

The Document Extractor node converts uploaded files into text that LLMs can process. Since language models can’t directly read document formats like PDF or DOCX, this node serves as the essential bridge between file uploads and AI analysis.Documentation Index
Fetch the complete documentation index at: https://docs.dify.ai/llms.txt
Use this file to discover all available pages before exploring further.
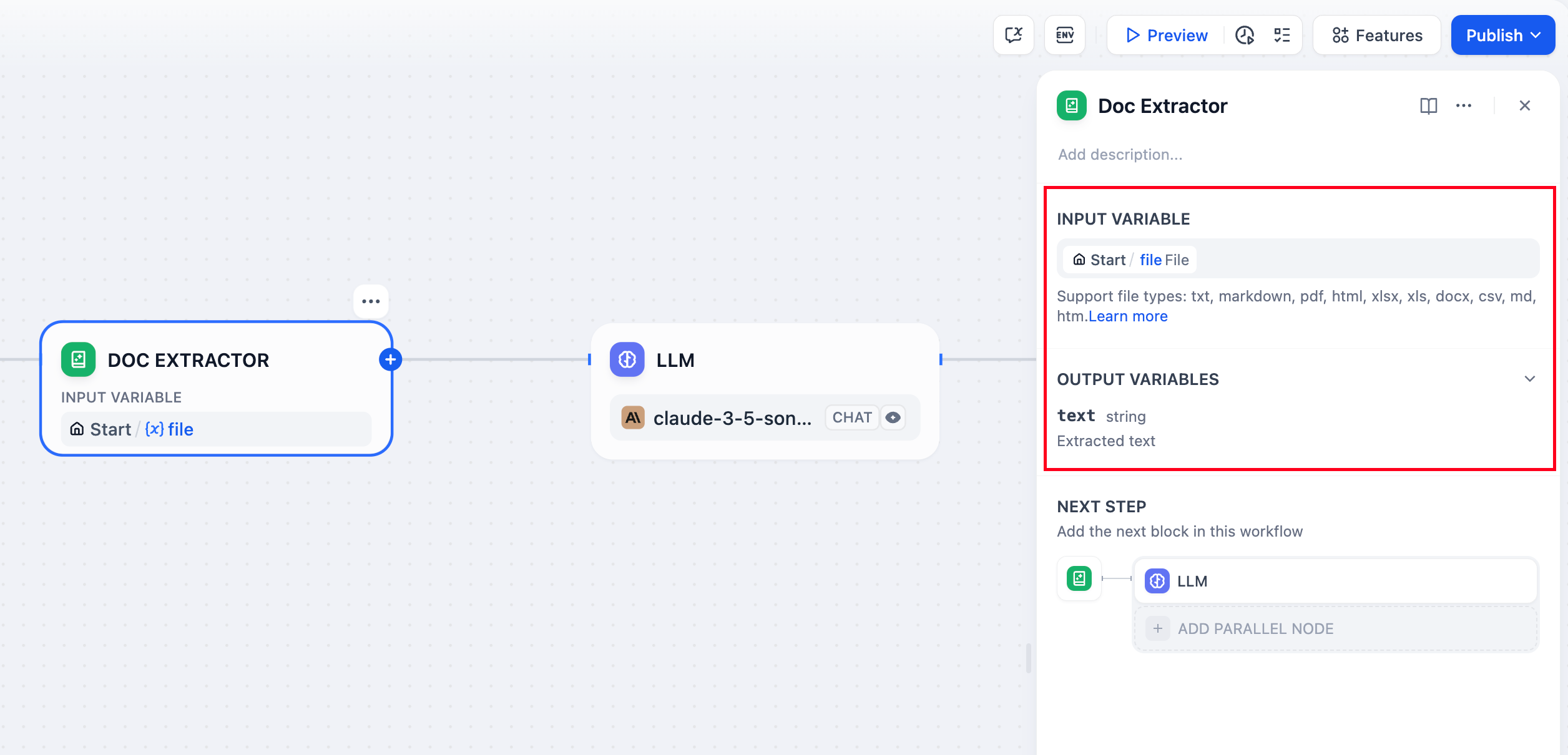
Supported File Types
The node handles most text-based document formats: Text Documents - TXT, Markdown, HTML files with direct text content Office Documents - DOCX files from Microsoft Word and compatible applications PDF Documents - Text-based PDFs using pypdfium2 for accurate text extraction Office Files - DOC files require Unstructured API, DOCX files support direct parsing with table extraction converted to Markdown format Spreadsheets - Excel (.xls/.xlsx) and CSV files converted to Markdown tables Presentations - PowerPoint (.ppt/.pptx) files processed via Unstructured API Email Formats - EML and MSG files for email content extraction Specialized Formats - EPUB books, VTT subtitles, JSON/YAML data, and Properties files Files containing primarily binary content like images, audio, or video require specialized processing tools or external services.Input and Output
Input Configuration
Configure the node to accept either: Single File input from a file variable (typically from the Start node) Multiple Files as an array for batch document processingOutput Structure
The node outputs extracted text content:- Single file input produces a
stringcontaining the extracted text - Multiple file input produces an
array[string]with each file’s content
text and contains the raw text content ready for downstream processing.
Implementation Example
Here’s a complete document Q&A workflow using the Document Extractor: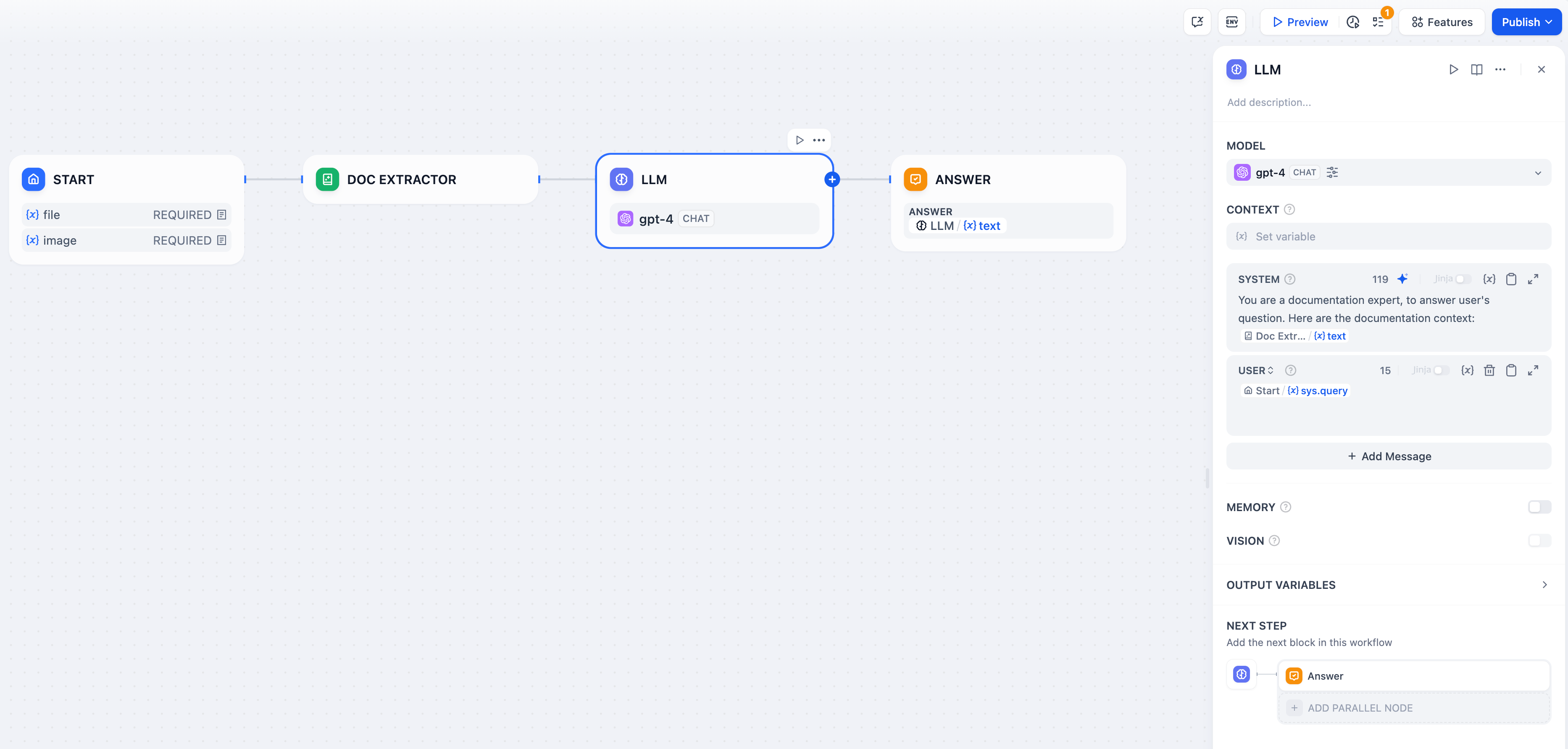
Workflow Setup
File Upload Configuration - Enable file input in your Start node to accept document uploads from users. Text Extraction - Connect the Document Extractor to process uploaded files and extract their text content. AI Processing - Use the extracted text in LLM prompts for analysis, summarization, or question answering.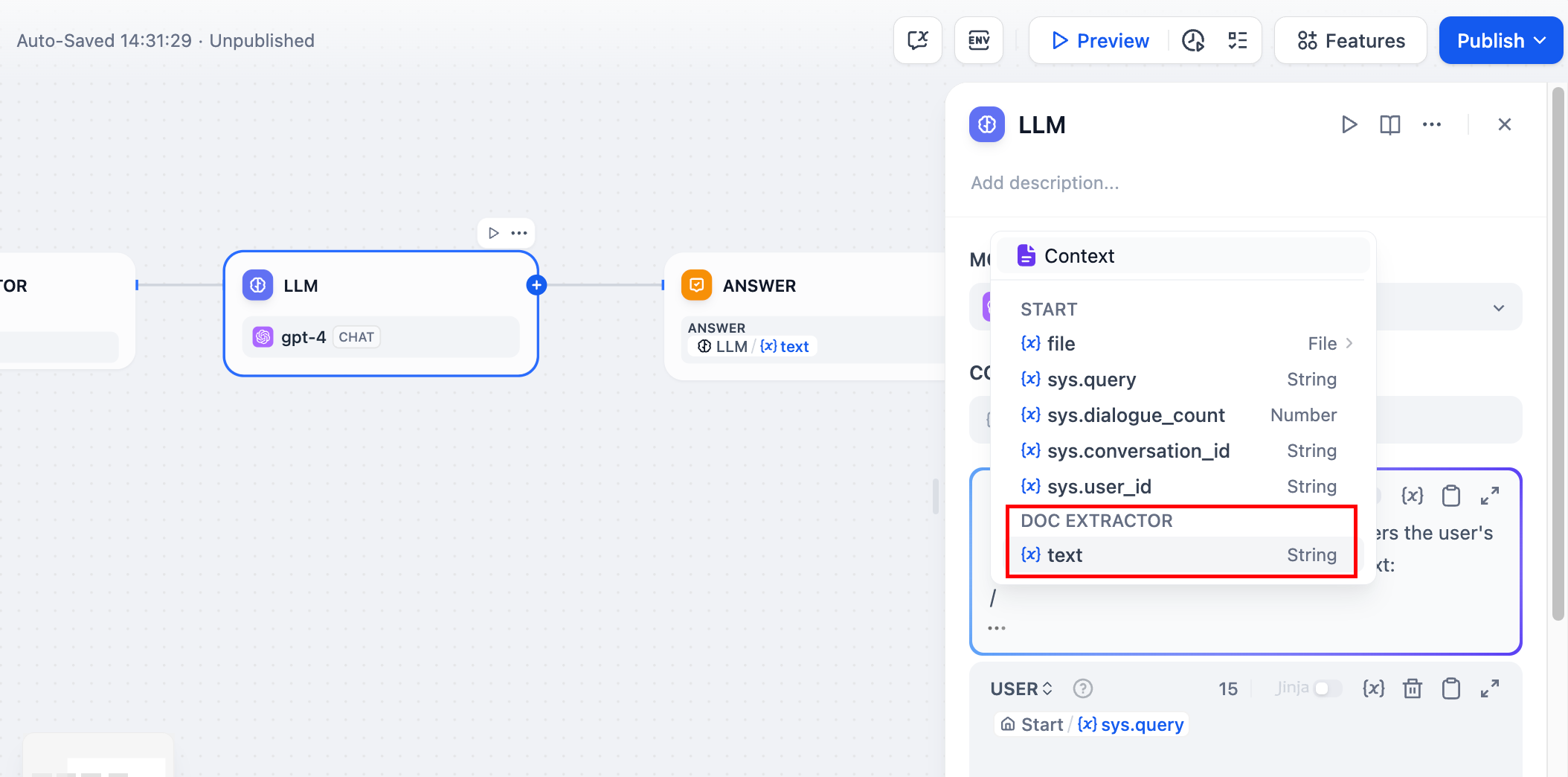
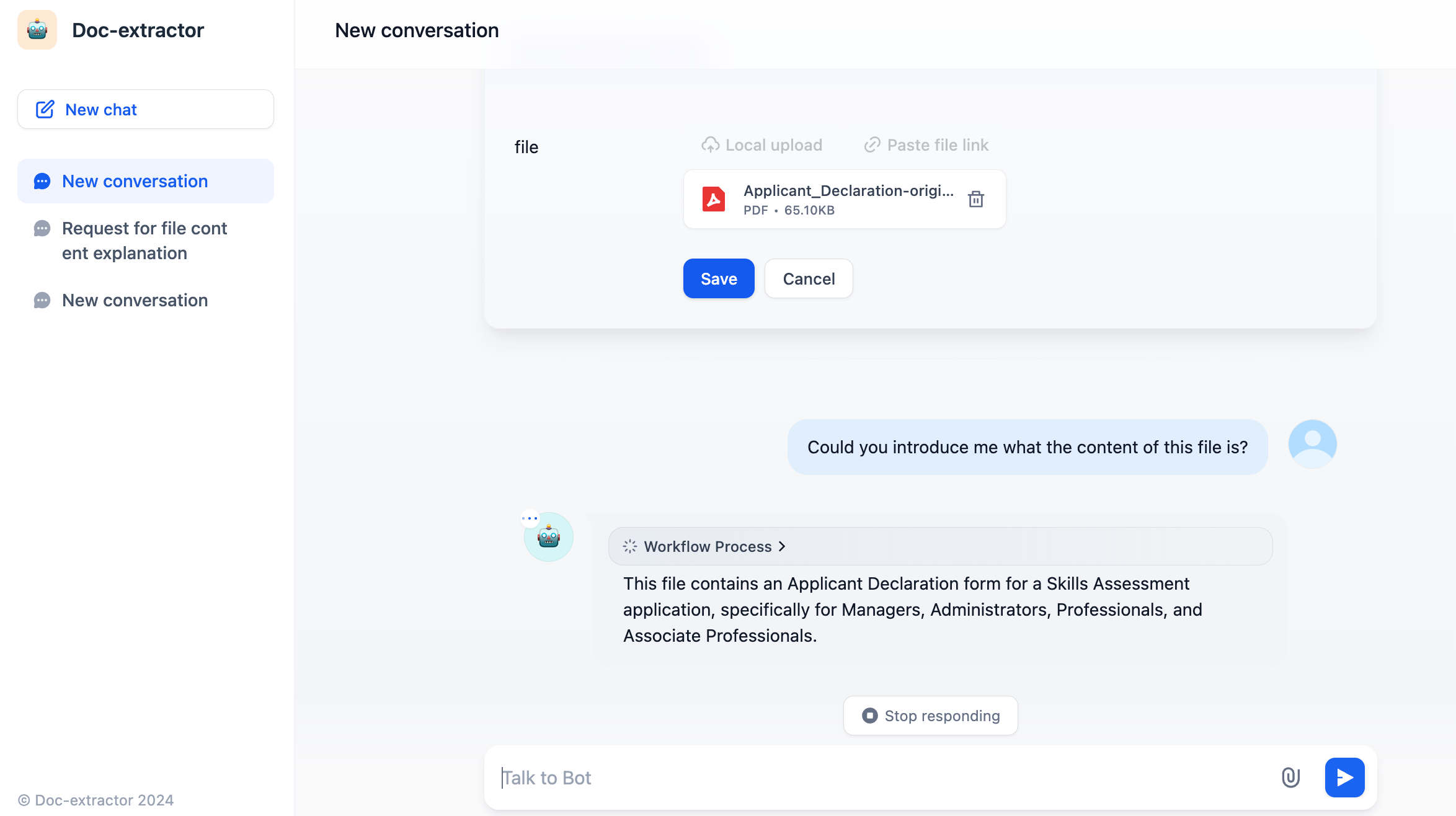
Processing Considerations
The Document Extractor uses specialized parsing libraries optimized for different file formats. It preserves text structure and formatting where possible, making extracted content more useful for LLM processing.File Format Processing
Encoding Detection - Uses chardet library to automatically detect file encoding with UTF-8 fallback for text-based files Table Conversion - Excel and CSV data becomes Markdown tables for better LLM comprehension Document Structure - DOCX files maintain paragraph and table ordering with proper table-to-Markdown conversion Multi-line Content - VTT subtitle files merge consecutive utterances by the same speakerExternal Dependencies
Some file formats require the Unstructured API service configured viaUNSTRUCTURED_API_URL and UNSTRUCTURED_API_KEY:
- DOC files (legacy Word documents)
- PowerPoint presentations (if using API processing)
- EPUB books (if using API processing)