

Introduction
The Code node allows you to embed custom Python or JavaScript scripts into your workflow to manipulate variables in ways that built-in nodes cannot achieve. It can simplify your workflow and is suitable for scenarios such as arithmetic operations, JSON transformations, text processing, and more. To use variables from other nodes in a Code node, you must select them in theInput Variables field and then reference them in your code.
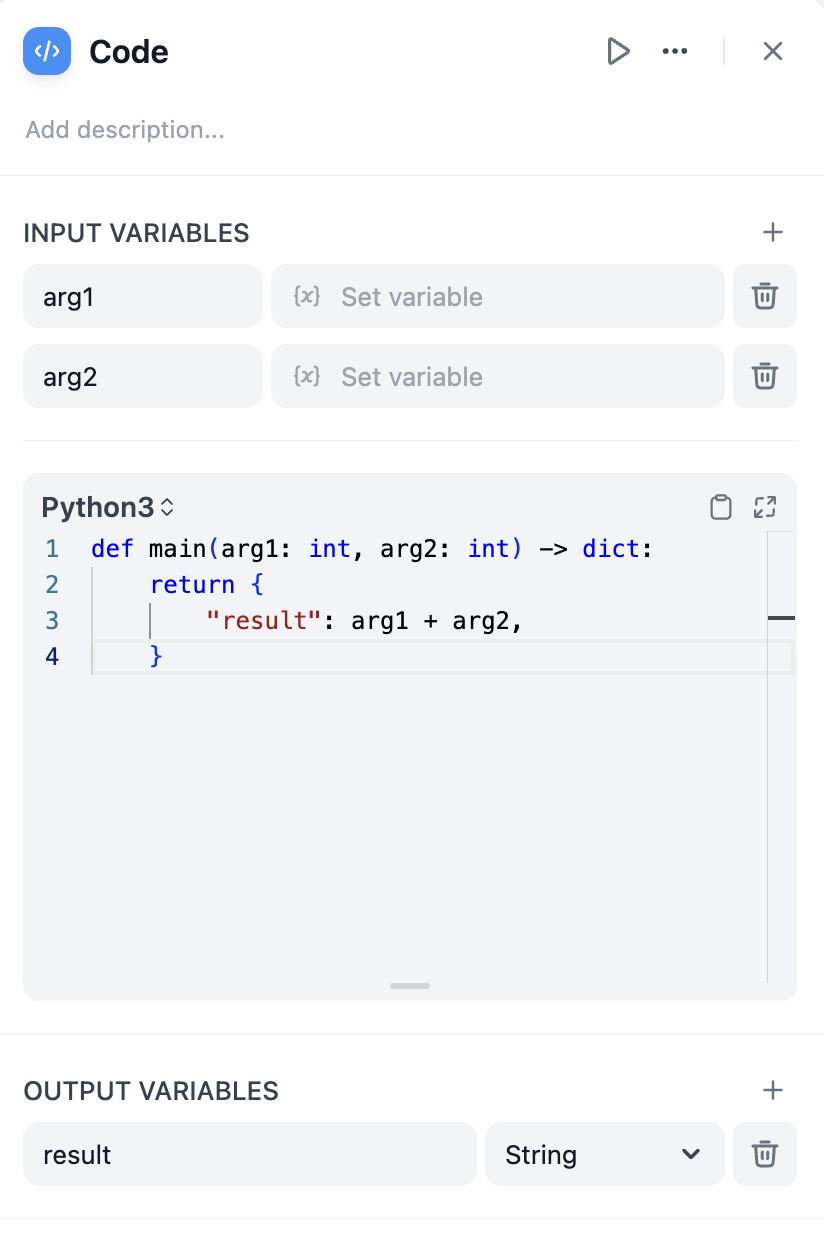
What a Code Node Can Do
With the Code node, you can perform common operations such as structured data processing, mathematical calculations, and data concatenation.Structured Data Processing
In workflows, you often have to deal with unstructured data processing, such as parsing, extracting, and transforming JSON strings. A typical example is data processing from an HTTP node: in common API return structures, data may be nested within multiple layers of JSON objects, and you need to extract certain fields. The Code node can help you perform these operations. Here is a simple example that extracts thedata.name field from a JSON string returned by an HTTP node:
Mathematical Calculations
When you need to perform complex mathematical calculations in a workflow, you can also use the Code node. For example, calculating a complex mathematical formula or performing some statistical analysis on data. Here is a simple example that calculates the variance of an array:Data Concatenation
Sometimes you may need to concatenate multiple data sources, such as multiple knowledge retrievals, data searches, API calls, etc. The Code node can help you integrate these data sources together. Here is a simple example that merges data from two knowledge bases:Local Deployment
If you are a local deployment user, you need to start a sandbox service to prevent the execution of malicious code. This sandbox service requires Docker. You can start it directly usingdocker-compose:
If your system has Docker Compose V2 installed, use
docker compose instead of docker-compose. You can check the version with $ docker compose version.For more information, see the official Docker documentation.Security Policies
Both Python and JavaScript execution environments are strictly isolated (sandboxed) to ensure security. This means that functions that consume large amounts of system resources or may pose security risks are prohibited, such as direct file system access, making network requests, or executing operating system-level commands. These limitations ensure the safe execution of the code while avoiding excessive consumption of system resources.Advanced Features
Retry on Failure
Certain node errors are transient and can often be resolved by rerunning the node. By enabling the error retry feature, the node will automatically attempt to rerun according to a predefined policy upon failure. You can adjust the maximum number of retries and the interval between each retry to set the retry strategy.- The maximum number of retries is 10
- The maximum retry interval is 5000 ms
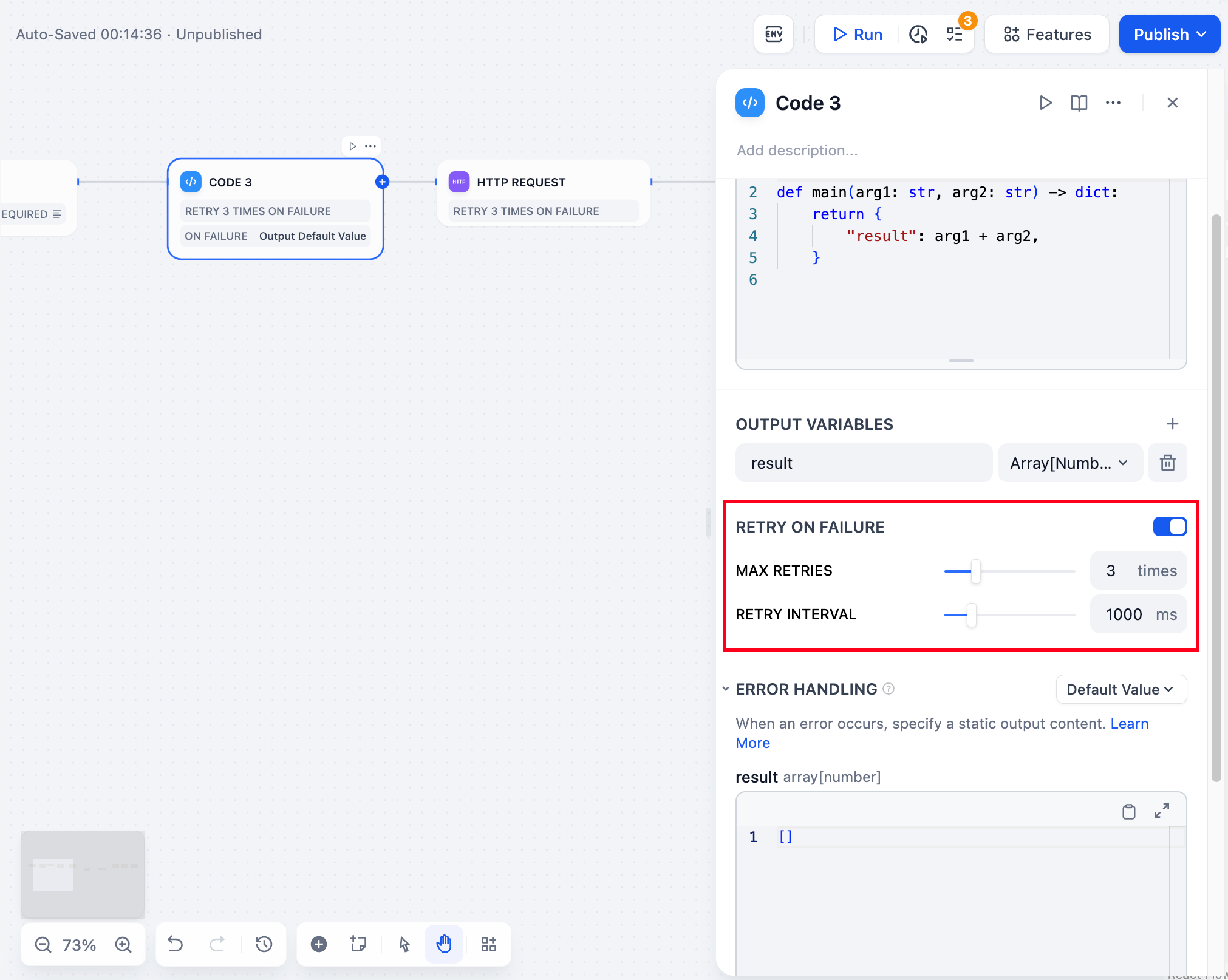
Error Handling
When processing information, Code nodes may encounter code execution errors. You can follow these steps to configure error branches. This allows you to enable a contingency plan when an error occurs in the node, preventing the entire workflow from being interrupted.- Enable Error Handling for the Code node.
- Select and configure an error handling strategy.
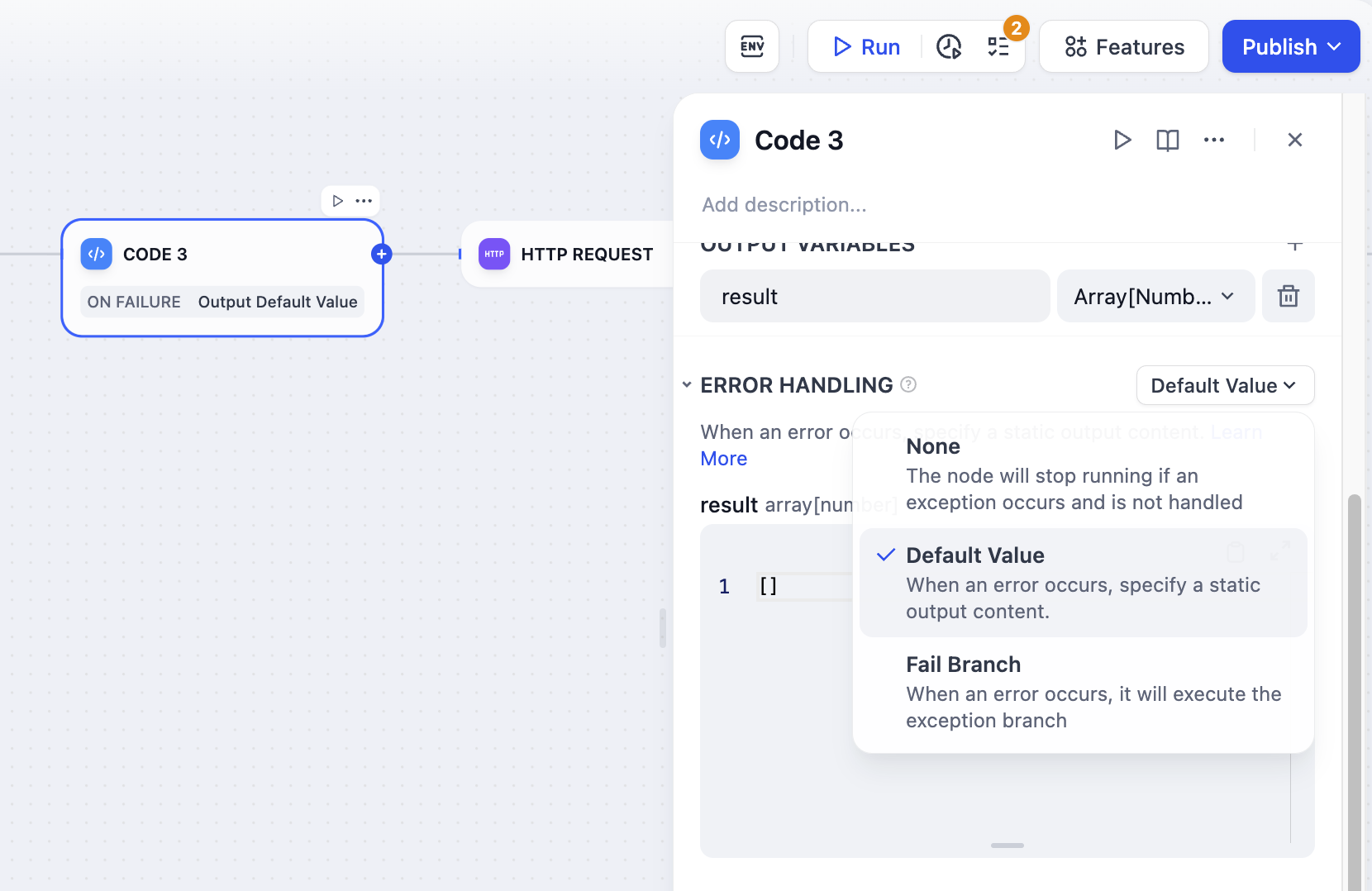
FAQ
Why can’t I save the code it in the Code node? Check if the code contains potentially dangerous behaviors. For example:- Unauthorized file access: The code attempts to read the
/etc/passwdfile, which is a critical system file in Unix/Linux systems that stores user account information. - Sensitive information disclosure: The
/etc/passwdfile contains important information about system users, such as usernames, user IDs, group IDs, home directory paths, etc. Direct access could lead to information leakage.
Code Fix
The Code Fix feature enables automatic code fix by leveraging the previous run’scurrent_code and error_message variables.
When a Code node fails:
- The system captures the code and error message.
- These are passed into the prompt as context variables.
- A new version of the code is generated for review and retry.
Fix Prompt
You can customize a prompt like:In the prompt editor, use the variable insertion menu (
/ or {) to insert variables.
Context Variables
To enable automatic code fix, reference the following context variables in your prompt:current_code: The code from the last run of this node.error_message: The error message from the last run if it failed; otherwise, empty.
- The
last_runvariable can be used to reference the input/output of the previous run. - In addition to the variable above, you can reference the output variables of any preceding nodes as needed.
Version Management
Version management reduces manual copy-paste and allows iterative debugging directly within the workflow.- Each correction attempt is saved as a separate version (e.g., Version 1, Version 2).
- You can switch between versions via the dropdown in the result display area.