

Use Models with Your AI Credits
Dify Cloud gives you AI Credits to use models from a set of popular providers, so you don’t need your own API key to start. Install one of these providers from Integrations > Model Provider (or the Marketplace), and its models are ready to use. Each AI response consumes your AI Credits. An AI response is a single model call (one input and one output), and it counts as one response no matter how many tokens it uses. The number of credits a response costs depends on the model, with larger models costing more than smaller ones. See the Dify pricing page for which providers AI Credits support and how many credits each model costs.Use Your Own Account with a Supported Provider
Add your own API key to a supported provider when you want higher rate limits or billing through your own provider account.- In Integrations > Model Provider, install the provider if it isn’t already.
- Click Setup on its card, then enter your API key and any other required details. Dify checks the key before making the provider available.
Connect a Provider AI Credits Don’t Support
To use a provider that AI Credits don’t support, install it first and run it on your own account. AI Credits don’t apply to these providers.- In Integrations > Model Provider, browse Install model providers, or open the Marketplace for the full list.
- Install the provider, click Setup, and enter your API key along with any other required details.
Add a Custom Model
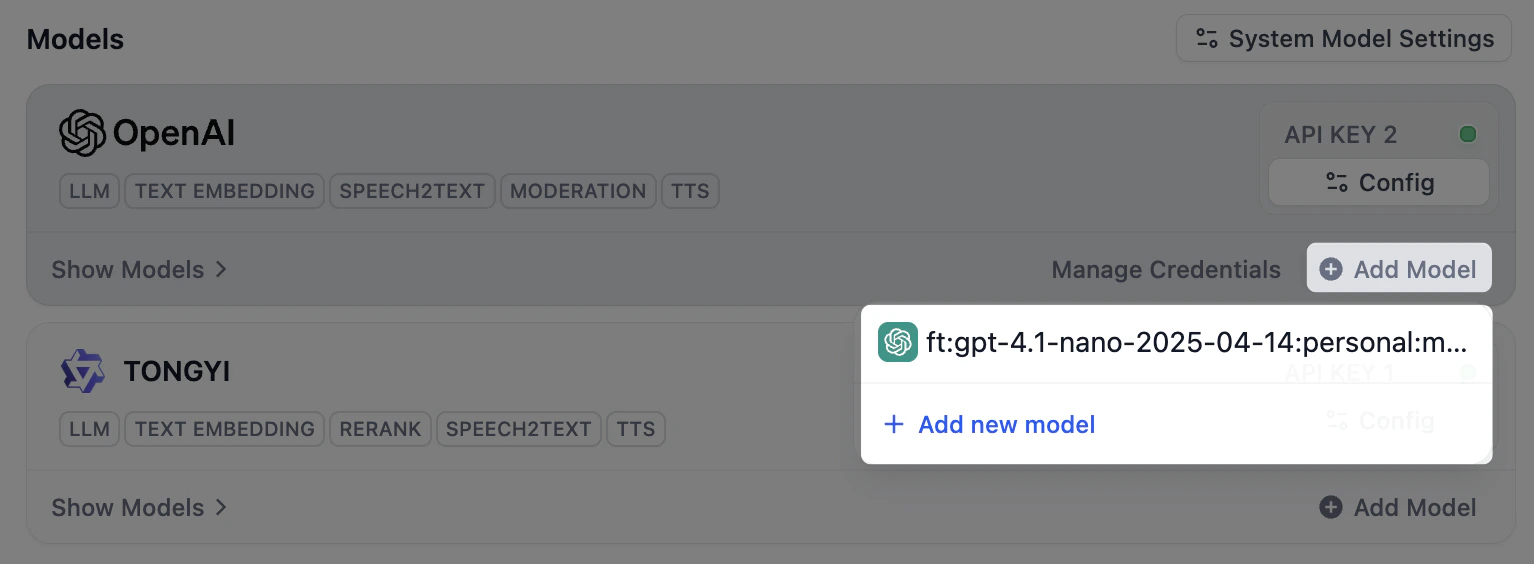
A provider’s models are ready as soon as you connect it, so you only add one by hand when the model you need isn’t listed, such as a brand-new or fine-tuned model. Click Add Model on the provider’s card, then give the model a name and its credentials. Providers that serve only a fixed set of models don’t offer this option.If the model you add matches the name and type of an existing one, Dify attaches the new key to that model instead of creating a duplicate.
Manage Your Keys
Add more than one key to a provider when you want to keep development and production apart or spread usage across several accounts.-
For a provider’s own models, click Configure on its card to manage the keys they share.
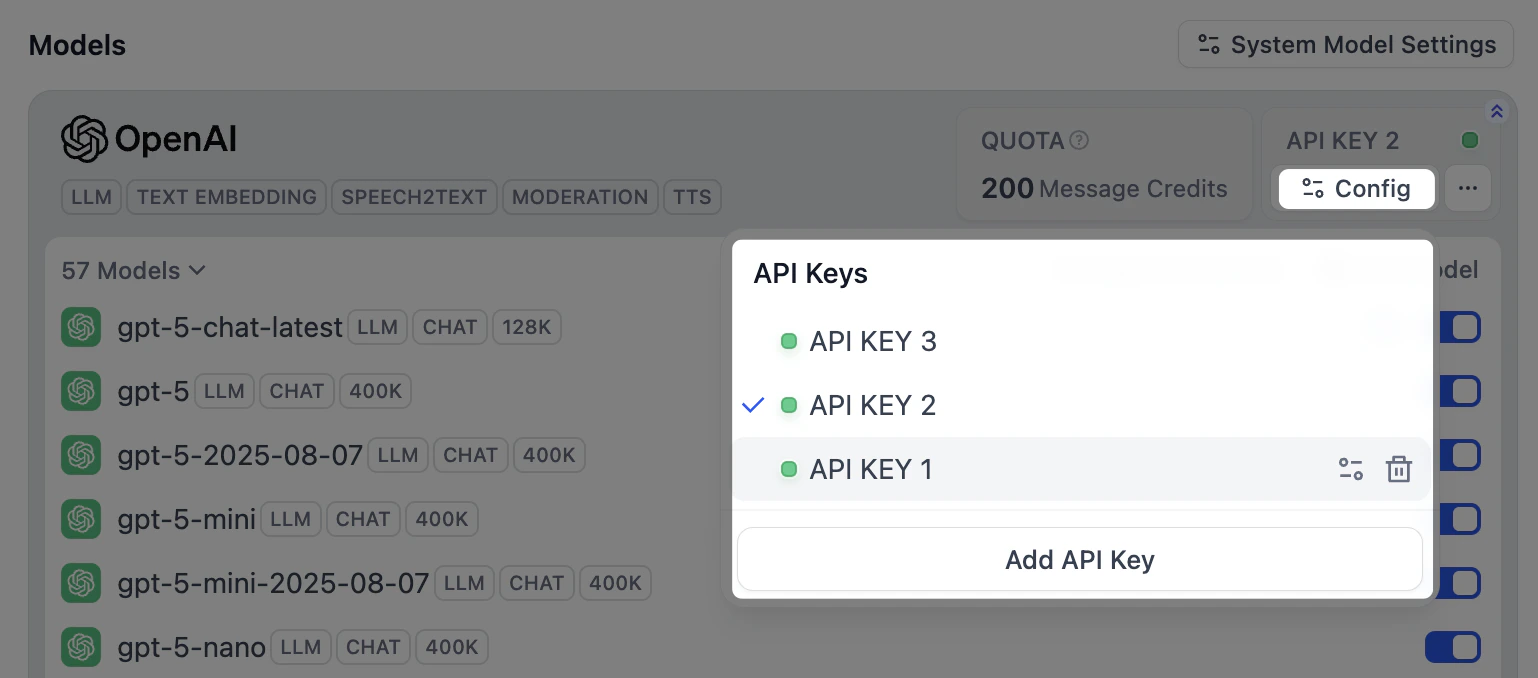
-
For a custom model you added, click Configure on that model to manage its own keys.
To view every custom model’s keys in one place, click Manage Credentials on the provider card.

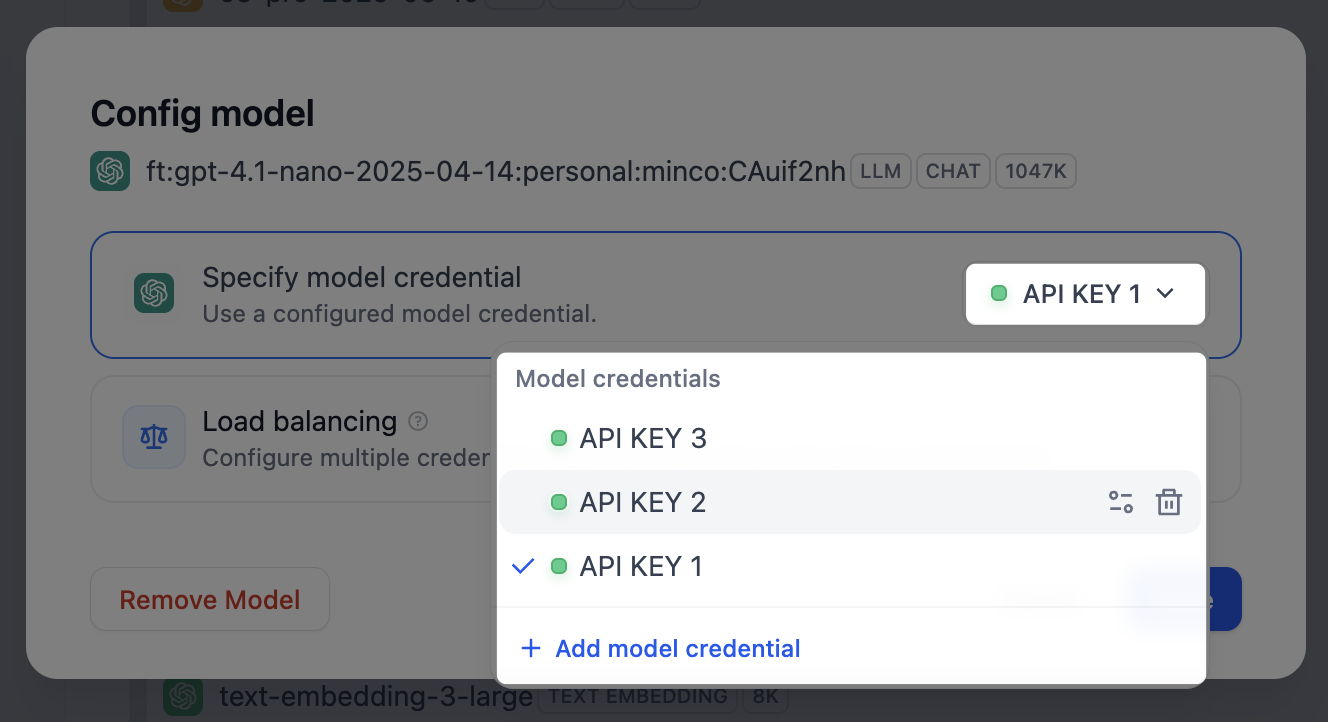 Keys stay here even after the custom model is removed, so you can re-add the model later without re-entering its keys.
Keys stay here even after the custom model is removed, so you can re-add the model later without re-entering its keys.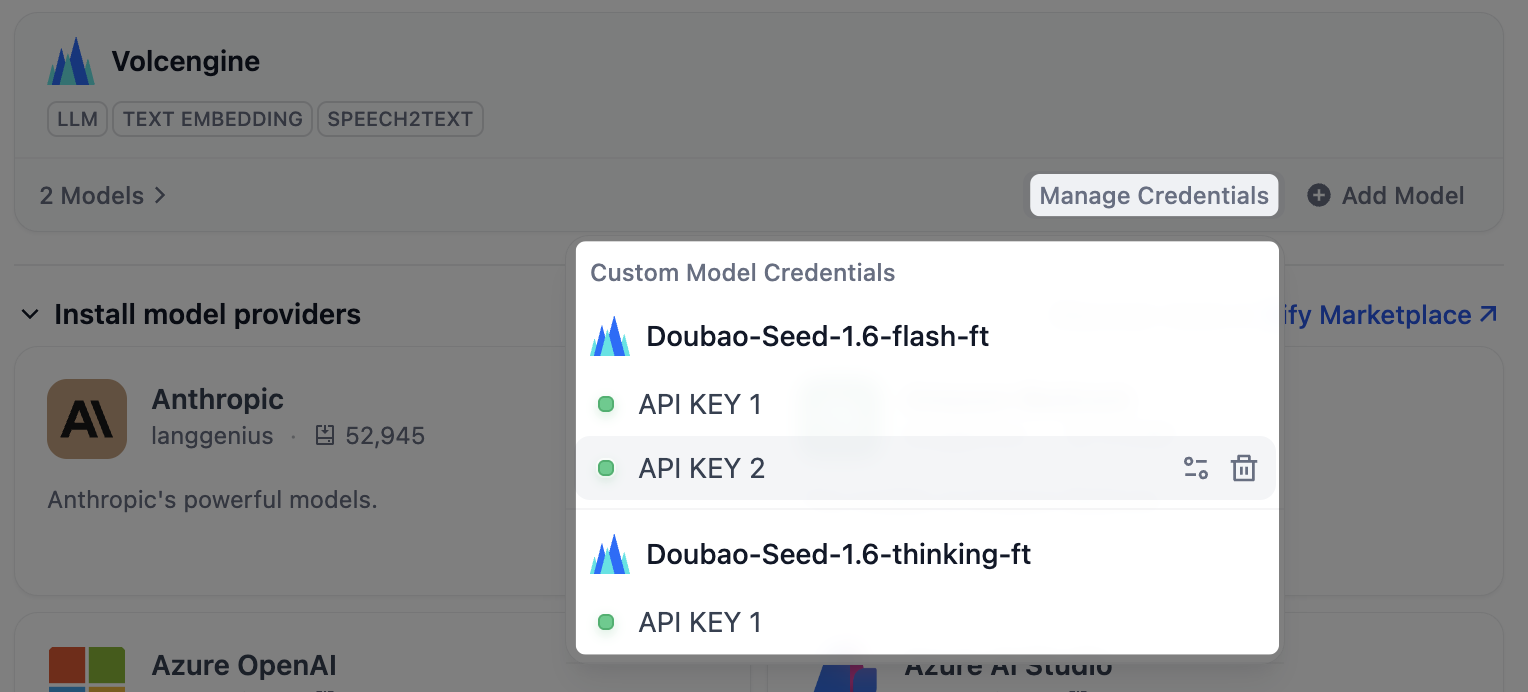
Choose the Models Apps Use by Default
Apps and nodes that don’t pick a model fall back to your workspace defaults. Click Default Models at the top-right corner to set one for each job:- System Reasoning Model: the default for general LLM tasks.
- Embedding Model: indexes and retrieves knowledge base content.
- Rerank Model: reorders retrieval results by relevance.
- Speech-to-Text Model: turns audio into text.
- Text-to-Speech Model: turns text into audio.
Spread Requests Across Keys with Load Balancing Professional Team
When one key handles many requests at once, it can hit the provider’s rate limit and start failing. Use load balancing to spread requests across several keys for the same model, so no single key becomes the bottleneck. Dify rotates through the keys in turn and rests any that hits its limit for a minute before trying it again.- Find the model in the list, click Configure, and select Load Balancing.
-
Click Add credential to add keys to the pool.
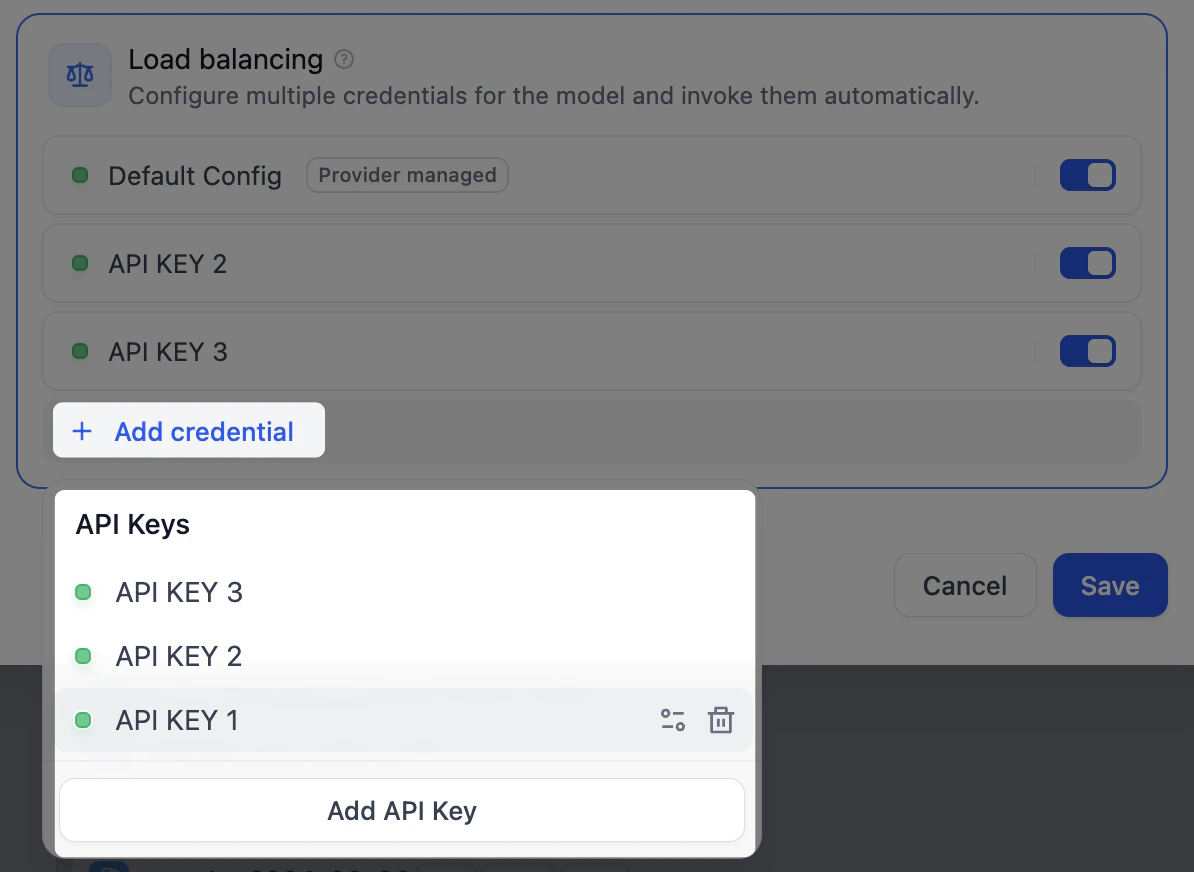
- Turn on at least two keys, then click Save. A model using load balancing shows a marker in the list.
Switch back to a single key anytime; your load balancing setup is kept for later use.