


方式一:从零开始构建
方式二:通过模版创建
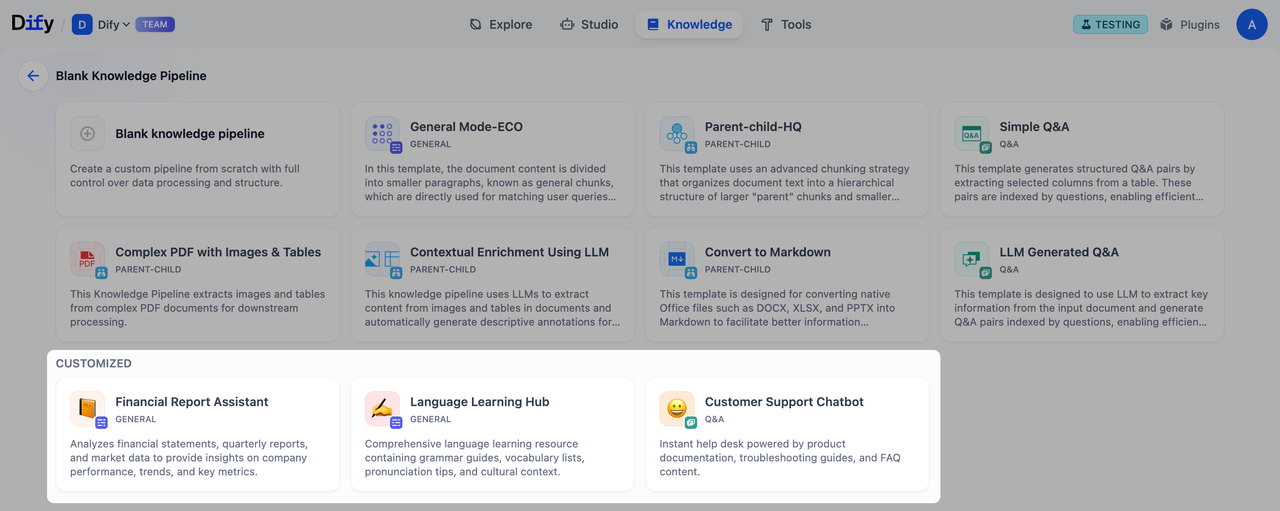
Dify 提供了两种模版方案: 内置流水线(Built-in) 和自定义 (Customized)。两种模版的卡片信息都包含了知识库名称、简介描述和标签(包含分段模式)。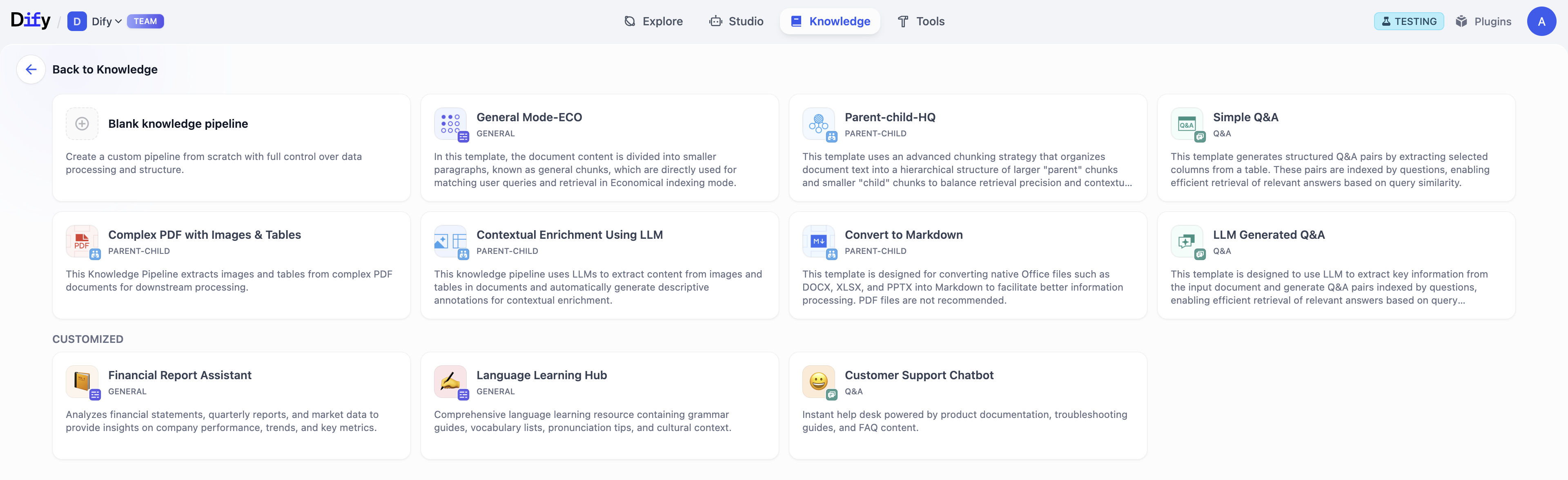
内置流水线(Built-in Pipeline)
内置流水线为预置的知识流水线模版,针对常见的文档数据结构进行优化,你可以根据不同的文档类型和使用场景选择适合的处理方式。点击选择即可开始使用。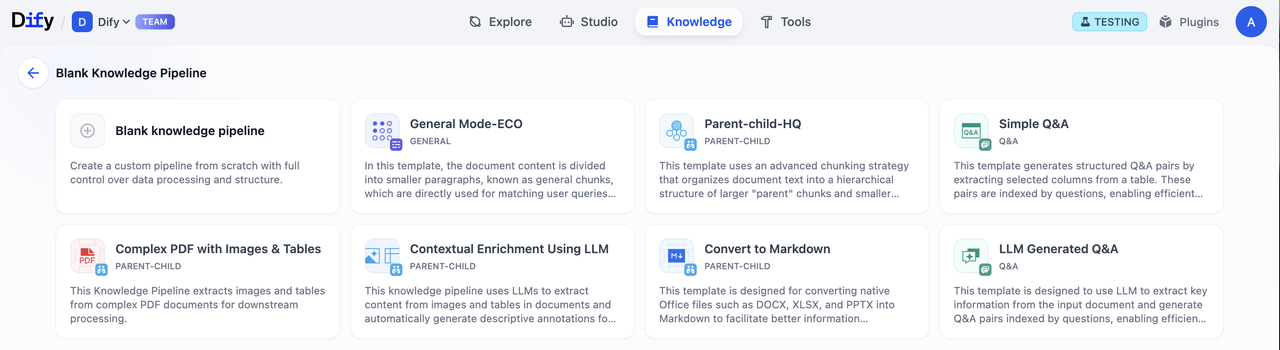
| 模版名称 | 分段结构 | 索引方式 | 检索设置 | 说明 |
|---|---|---|---|---|
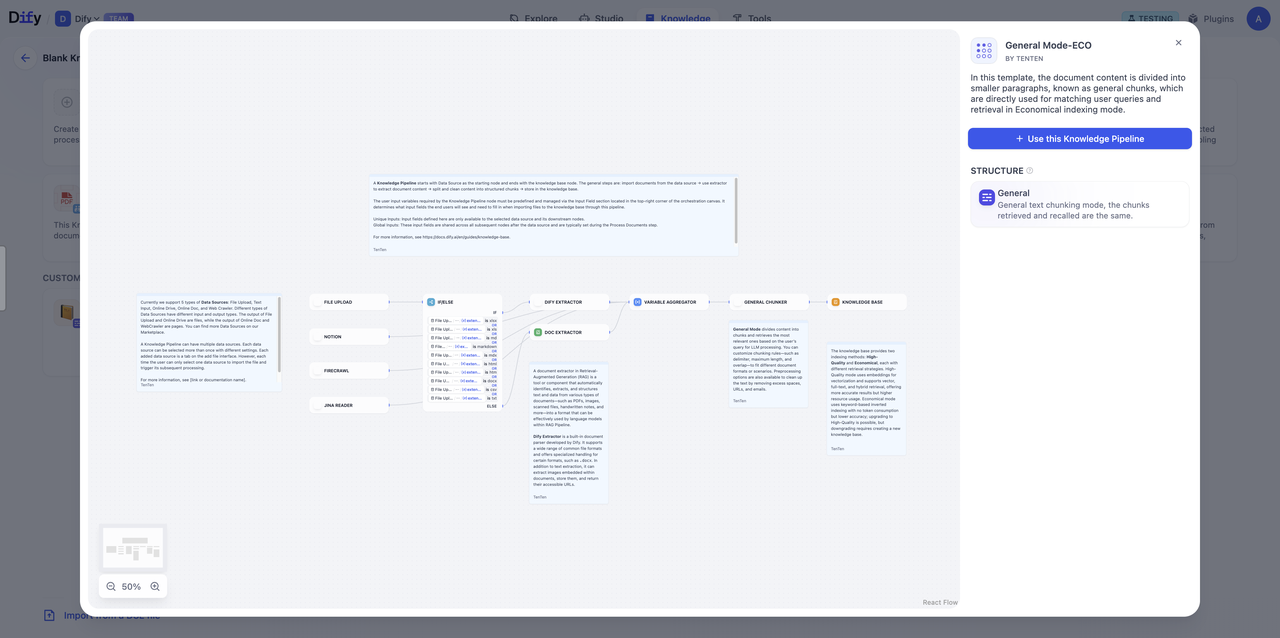
| 通用模式(General Mode) | 通用模式 | 经济 | 倒排索引 | 将文档内容分割成较小的段落块(通用块),直接用于匹配用户查询和检索。 |
| 父子模式(Parent-child Structure) | 父子模式 | 高质量 | 混合检索 | 采用了高级分块策略,将文档文本分成较大的”父块”和较小的”子块”。其中,“父块”包含了”子块”。这样既保证了检索的精确性,又维持了上下文的完整性。 |
| 简单问答(Simple Q&A) | 问答模式 | 高质量 | 向量搜索 | 将表格数据转化为一问一答的形式,通过问题匹配来快速找到对应的答案信息。适用于结构化表格数据。 |
| LLM 生成问答(LLM Generated Q&A) | 问答模式 | 高质量 | 向量搜索 - 加权评分 | 使用大型语言模型自动生成结构化的问答对,通过问题匹配机制找到相关的答案信息。 |
| Markdown 转换(Convert to Markdown) | 父子模式 | 高质量 | 混合检索 - 加权评分 | 专为 DOCX、XLSX 和 PPTX 等 Office 原生文件格式设计,将其转换为 Markdown 格式以便更好地进行信息处理。⚠️ 注意:不推荐使用 PDF 文件。 |
自定义(Customized)
方式三:导入知识流水线
| 名称 | 包含 |
|---|---|
| 数据源 | 文件上传、网站、在线文档和在线网盘 |
| 数据处理流程 | 文档提取、内容分块和清洗策略 |
| 知识库储存配置 | 索引方式、检索设置和存储参数 |
| 节点连接 | 节点间的连接和处理顺序 |
| 用户输入表单 | 自定义的参数输入字段(如有配置) |