

什么是分段与清洗策略?
什么是分段与清洗策略?
- 分段
- 清洗
分段模式
知识库支持两种分段模式:通用模式与父子模式。如果你是首次创建知识库,建议选择父子模式。注意:原 “自动分段与清洗” 模式已自动更新为 “通用” 模式。无需进行任何更改,原知识库保持默认设置即可继续使用。选定分段模式并完成知识库的创建后,后续无法变更。知识库内新增的文档也将遵循同样的分段模式。
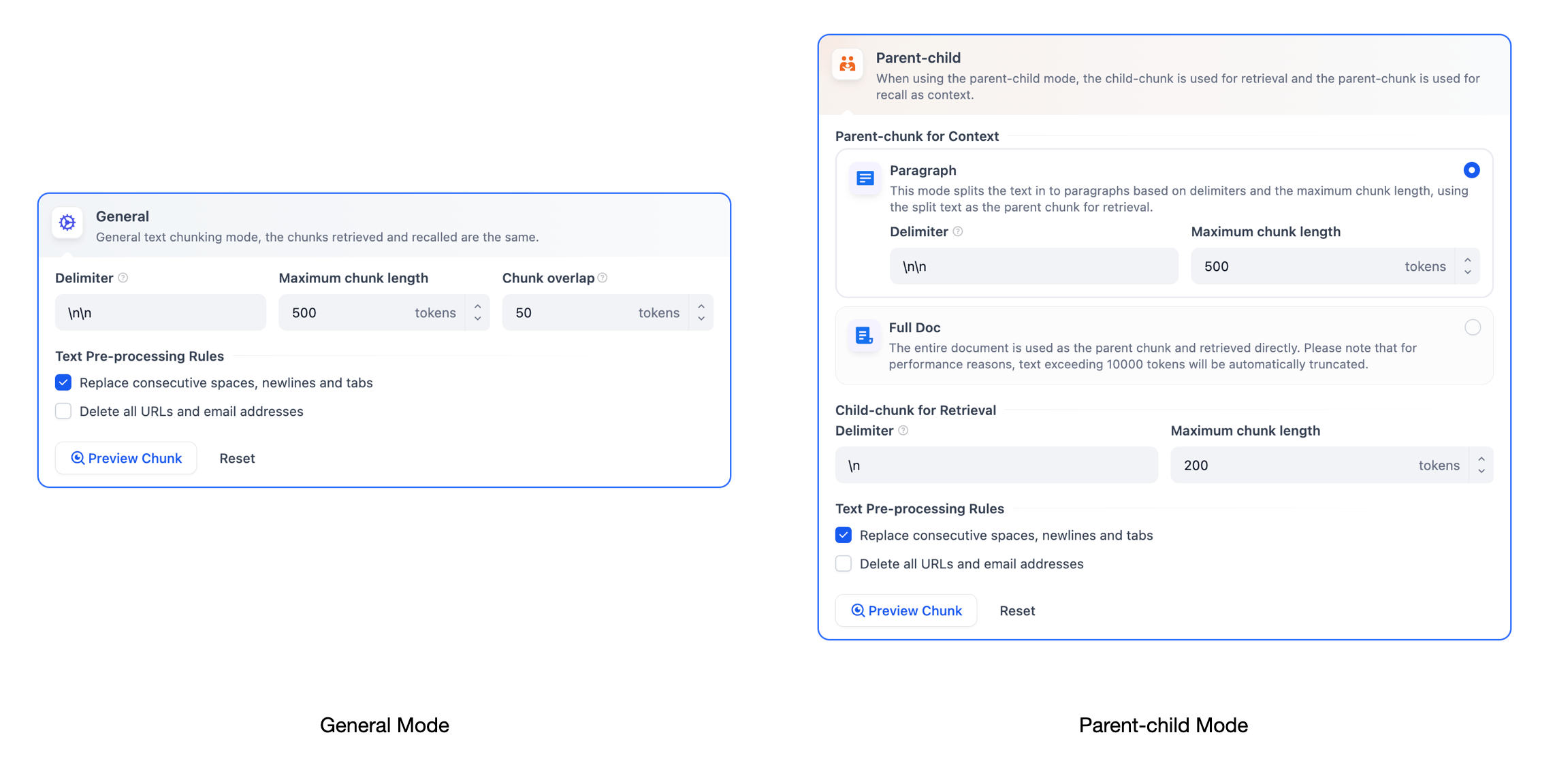
通用模式
系统按照用户自定义的规则将内容拆分为独立的分段。当用户输入问题后,系统自动分析问题中的关键词,并计算关键词与知识库中各内容分段的相关度。根据相关度排序,选取最相关的内容分段并发送给 LLM,辅助其处理与更有效地回答。 在该模式下,你需要根据不同的文档格式或场景要求,参考以下设置项,手动设置文本的分段规则。- 分段标识符:系统将在文本出现分段标识符时自动执行分段。默认值为
\n\n,即按照文章段落进行分块。下图是不同语法的文本分段效果:
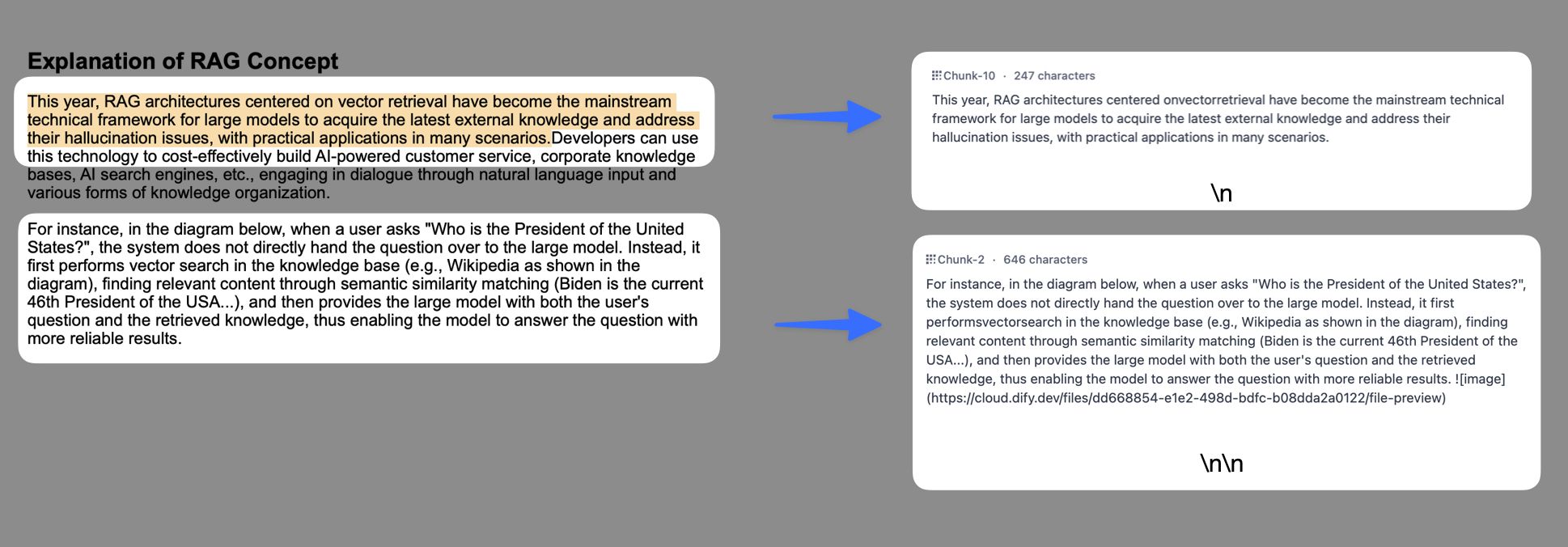
- 分段最大长度:指定分段内的文本字符数最大上限,超出该长度时将强制分段。
- 分段重叠长度:指的是在对数据进行分段时,段与段之间存在一定的重叠部分。这种重叠可以帮助提高信息的保留和分析的准确性,提升召回效果。建议设置为分段长度 Tokens 数的 10-25%。
- 替换连续的空格、换行符和制表符
- 删除所有 URL 和电子邮件地址
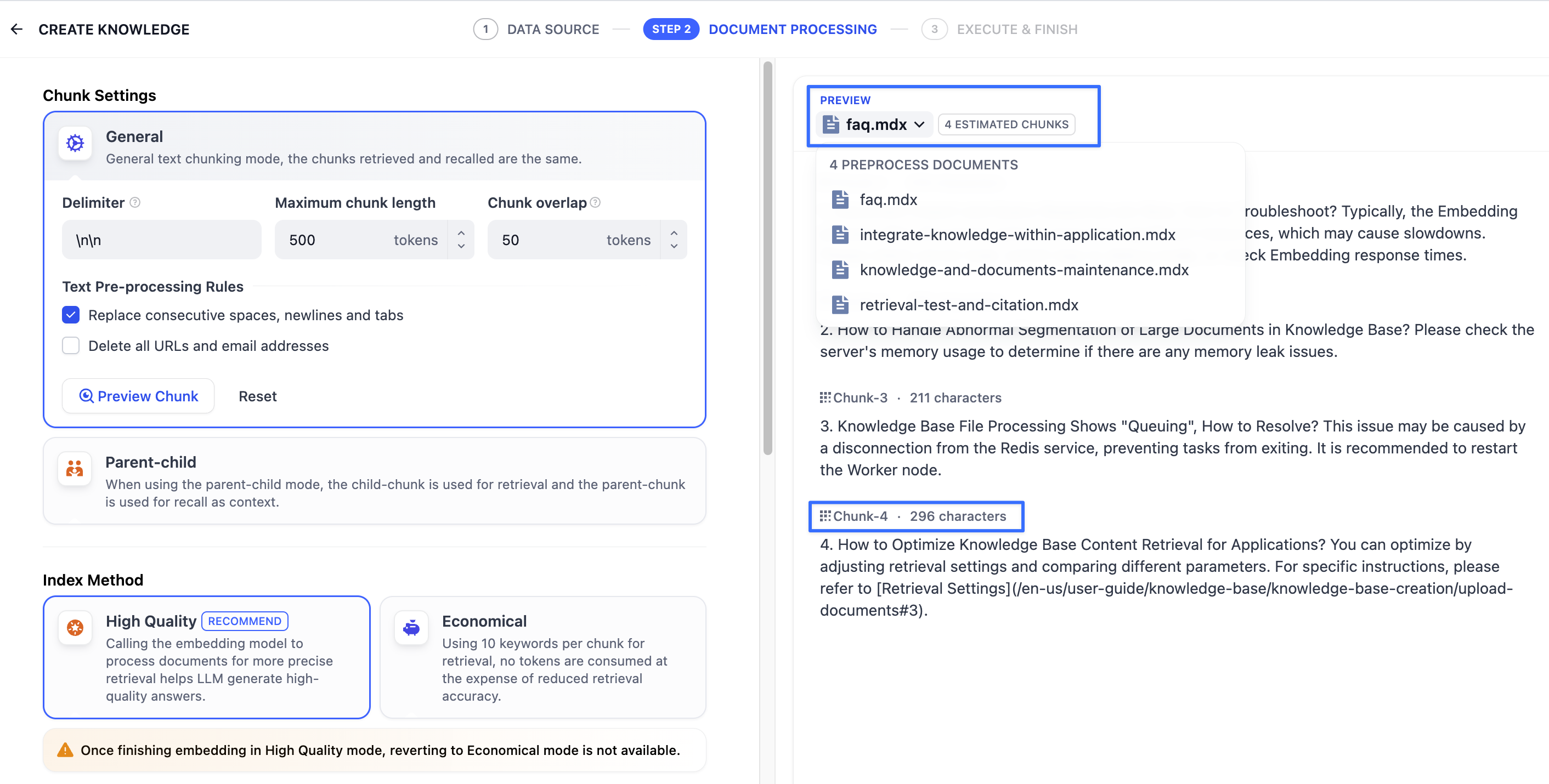 分段规则设置完成后,接下来需指定索引方式。支持”高质量索引”和”经济索引”,详细说明请参考设定索引方法。
分段规则设置完成后,接下来需指定索引方式。支持”高质量索引”和”经济索引”,详细说明请参考设定索引方法。
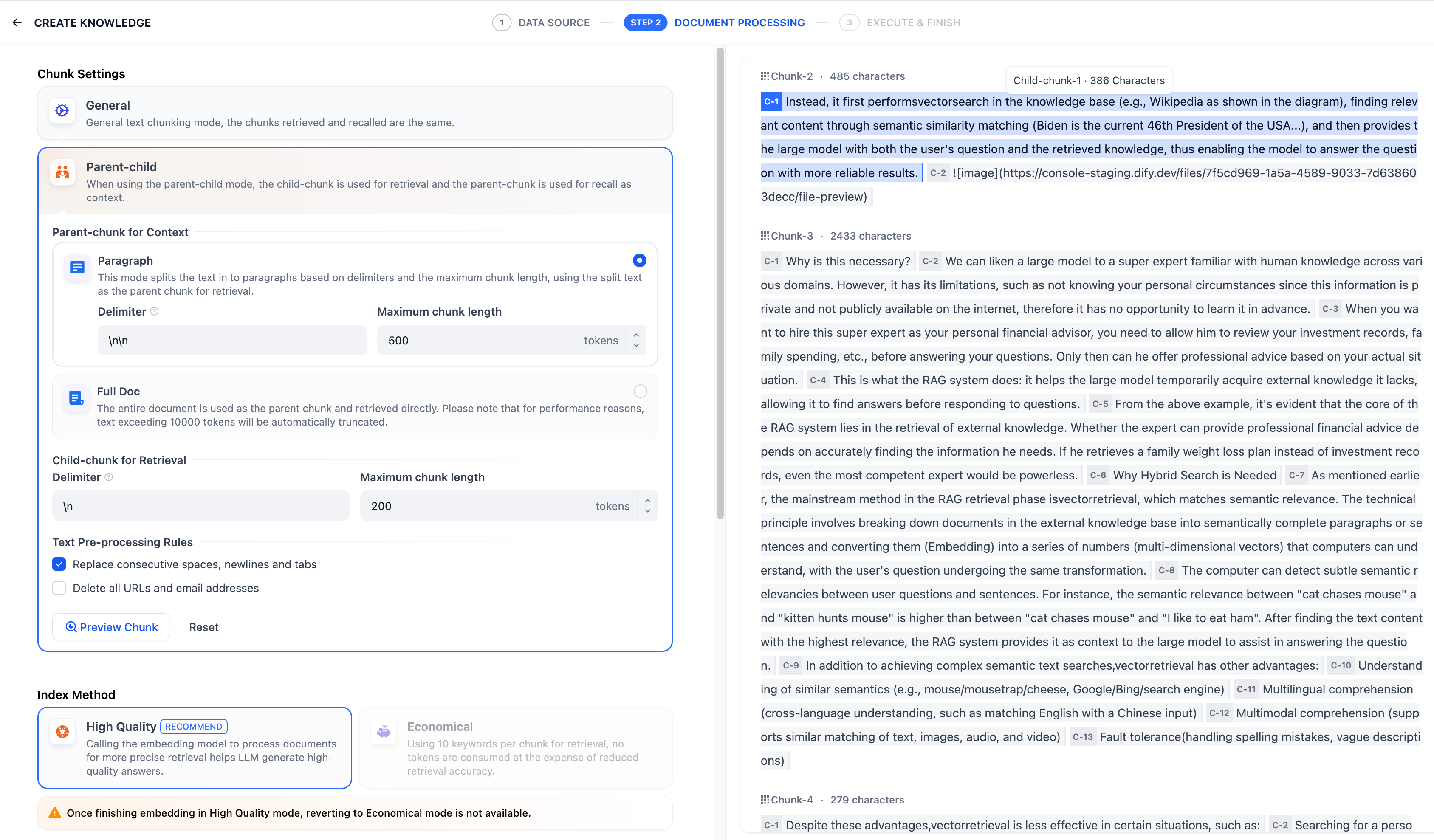
父子模式
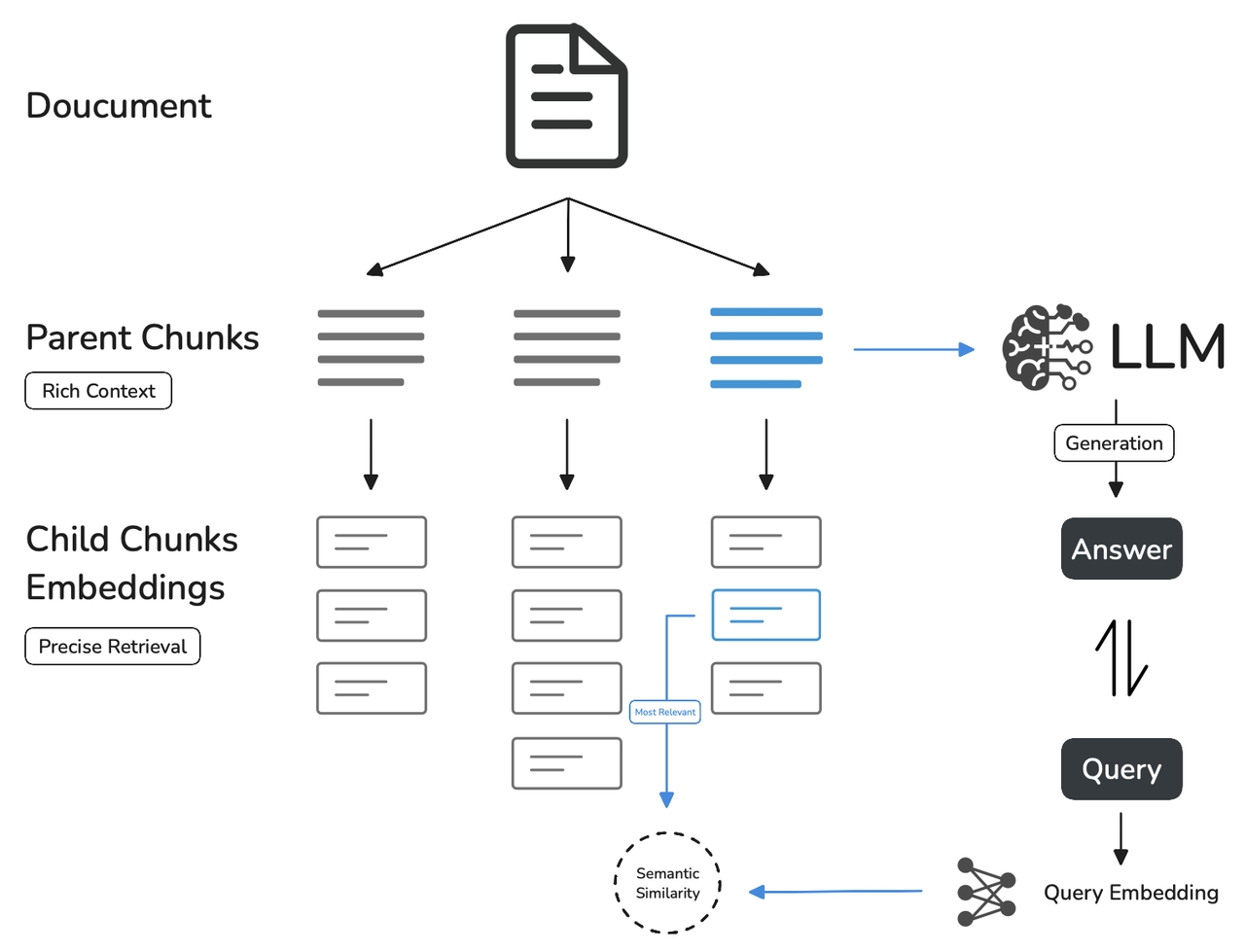
与通用模式相比,父子模式采用双层分段结构来平衡检索的精确度和上下文信息,让精准匹配与全面的上下文信息二者兼得。 其中,父区块(Parent-chunk)保持较大的文本单位(如段落),提供丰富的上下文信息;子区块(Child-chunk)则是较小的文本单位(如句子),用于精确检索。系统首先通过子区块进行精确检索以确保相关性,然后获取对应的父区块来补充上下文信息,从而在生成响应时既保证准确性又能提供完整的背景信息。你可以通过设置分隔符和最大长度来自定义父子区块的分段方式。 例如在 AI 智能客服场景下,用户输入的问题将定位至解决方案文档内某个具体的句子,随后将该句子所在的段落或章节,联同发送至 LLM,补全该问题的完整背景信息,给出更加精准的回答。 其基本机制包括:- 子分段匹配查询:
- 将文档拆分为较小、集中的信息单元(例如一句话),更加精准的匹配用户所输入的问题。
- 子分段能快速提供与用户需求最相关的初步结果。
- 父分段提供上下文:
- 将包含匹配子分段的更大部分(如段落、章节甚至整个文档)视作父分段并提供给大语言模型(LLM)。
- 父分段能为 LLM 提供完整的背景信息,避免遗漏重要细节,帮助 LLM 输出更贴合知识库内容的回答。
 在该模式下,你需要根据不同的文档格式或场景要求,手动分别设置父子分段的分段规则。
父分段:
父分段设置提供以下分段选项:
在该模式下,你需要根据不同的文档格式或场景要求,手动分别设置父子分段的分段规则。
父分段:
父分段设置提供以下分段选项:
- 段落
-
分段标识符:系统将在文本出现分段标识符时自动执行分段。默认值为
\n\n,即按照文本段落分段。 - 分段最大长度:指定分段内的文本字符数最大上限,超出该长度时将强制分段。
- 全文
 子分段:
子分段文本是在父文本分段基础上,由分隔符规则切分而成,用于查找和匹配与问题关键词最相关和直接的信息。如果使用默认的子分段规则,通常呈现以下分段效果:
子分段:
子分段文本是在父文本分段基础上,由分隔符规则切分而成,用于查找和匹配与问题关键词最相关和直接的信息。如果使用默认的子分段规则,通常呈现以下分段效果:
- 当父分段为段落时,子分段对应各个段落中的单个句子。
- 父分段为全文时,子分段对应全文中各个单独的句子。
- 分段标识符:系统将在文本出现分段标识符时自动执行分段。默认值为
\n,即按照句子进行分段。 - 分段最大长度:指定分段内的文本字符数最大上限,超出该长度时将强制分段。
- 替换连续的空格、换行符和制表符
- 删除所有 URL 和电子邮件地址
 为了确保内容检索的准确性,父子分段模式仅支持使用”高质量索引”。
为了确保内容检索的准确性,父子分段模式仅支持使用”高质量索引”。
两种模式的区别是什么?
两者的主要区别在于内容区块的分段形式。通用模式的分段结果为多个独立的内容分段,而父子模式采用双层结构进行内容分段,即单个父分段的内容(文档全文或段落)内包含多个子分段内容(句子)。 不同的分段方式将影响 LLM 对于知识库内容的检索效果。在相同文档中,采用父子检索所提供的上下文信息会更全面,且在精准度方面也能保持较高水平,大大优于传统的单层通用检索方式。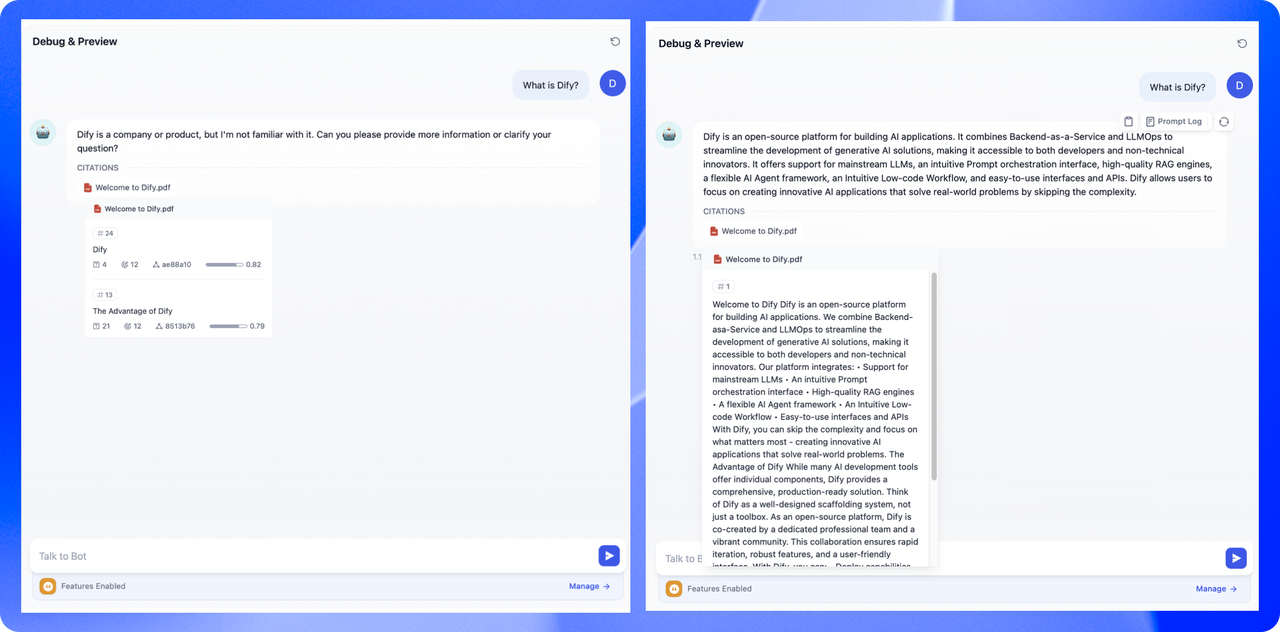
阅读更多
选定分段模式后,接下来你可以参考以下文档分别设定索引方式和检索方式,完成知识库的创建。设定索引方法
了解更多高质量索引和经济索引的详细信息