本文档由 AI 自动翻译。如有任何不准确之处,请参考 英文原版。Dify 应用内置了多项可选功能,开启后可提升终端用户的使用体验。打开构建器的 功能 面板,即可查看当前应用类型支持的功能。
聊天助手、Agent 和文本生成应用的功能面板
Chatflow 的功能面板
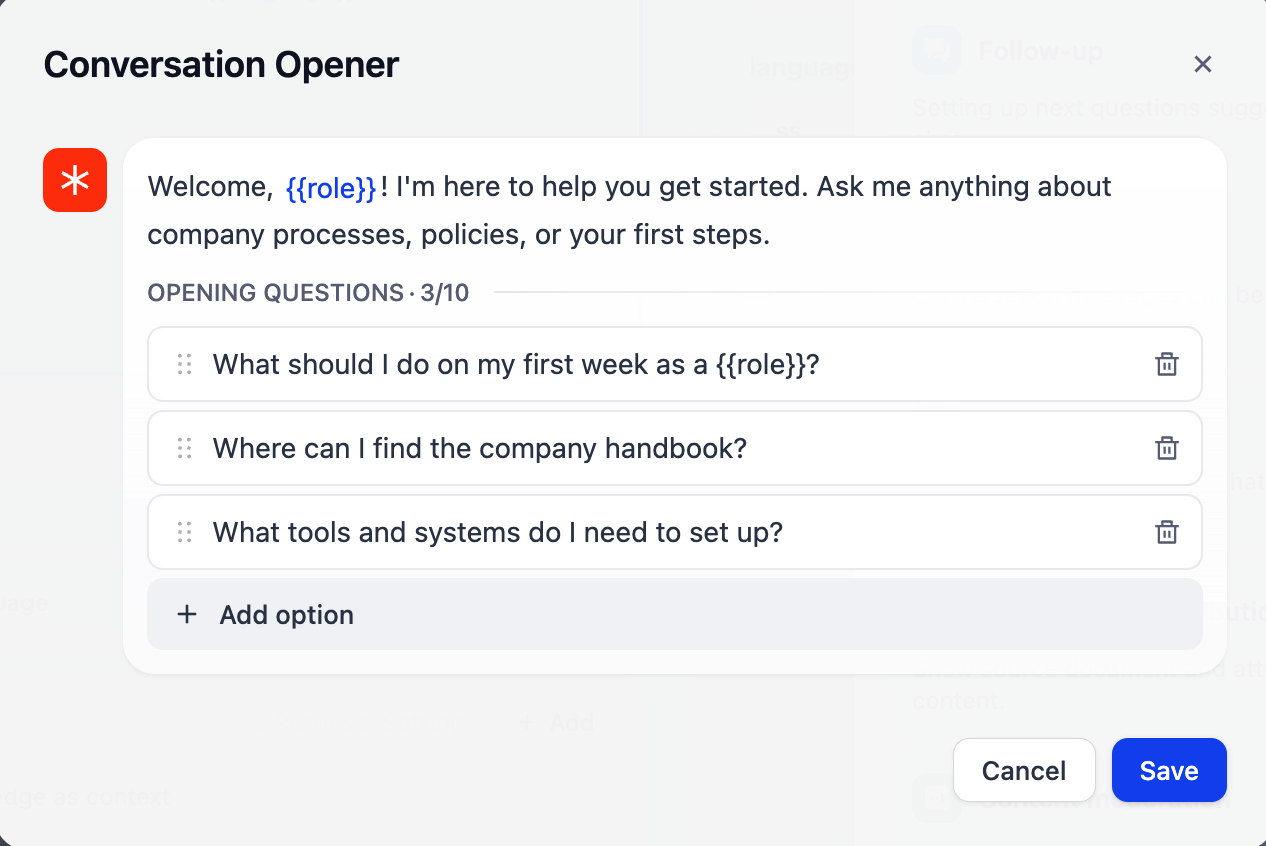
对话开场白
设置一条在每次对话开始时向用户展示的欢迎消息,并可添加建议问题,引导用户了解应用的核心能力。 你可以在开场白和建议问题中插入变量,实现个性化体验。-
在开场白中输入
{或/,即可从变量选择器中插入变量。 -
在建议问题中,需手动输入
{{variable_name}}格式的变量名称。
配置
WebApp
下一步问题建议
开启后,每次回复后系统会推荐下一步问题,帮助用户继续对话。 点击 设置 可选择用于生成问题的模型,或编写自定义提示词(最多 1,000 字符)来调整问题的数量、措辞或长度。文字转语音
将 AI 回复转换为音频。你可以配置语言和语音以适配目标用户,并开启 自动播放 功能,在 AI 回复时自动播放音频流。文字转语音 使用工作空间的文本转语音(Text to Speech, TTS)模型(在 集成 > 模型供应商 > 默认模型 中配置)。只有在配置了默认 TTS 模型后,该功能才会出现在 功能 面板中。
语音转文字
为聊天界面启用语音输入。开启后,终端用户可以点击麦克风按钮,通过语音输入消息,无需手动输入。语音转文字 使用工作空间的语音转文本(Speech to Text, STT)模型(在 集成 > 模型供应商 > 默认模型 中配置)。只有在配置了默认 STT 模型后,该功能才会出现在 功能 面板中。
文件上传
允许终端用户在对话过程中随时发送文件。你可以配置接受的文件类型、上传方式以及每条消息允许的最大文件数量。 单个文件大小限制:- 图片:10 MB
- 文档:15 MB
- 音频:50 MB
- 视频:100 MB
引用与归属
展示 AI 回复背后的来源文档。开启后,从关联知识库中提取内容的回复会显示编号引用,链接至原始文档和分段。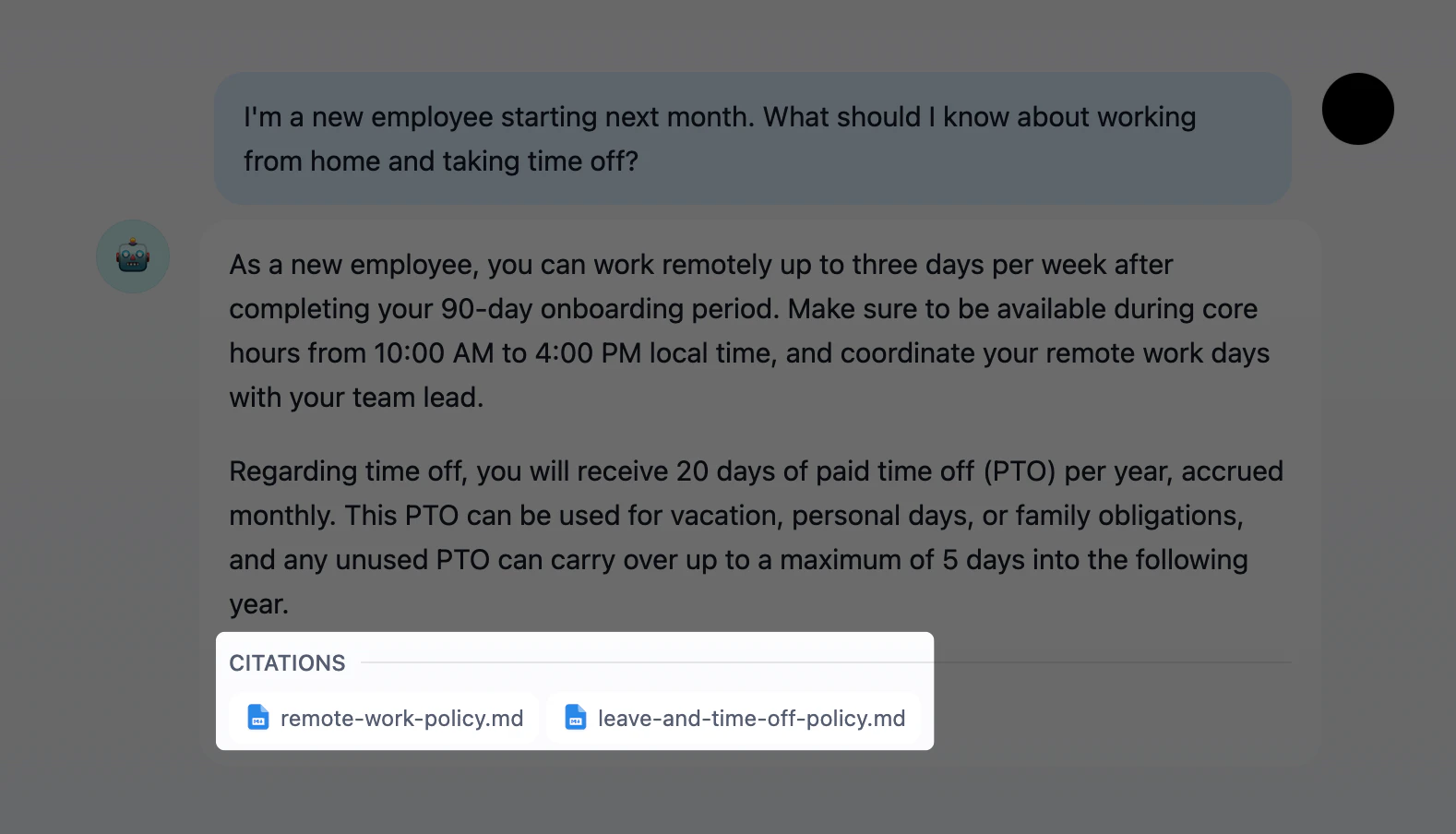
内容审核
过滤用户输入、AI 输出或两者中的不当内容。根据需要选择审核方式:- OpenAI Moderation:使用 OpenAI 专用审核模型,检测多个类别的有害内容。
- 关键词:定义屏蔽词列表,任何匹配项都会触发预设回复。
- 自定义端点:接入自定义审核端点,实现你自己的过滤逻辑。
标注回复
定义优先于 LLM 回复的精选问答对。当用户问题与标注在 语义上 的匹配度超过分数阈值(即问题需要达到的匹配程度)时,系统会直接返回精选答案,而不调用 LLM。 你可以配置分数阈值以及用于语义匹配的嵌入模型。 创建和管理标注的方式:-
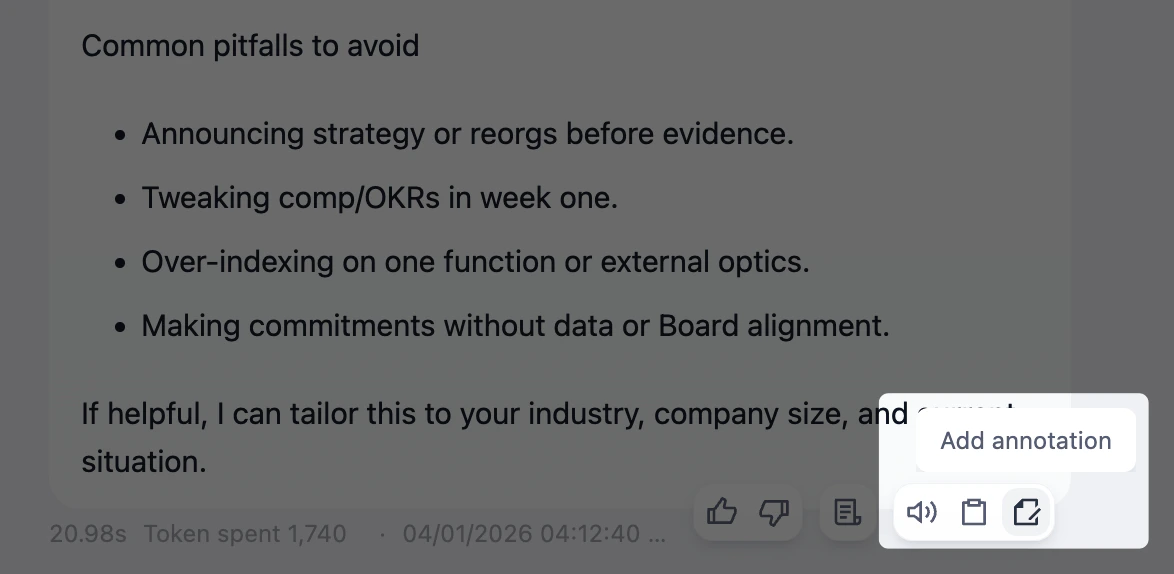
在 调试与预览 或 日志 中,点击任意 LLM 回复上的 添加标注 图标,即可将现有对话直接转为标注。
消息被标注后,图标会变为 编辑,方便你就地修改标注内容。
-
在 标注 中,可手动添加新的问答对、管理现有标注并查看命中记录。点击
...进行批量导入或批量导出。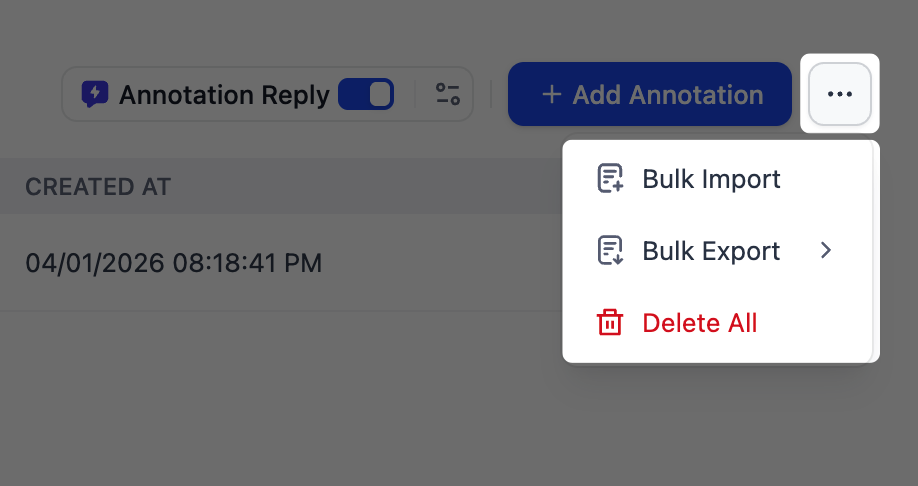
生成更多类似内容
为相同输入生成不同的输出结果。开启后,每条生成结果都会附带一个按钮,用于生成变体,让你无需重新输入即可探索不同的回复。