

Documentation Index
Fetch the complete documentation index at: https://docs.dify.ai/llms.txt
Use this file to discover all available pages before exploring further.
⚠️ 本文档由 AI 自动翻译。如有任何不准确之处,请参考 英文原版。
快速开始
数分钟内开始构建强大的应用
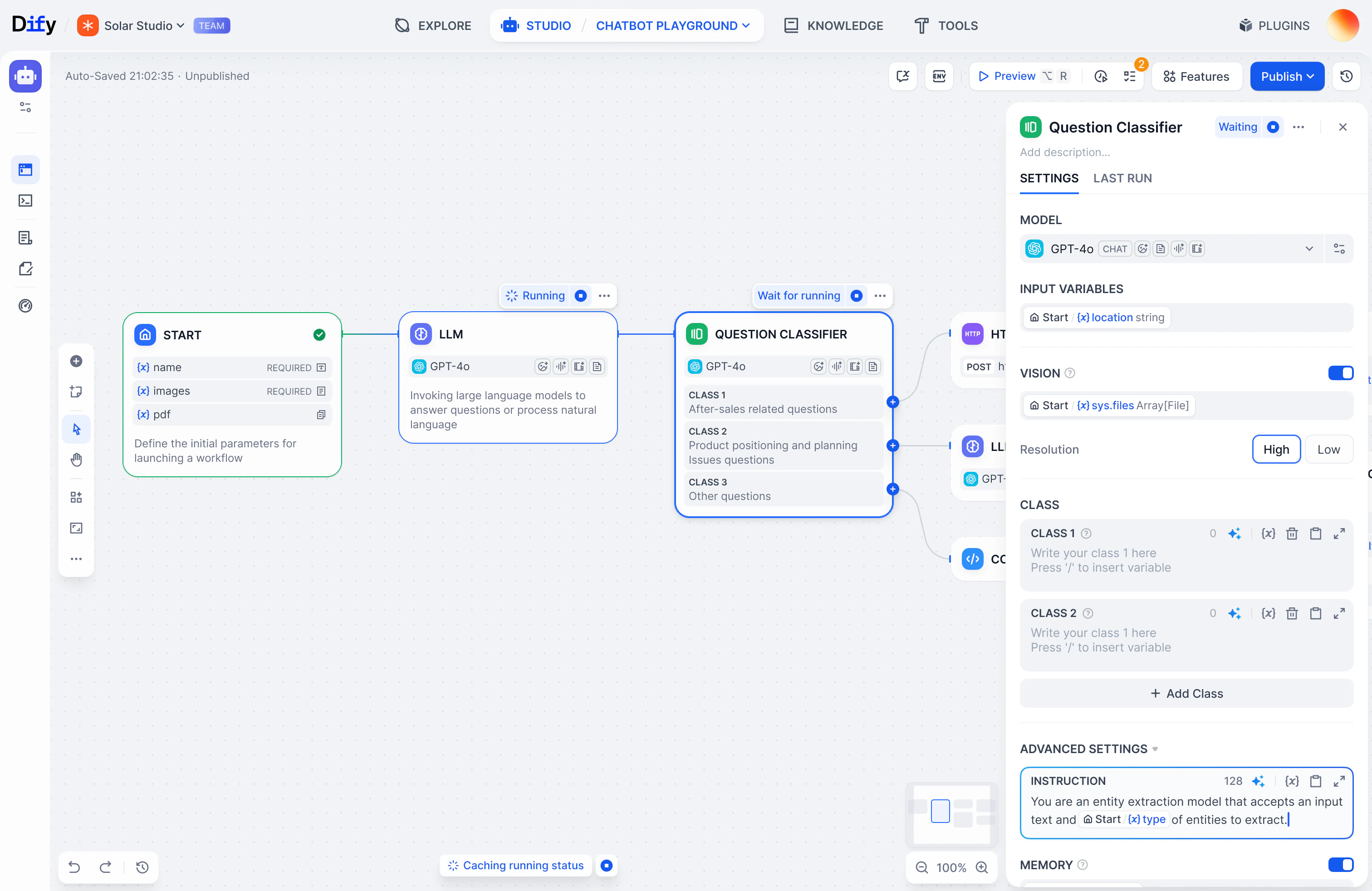
概念
核心 Dify 构建模块解释
自部署
在你的笔记本电脑/服务器上安装 Dify
论坛
与社区交流心得
更新日志
查看过往版本的更新内容
教程
Dify 用例示例演练
Dify 这个名字来自 Do It For You。