

このドキュメントは AI によって自動翻訳されています。不正確な部分がある場合は、英語版 を参照してください。
1 ナレッジベースの引用プロセス
ナレッジベースは、大言語モデルに対して外部知識を提供し、ユーザーの質問に正確に回答するために使用されます。Dify のすべてのアプリタイプ内で作成されたナレッジベースを関連付けることができます。 チャットボットを例にすると、以下の手順で進めます:- ナレッジ にアクセスし、すぐに使えるナレッジベース を作成してファイルをアップロードします。
- スタジオ にアクセスし、アプリを作成して チャットボット を選択します。
- コンテキスト に進んで 追加 をクリックし、作成済みのナレッジベースを選択します。
- メタデータフィルタリング を使用して、ナレッジベース内のドキュメント検索を絞り込みます。
- コンテキスト設定 > 検索設定 で 検索設定 を構成します。
- 機能を追加 で 引用と帰属 を有効にします。
- デバッグとプレビュー で、ナレッジベースに関連するユーザーの質問を入力してデバッグします。
- デバッグが完了したら、公開 ボタンをクリックして、自社のナレッジベースに基づく AI アプリケーションを公開します。
ナレッジベースの関連付けと検索モードの設定
複数のナレッジベースを利用するアプリケーションでは、検索されるコンテンツの精度を高めるために検索モードを設定することが重要です。ナレッジベースの検索モードを設定するには、コンテキスト > 検索設定 > Rerank 設定 に進みます。検索設定
複数リコールモードでは、検索器はアプリに関連付けられたすべてのナレッジベースから、ユーザーの問題に関連するテキスト内容を検索します。そして、複数リコールの関連文書結果を統合します。以下は複数リコールモードの技術フローチャートです: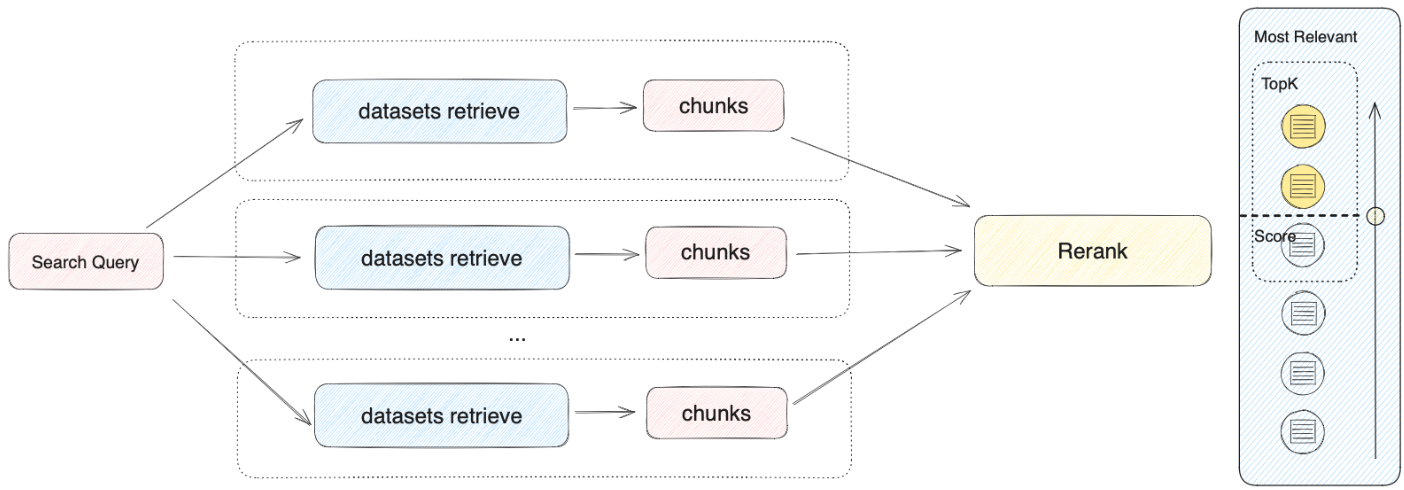
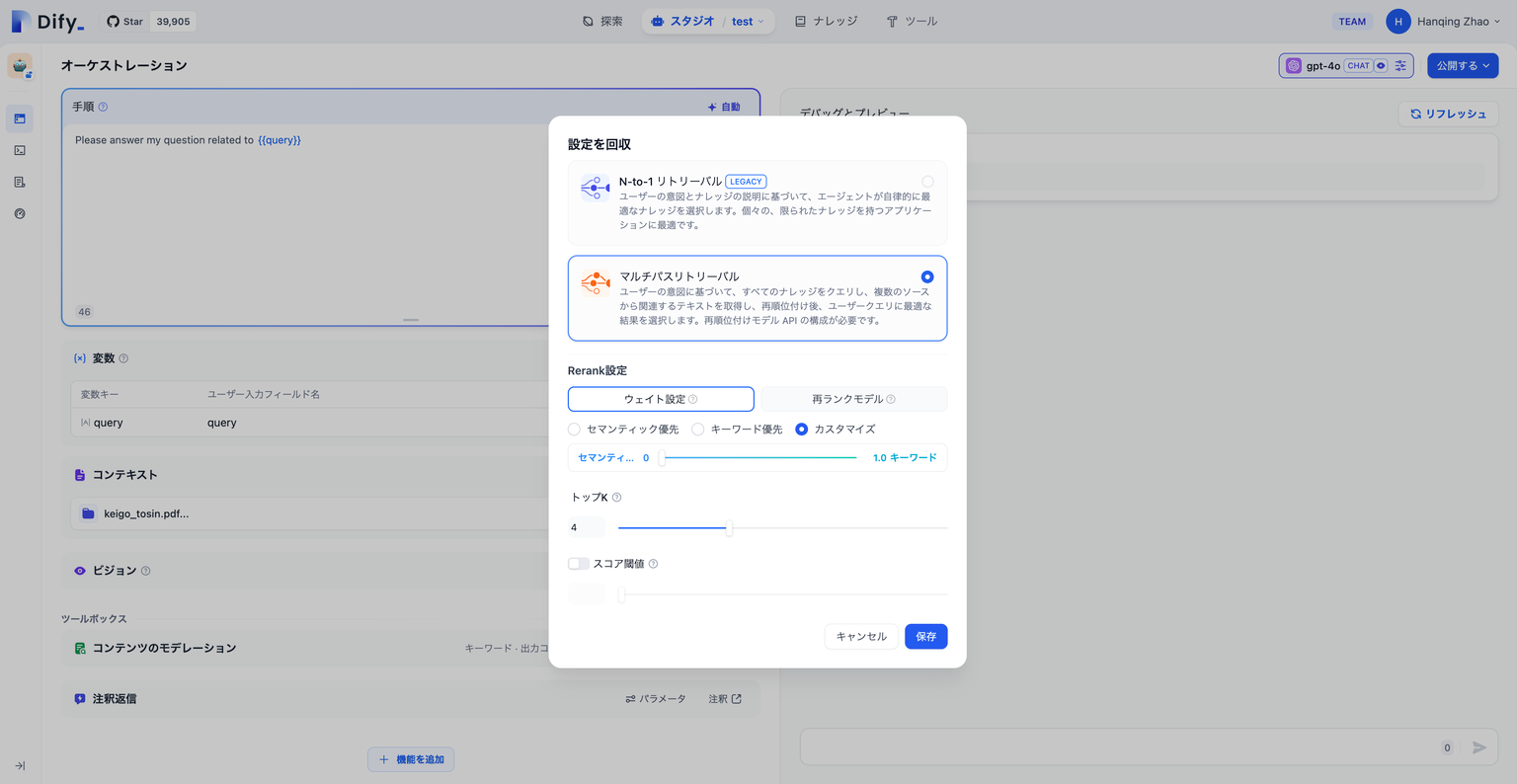
重み設定
この設定には外部の Rerank モデルの構成は不要で、コンテンツの再並べ替えに 追加コストは発生しません。セマンティクスまたはキーワードの重み比率を設定します。- セマンティック値が 1 の場合 セマンティック検索モードが有効になります。このモードでは、埋め込みモデルを利用して、クエリに正確な単語がナレッジベースに存在しない場合でも、ベクトル距離を計算することで検索の精度を向上させ、適切なコンテンツを返すことができます。また、複数言語のコンテンツを扱う場合には、セマンティック検索が異なる言語間の意味を把握し、より正確なクロス言語検索結果を提供します。
- キーワード値が 1 の場合 この場合、キーワード検索モードが有効になります。ユーザーが入力した情報テキストがナレッジベース全体と一致し、ユーザーが正確な情報や用語を把握している場合に適しています。この方法は計算リソースを少なく消費し、大量の文書を迅速に検索するのに適しています。
- カスタムキーワードとセマンティックの重み セマンティック検索またはキーワード検索モードのいずれかを選択する代わりに、柔軟なカスタム重み設定も利用可能です。両者の重みを調整し続けることで、ビジネスシナリオに最も適した重み比率を見つけることができます。
- TopK ユーザーの質問に最も類似したテキストセグメントを選択するために使用されます。システムはモデルの選択に基づいてコンテキストウィンドウサイズを動的に調整し、セグメントの数を増やします。数値が高いほど、リコールされるテキストセグメントの数が増加します。
- スコアの閾値 テキストセグメントの選択に使用される類似性の閾値を設定します。ベクトル検索の類似性スコアは、設定したスコアを超える必要があり、数値が高いほどリコールされるテキストの数が減少します。
メタデータを使用して知識をフィルタリングする
Chatflow/Workflow
Chatflow/Workflow の知識検索 ノードでは、メタデータフィルタリング 機能を使用して文書を正確に検索できます。この機能は、文書のメタデータフィールド(タグ、カテゴリ、アクセス権限など)に基づいて検索結果を最適化するのに役立ちます。 設定手順-
フィルタリングモードを選択する
- 無効モード(デフォルト):メタデータフィルタリング機能を無効にし、フィルタリング条件を設定しません。
- 自動モード:システムは知識検索ノードに渡されるクエリ変数に基づいてフィルタリング条件を自動的に設定します。簡単なフィルタリング要件に適しています。
自動モードを有効にした後も、モデル 欄で文書検索タスクを実行するための適切な大規模モデルを選択する必要があります。
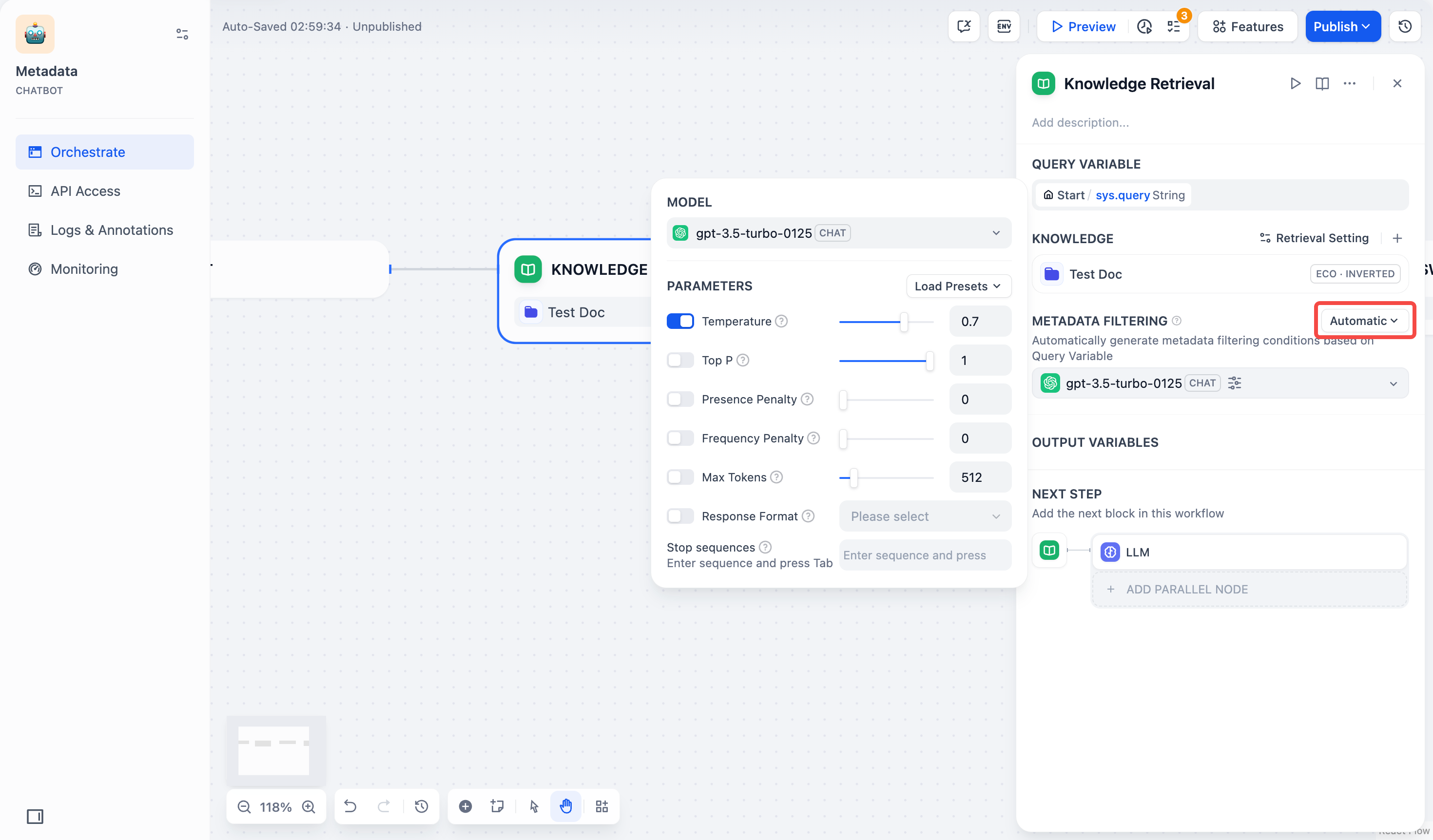
- 手動モード:ユーザーが手動でフィルタリング条件を設定し、フィルタリングルールを自由に設定できます。複雑なフィルタリング要件に適しています。
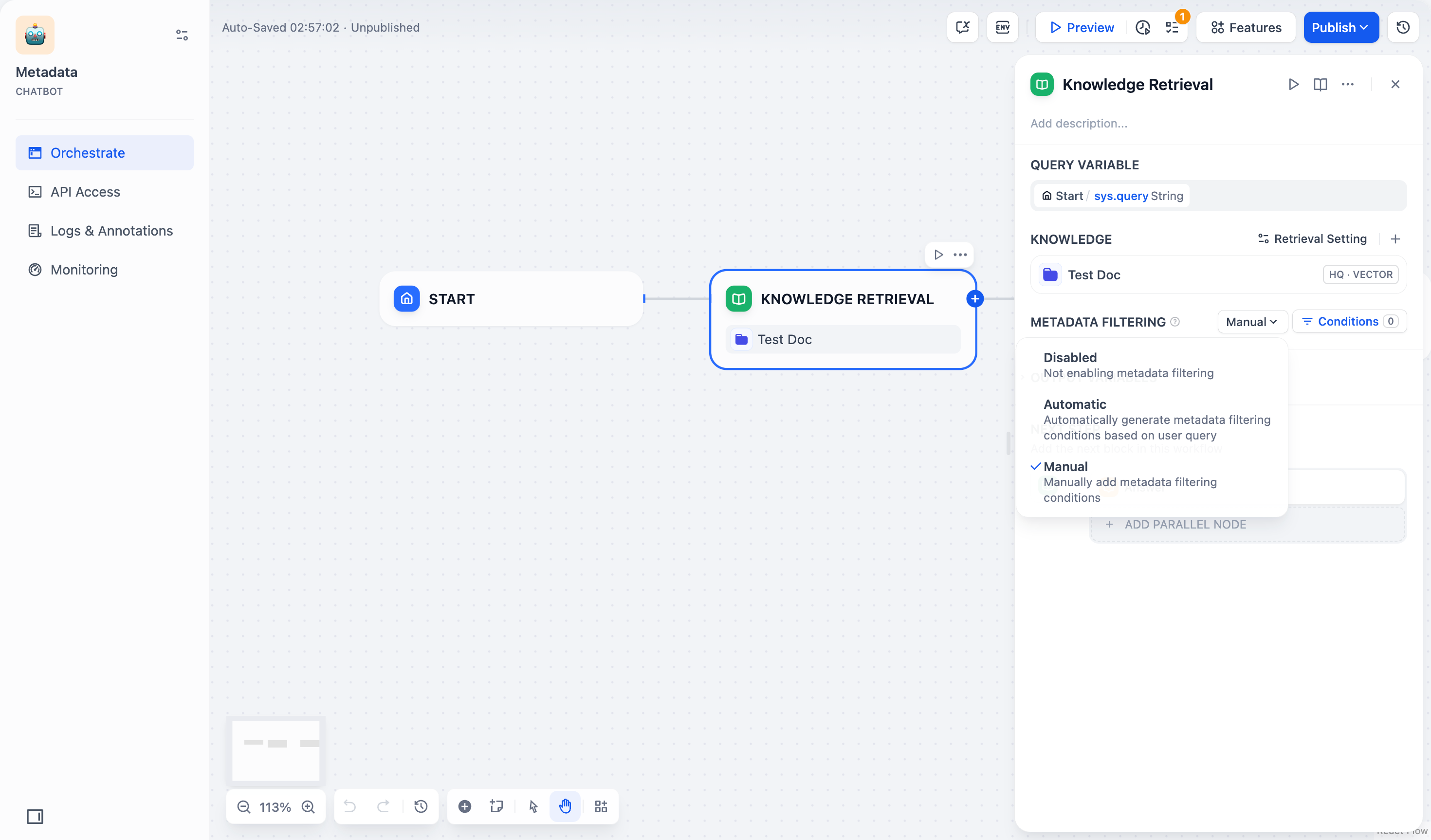
-
手動モード を選択した場合は、以下の手順でフィルタリング条件を設定してください:
- 条件 ボタンをクリックすると、設定ボックスが表示されます。
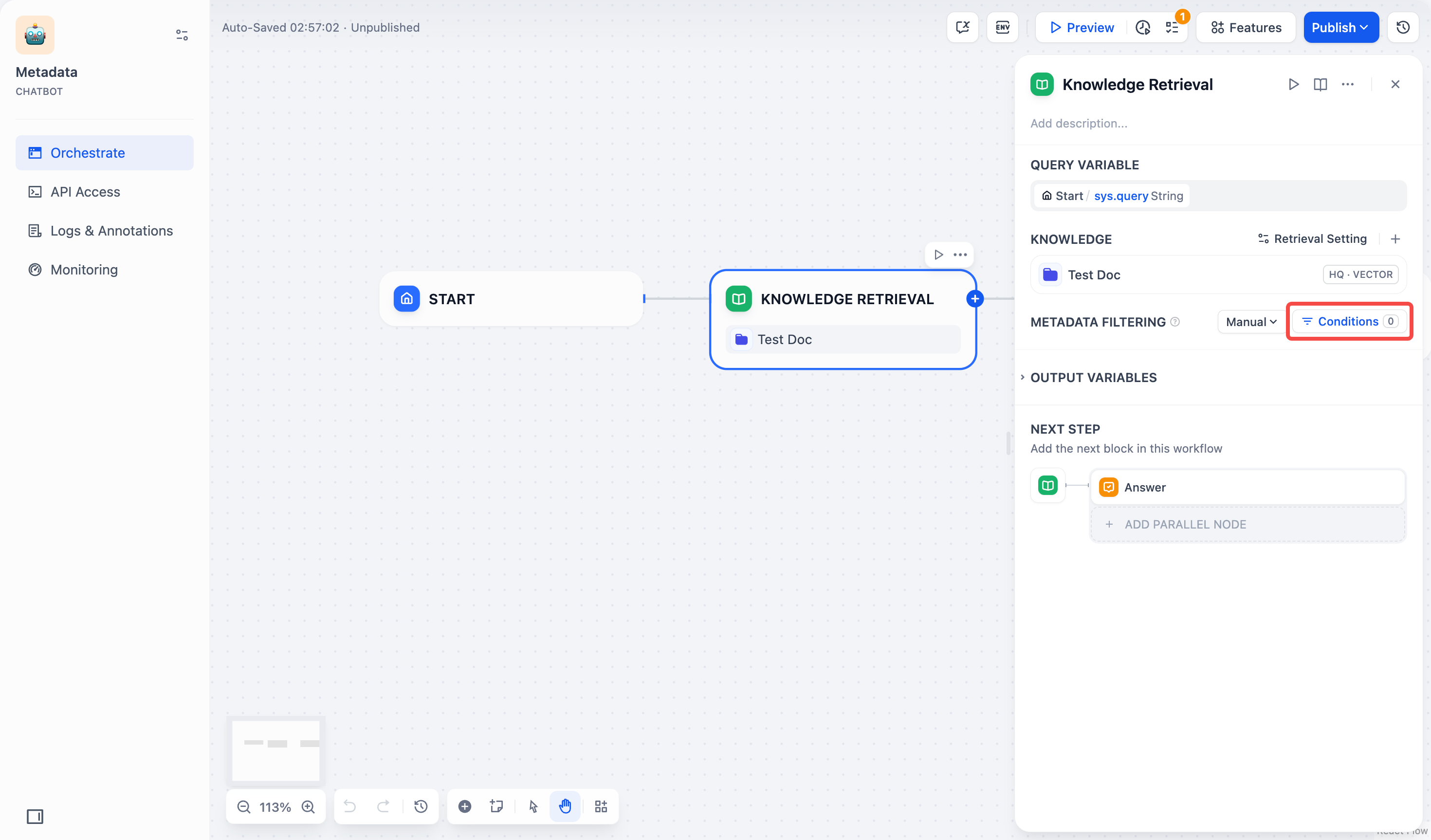
-
設定ボックスの +条件を追加 ボタンをクリックします:
- ドロップダウンリストから選択したナレッジベース内の既存のメタデータフィールドを選択し、フィルタリング条件リストに追加できます。
複数のナレッジベースを同時に選択した場合、ドロップダウンリストにはこれらのナレッジベースに共通するメタデータフィールドのみが表示されます。
- メタデータを検索 検索ボックスで必要なフィールドを検索し、フィルタリング条件リストに追加することもできます。
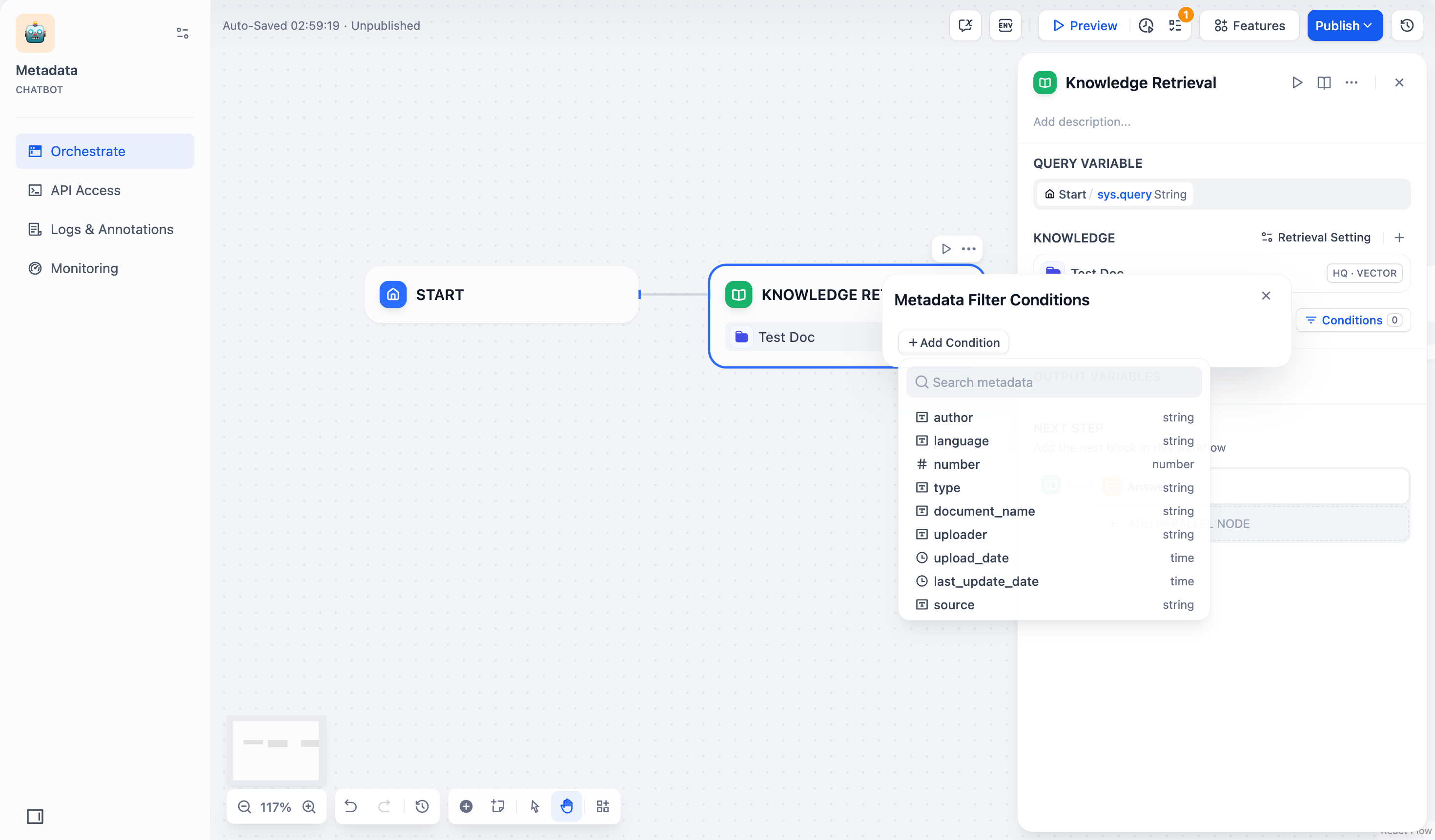
- 複数のフィールドを追加する必要がある場合は、+条件を追加 ボタンを繰り返しクリックします。
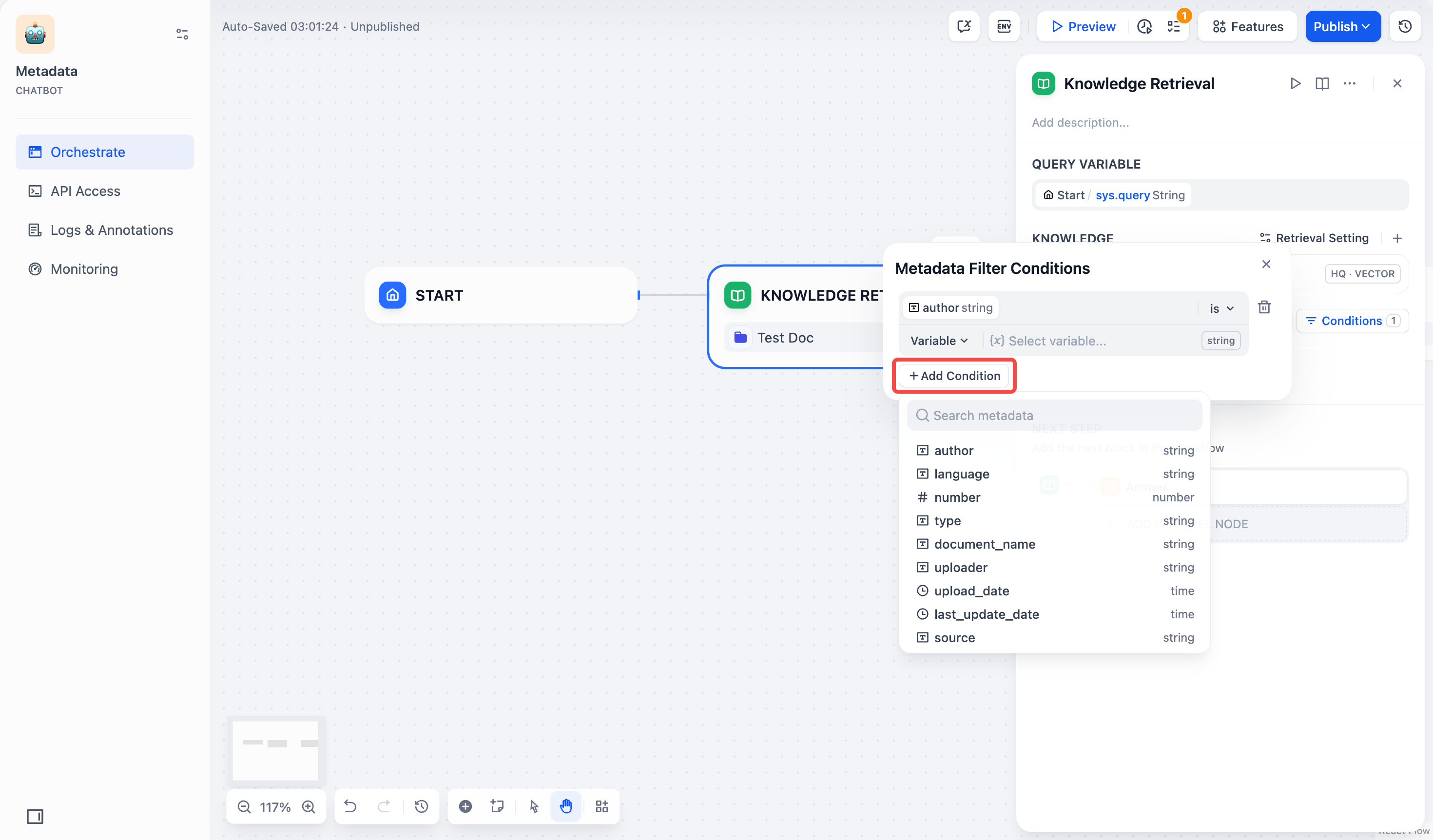
- フィールドタイプごとのフィルタリング条件を設定します:
フィールドタイプ フィルタリング条件 フィルタリング条件の説明と例 文字列 is フィールドの値は入力した値と完全に一致する必要があります。例えば、フィルタリング条件を is "公開済み"に設定した場合、「公開済み」とマークされた文書のみが返されます。is not フィールドの値は入力した値と一致してはいけません。例えば、フィルタリング条件を is not "下書き"に設定した場合、「下書き」とマークされていないすべての文書が返されます。is empty フィールドの値が空です。この条件を設定すると、その文字列がマークされていない文書を検索できます。 is not empty フィールドの値が空ではありません。この条件を設定すると、その文字列がマークされている文書を検索できます。 contains フィールドの値に入力したテキストが含まれています。例えば、フィルタリング条件を contains "レポート"に設定した場合、「月次レポート」や「年次レポート」など、「レポート」を含むすべての文書が返されます。not contains フィールドの値に入力したテキストが含まれていません。例えば、フィルタリング条件を not contains "下書き"に設定した場合、「下書き」を含まないすべての文書が返されます。starts with フィールドの値が入力したテキストで始まります。例えば、フィルタリング条件を starts with "Doc"に設定した場合、「Doc1」や「Document」など、「Doc」で始まるすべての文書が返されます。ends with フィールドの値が入力したテキストで終わります。例えば、フィルタリング条件を ends with "2024"に設定した場合、「レポート 2024」や「概要 2024」など、「2024」で終わるすべての文書が返されます。数値 = フィールドの値は入力した数値と等しい必要があります。例えば、 = 10は数値が 10 とマークされているすべての文書に一致します。≠ フィールドの値は入力した数値と等しくてはいけません。例えば、 ≠ 5は数値が 5 とマークされていないすべての文書を返します。> フィールドの値は入力した数値より大きい必要があります。例えば、 > 100は数値が 100 より大きいとマークされているすべての文書を返します。< フィールドの値は入力した数値より小さい必要があります。例えば、 < 50は数値が 50 より小さいとマークされているすべての文書を返します。≥ フィールドの値は入力した数値以上である必要があります。例えば、 ≥ 20は数値が 20 以上とマークされているすべての文書を返します。≤ フィールドの値は入力した数値以下である必要があります。例えば、 ≤ 200は数値が 200 以下とマークされているすべての文書を返します。is empty フィールドに値が設定されていません。例えば、 is emptyはそのフィールドに数値がマークされていないすべての文書を返します。is not empty フィールドに値が設定されています。例えば、 is not emptyはそのフィールドに数値がマークされているすべての文書を返します。時間 is フィールドの時間値は選択した時間と完全に一致する必要があります。例えば、 is "2024-01-01"は 2024 年 1 月 1 日とマークされている文書のみを返します。before フィールドの時間値は選択した時間より前でなければなりません。例えば、 before "2024-01-01"は 2024 年 1 月 1 日より前とマークされているすべての文書を返します。after フィールドの時間値は選択した時間より後でなければなりません。例えば、 after "2024-01-01"は 2024 年 1 月 1 日より後とマークされているすべての文書を返します。is empty フィールドの時間値が空です。この条件を設定すると、時間がマークされていない文書を検索できます。 is not empty フィールドの時間値が空ではありません。この条件を設定すると、時間がマークされている文書を検索できます。 -
メタデータフィルタリング値を選択して追加します:
- 変数:変数(Variable)を選択し、その Chatflow/Workflow 内で文書のフィルタリングに使用する変数を選択します。
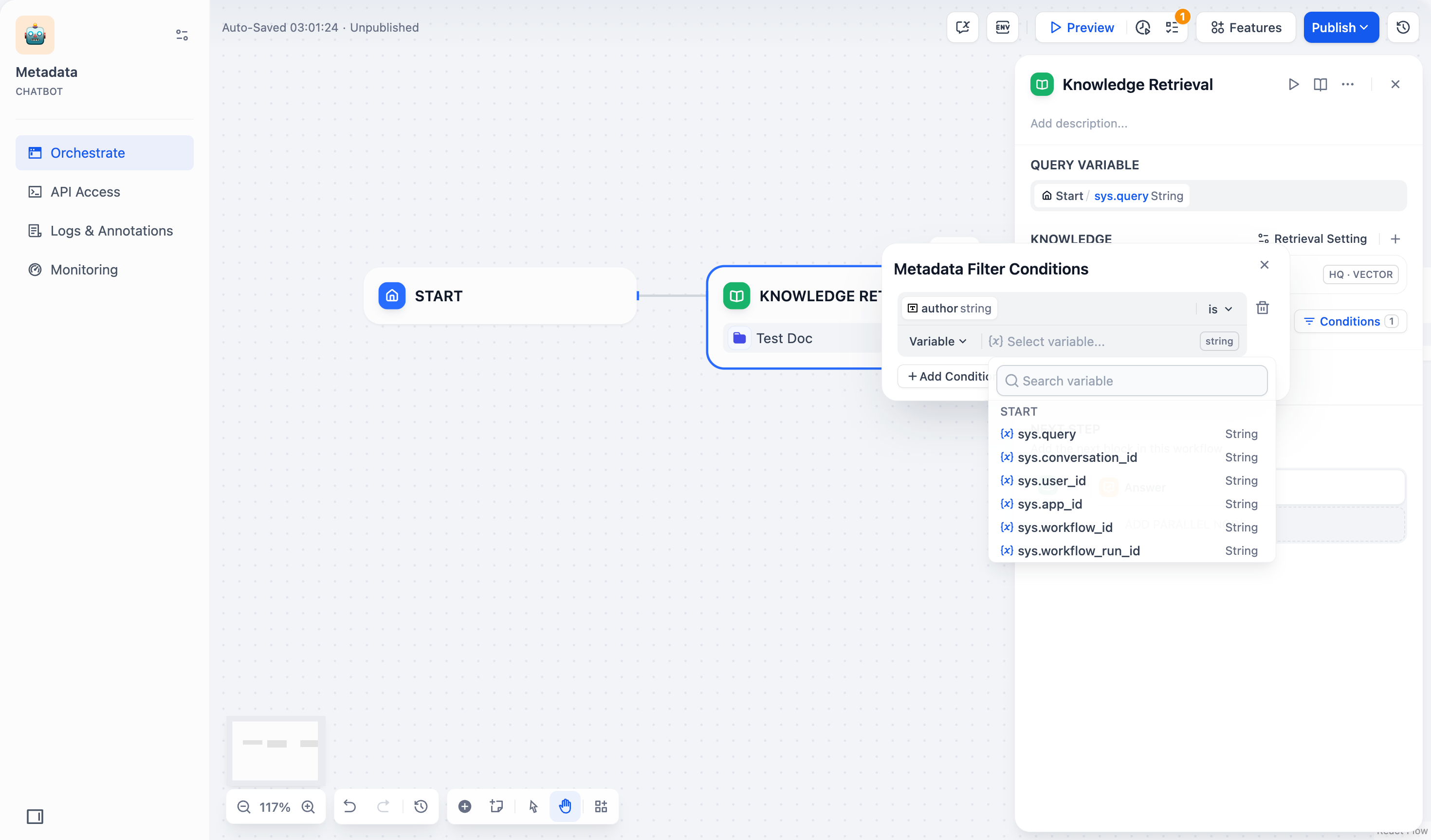
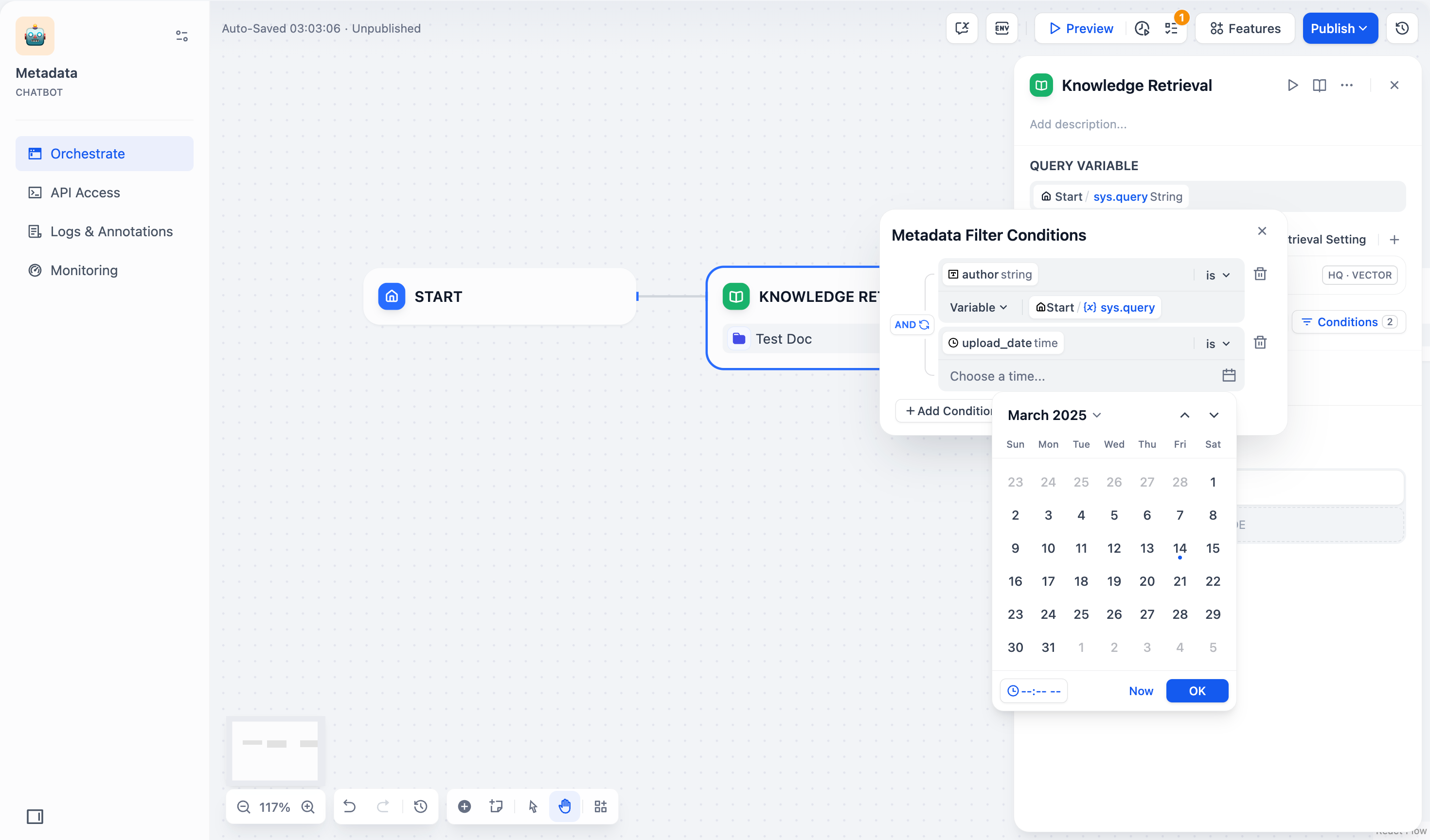
- 定数:**定数(Constant)**を選択し、必要な定数値を手動で入力します。
時間タイプのフィールドは定数によるフィルタリングのみに対応しています。日付選択ツールは、この時間タイプのフィールド用です。
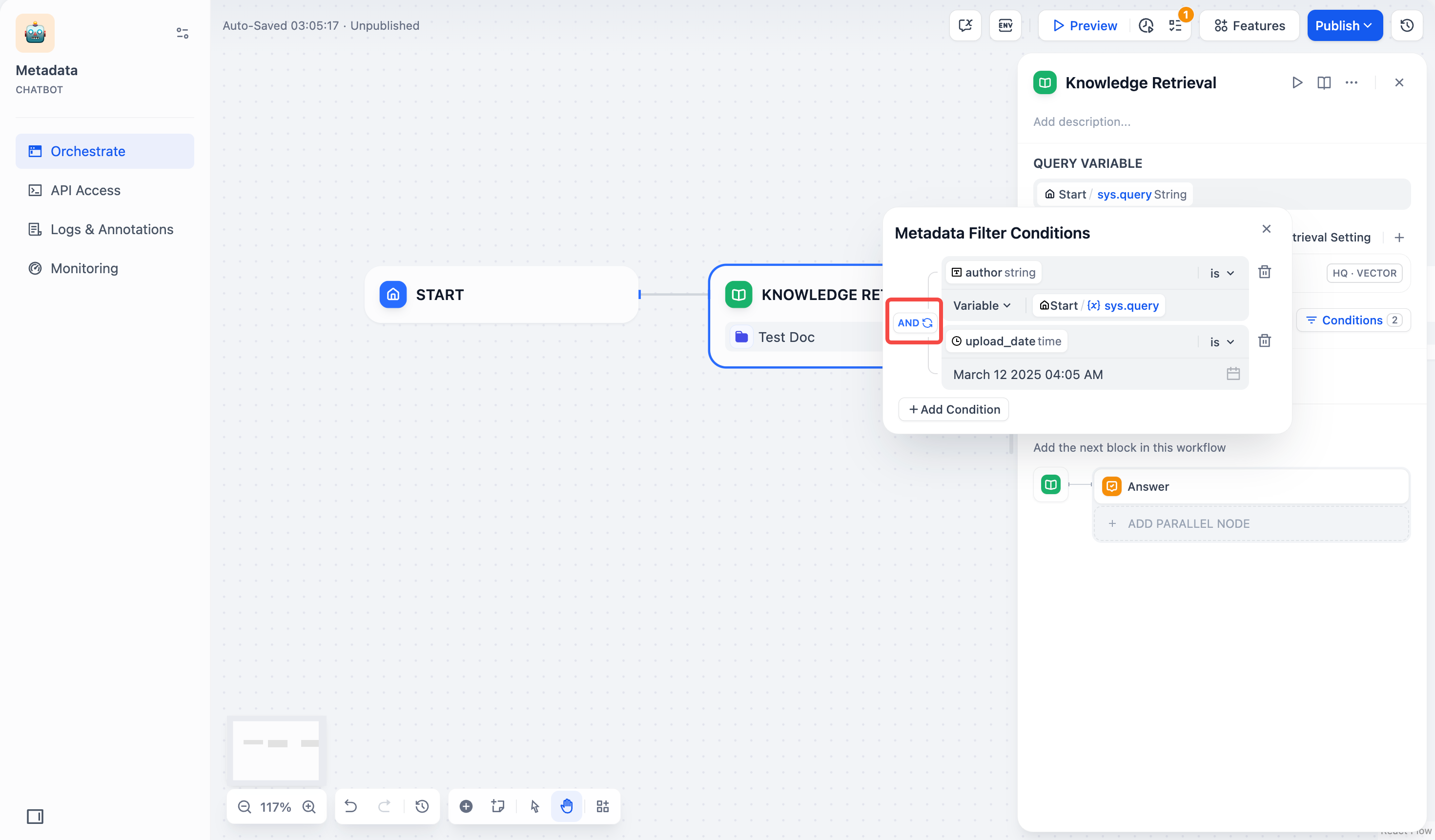
フィルタリング値は大文字と小文字を区別し、完全一致が必要です。例えば、フィルタリング条件をstarts with "App"またはcontains "App"に設定した場合、「Apple」には一致しますが、「apple」や「APPLE」には一致しません。- 論理演算子
ANDまたはORを設定します。AND:すべての条件に一致する文書のみを検索します。OR:いずれかの条件に一致する文書を検索します。
- パネルの外側をクリックすると、設定が保存されます。
ナレッジベースでリンクされたアプリを表示する
ナレッジベースの左側で、関連付けられているすべてのアプリを確認できます。円形のアイコンにカーソルを合わせると、関連付けられたアプリの一覧が表示されます。右側のジャンプボタンをクリックすると、すばやく各アプリを開けます。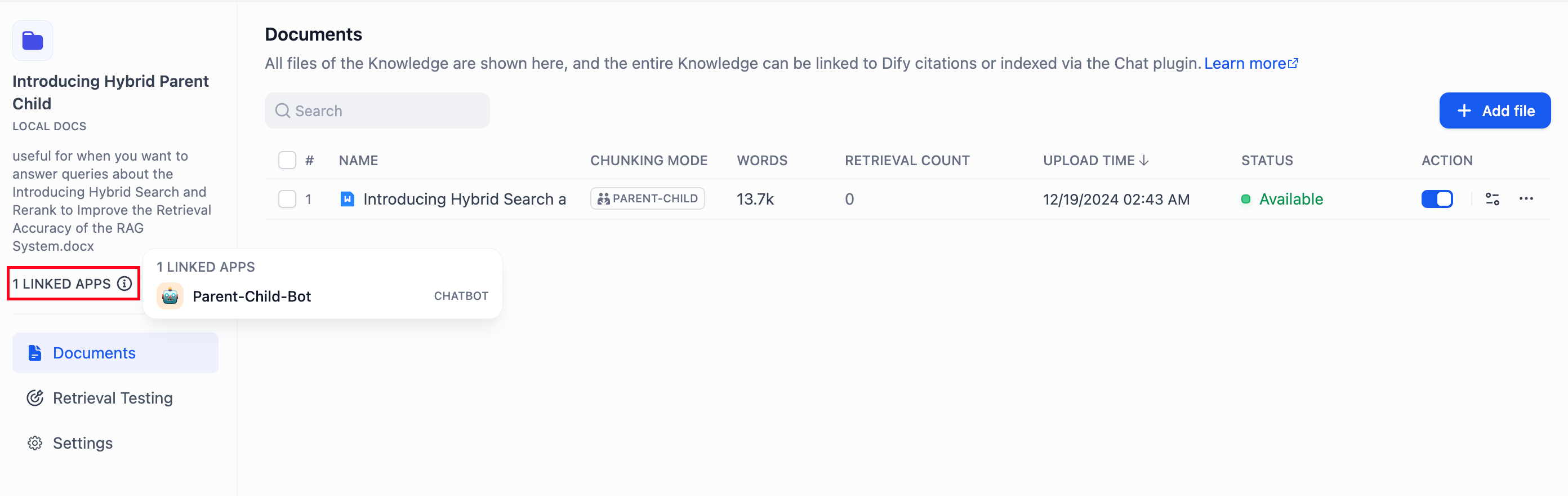
よくある質問
- 複数のリコールモードでの Rerank 設定の選択方法は?
- 「重み設定」が見つからない、または Rerank モデルの設定を求められる場合、どうすればよいですか?
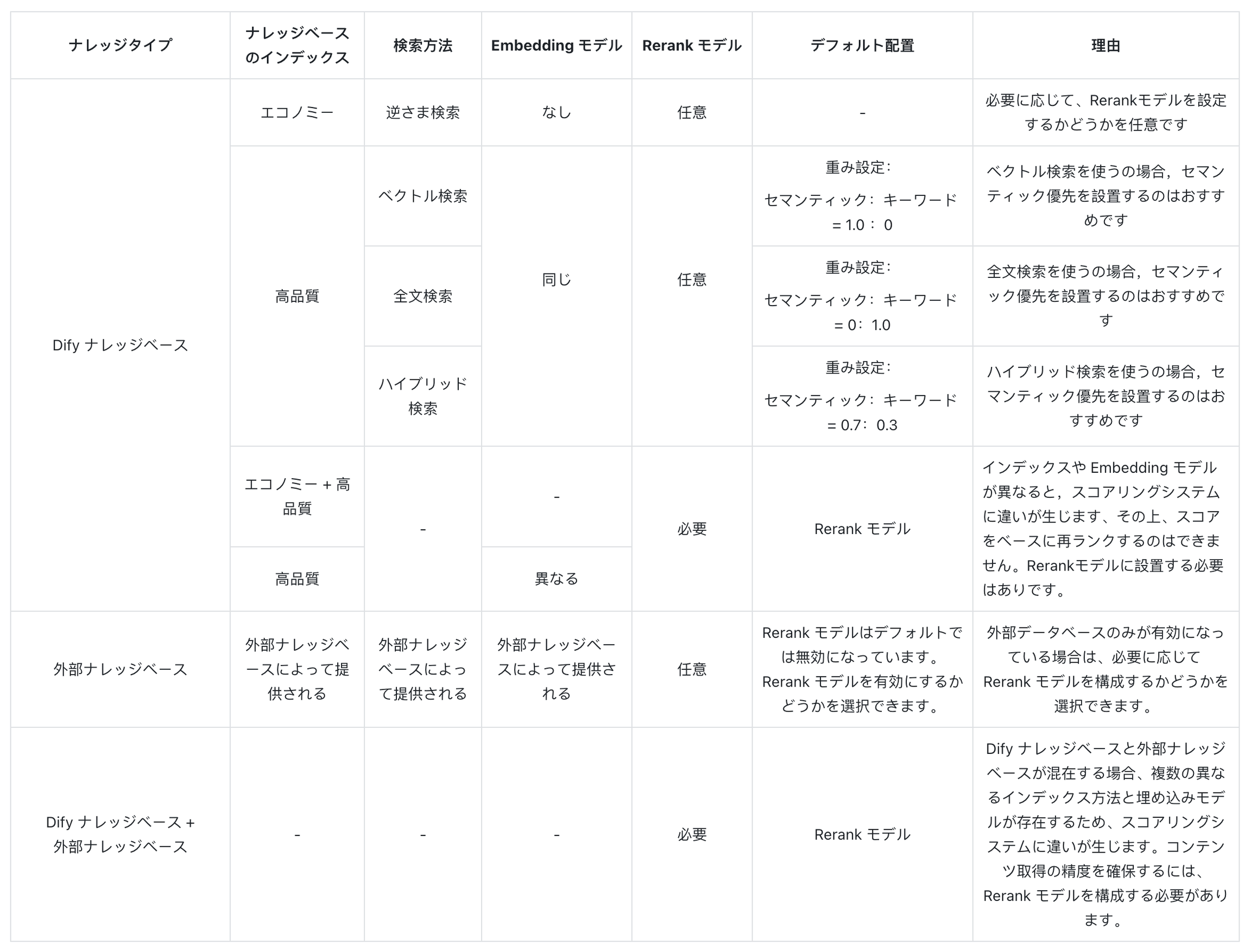
- 複数のナレッジベースを参照する際、「重み設定」を調整できず、エラーメッセージが表示される場合はどうすればよいですか?
- 複数リコールモードで「重み設定」オプションが見つからず、Rerank モデルしか表示されないのはなぜですか?