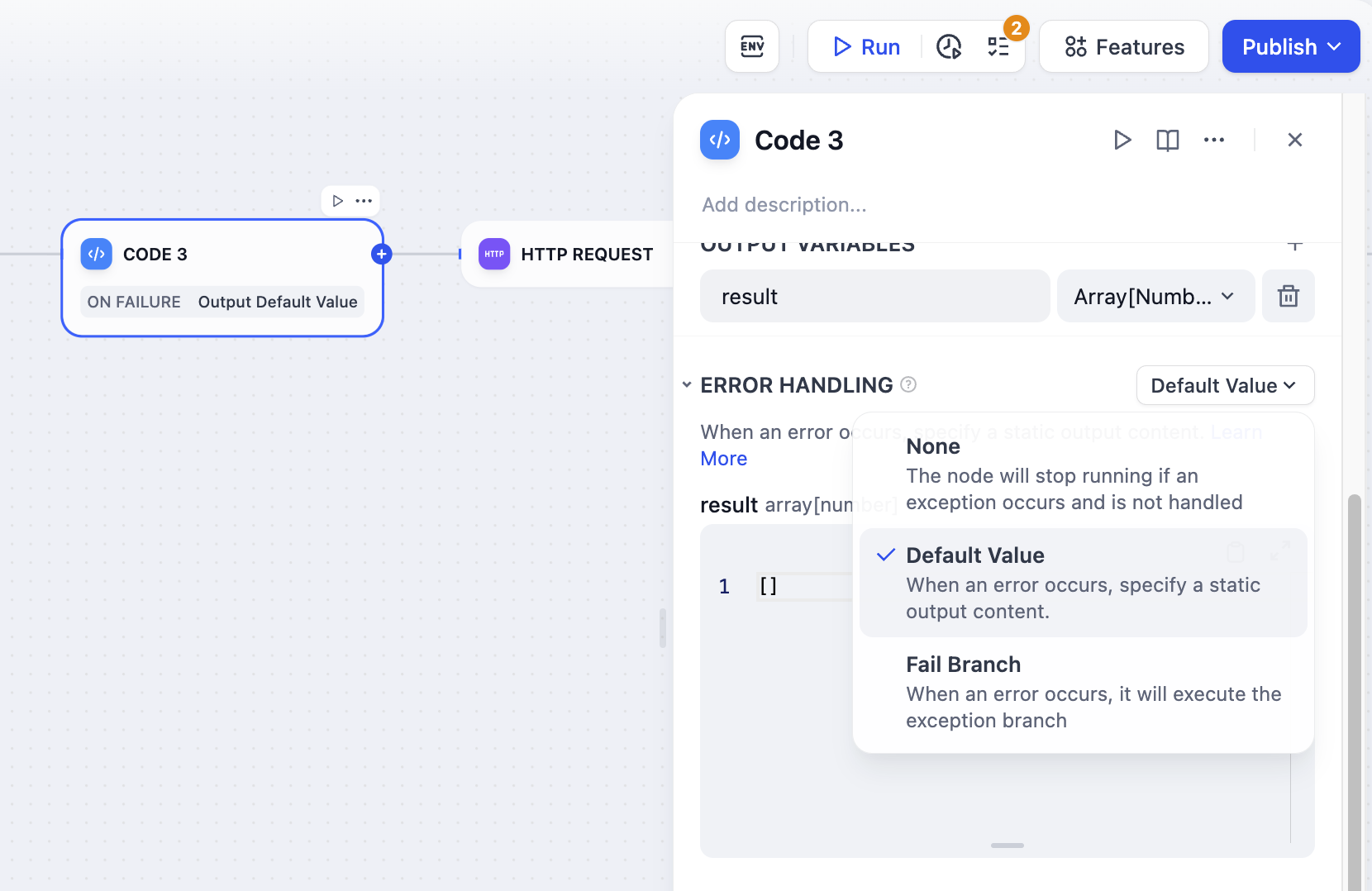
コードノードが情報を処理する際に、コードの実行例外が発生する可能性があります。以下の手順に従って例外分岐を設定することで、ノードで例外が発生した際に代替案を有効にし、プロセス全体の中断を避けることができます。- コードノードで 例外処理 を有効にします。
- 例外処理のプランを選択し、設定します。
よくある質問
コード ノードにコードを入力した後にコードを保存できないのはなぜですか? コードに危険な動作が含まれていないか確認してください。例:- 不正なファイル アクセス: コードは、ユーザー アカウント情報を保存する Unix/Linux システムの重要なシステム ファイルである
/etc/passwdファイルを読み取ろうとしました。 - 機密情報の漏洩:
/etc/passwdファイルには、ユーザー名、ユーザー ID、グループ ID、ホーム ディレクトリのパスなど、システム ユーザーの重要な情報が含まれています。直接アクセスすると情報が漏洩する可能性があります。
コード修正
前回実行時のcurrent_code と error_message 変数を利用して、自動でコードを修正することができます。
コードノードの実行が失敗した場合:
- システムはコードとエラーメッセージをキャプチャします。
- これらの情報はコンテキスト変数としてプロンプトに渡されます。
- システムはレビューと再試行のために新しいバージョンのコードを生成します。
修正プロンプト
次のように、修正用のプロンプトをカスタマイズできます。プロンプトエディタで、変数挿入メニュー(
/または{)を使用して変数を挿入します。
コンテキスト変数
自動コード修正を有効にするには、プロンプトで以下のコンテキスト変数を参照してください。current_code:このノードで前回実行されたコード。error_message:前回の実行が失敗した場合はエラーメッセージ、成功した場合は空になります。
last_run変数は、前回の入力/出力を参照するために使用できます。- 上記の変数に加えて、必要に応じて任意の前段ノードの出力変数を参照することもできます。
バージョン管理
バージョン管理により、手動でのコピー&ペースト作業が減り、ワークフロー内で直接コードを繰り返しデバッグできるようになります。- 修正が試みられるたびに、個別のバージョンとして保存されます(例:バージョン1、バージョン2)。
- 結果表示エリアのドロップダウンメニューから、異なるバージョンを切り替えることができます。