> ## Documentation Index
> Fetch the complete documentation index at: https://docs.dify.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# 30 分間クイックスタート
> サンプルアプリを通じて Dify を深く理解
> このドキュメントは AI によって自動翻訳されています。不正確な部分がある場合は、[英語版](/en/quick-start) を参照してください。
このクイックスタートは **Dify Cloud** を使用します。無料で始められ、AI クレジットが含まれ、セットアップ不要の最短ルートです。自分で運用したい場合は、[Dify をセルフホスト](/ja/self-host/deploy/quick-start/docker-compose)してから、同じ手順をご自身のインスタンスで実行できます。
このステップバイステップのチュートリアルでは、ゼロからマルチプラットフォームコンテンツジェネレーターを作成します。
基本的な LLM 統合を超えて、強力な Dify ノードを使用して、より速く、より簡単に洗練された AI アプリケーションを構築する方法を発見します。
このチュートリアルの終わりまでに、あなたが投げかけるあらゆるコンテンツ(テキスト、ドキュメント、画像)を取り込み、好みの音声とトーンを追加し、選択した言語で洗練されたプラットフォーム固有のソーシャルメディア投稿を生成するワークフローを作成します。
完全なワークフローを以下に示します。構築中はいつでも参照して、軌道に乗っていることを確認し、すべてのノードがどのように連携するかを確認してください。
 ## 始める前に
[cloud.dify.ai](https://cloud.dify.ai) にアクセスして無料でサインアップします。
新しいアカウントは Sandbox プランから始まり、OpenAI、Anthropic、Gemini などのプロバイダーのモデルを呼び出すための 200 AI クレジットが含まれています。
Sandbox プランの 200 AI クレジットは 1 回限りの割り当てで、毎月更新されません。
**設定** > **モデルプロバイダー** に移動し、OpenAI プラグインをインストールします。このチュートリアルでは `gpt-5.2` を使用します。
Sandbox の AI クレジットを使用している間は API キーは不要です。プラグインはインストール後すぐに使用できます。独自の API キーを設定して使用することもできます。
1. **モデルプロバイダー** ページの右上隅で、**システムモデル設定** をクリックします。
2. **システム推論モデル** を `gpt-5.2` に設定します。これがワークフローのデフォルトモデルになります。
## ステップ 1:新しいワークフローの作成
1. **スタジオ** に移動し、**空白から作成** > **ワークフロー**を選択します。
2. ワークフローに`マルチプラットフォームコンテンツジェネレーター`という名前を付けて、**作成** をクリックします。自動的にワークフローキャンバスに移動し、構築を開始します。
3. ユーザー入力ノードを選択してワークフローを開始します。
## ステップ 2:オーケストレーションと設定
言及されていない設定はデフォルト値のままにしてください。
ノードと変数に明確で説明的な名前を付けて、識別と参照が簡単になるようにします。
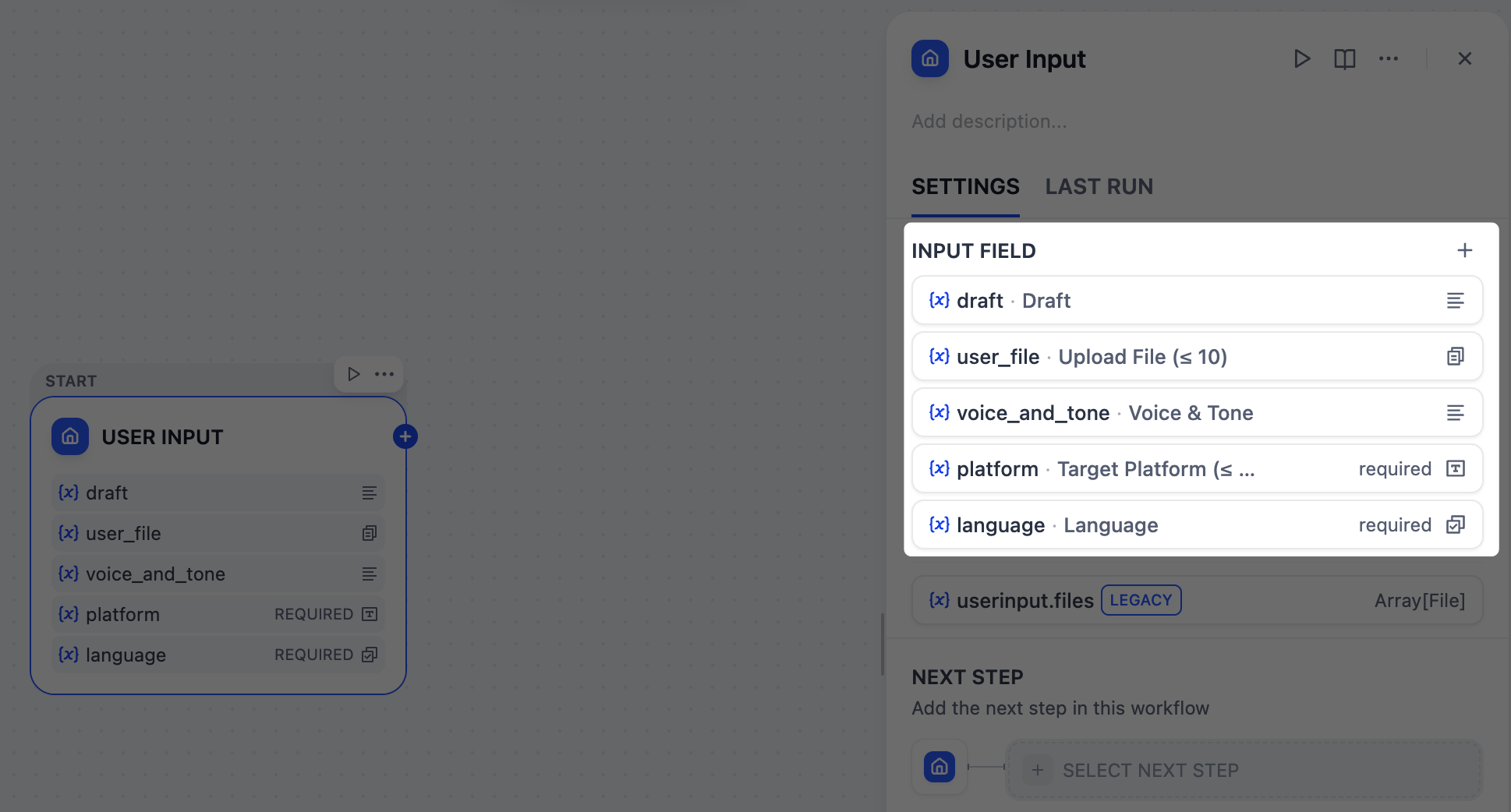
### 1. ユーザー入力を収集:ユーザー入力ノード
まず、コンテンツジェネレーターを実行するためにユーザーから収集する情報を定義する必要があります。ドラフトテキスト、ターゲットプラットフォーム、希望のトーン、参考資料などです。
ユーザー入力ノードは、これらを簡単に設定できる場所です。ここに追加する各入力フィールドは、すべての下流ノードが参照して使用できる変数になります。
ユーザー入力ノードをクリックして設定パネルを開き、次の入力フィールドを追加します。
* フィールドタイプ:`段落`
* 変数名:`draft`
* ラベル名:`ドラフト`
* 最大長:`2048`
* 必須:`はい`
* フィールドタイプ:`ファイルリスト`
* 変数名:`user_file`
* ラベル名:`ファイルをアップロード (≤ 10)`
* サポートファイルタイプ:`ドキュメント`、`画像`
* アップロードファイルタイプ:`両方`
* 最大アップロード数:`10`
* 必須:`いいえ`
* フィールドタイプ:`段落`
* 変数名:`voice_and_tone`
* ラベル名:`ボイス&トーン`
* 最大長:`2048`
* 必須:`いいえ`
* フィールドタイプ:`短いテキスト`
* 変数名:`platform`
* ラベル名:`ターゲットプラットフォーム (≤ 10)`
* 最大長:`256`
* 必須:`はい`
* フィールドタイプ:`選択`
* 変数名:`language`
* ラベル名:`言語`
* オプション:
* `English`
* `日本語`
* `简体中文`
* 必須:`はい`
## 始める前に
[cloud.dify.ai](https://cloud.dify.ai) にアクセスして無料でサインアップします。
新しいアカウントは Sandbox プランから始まり、OpenAI、Anthropic、Gemini などのプロバイダーのモデルを呼び出すための 200 AI クレジットが含まれています。
Sandbox プランの 200 AI クレジットは 1 回限りの割り当てで、毎月更新されません。
**設定** > **モデルプロバイダー** に移動し、OpenAI プラグインをインストールします。このチュートリアルでは `gpt-5.2` を使用します。
Sandbox の AI クレジットを使用している間は API キーは不要です。プラグインはインストール後すぐに使用できます。独自の API キーを設定して使用することもできます。
1. **モデルプロバイダー** ページの右上隅で、**システムモデル設定** をクリックします。
2. **システム推論モデル** を `gpt-5.2` に設定します。これがワークフローのデフォルトモデルになります。
## ステップ 1:新しいワークフローの作成
1. **スタジオ** に移動し、**空白から作成** > **ワークフロー**を選択します。
2. ワークフローに`マルチプラットフォームコンテンツジェネレーター`という名前を付けて、**作成** をクリックします。自動的にワークフローキャンバスに移動し、構築を開始します。
3. ユーザー入力ノードを選択してワークフローを開始します。
## ステップ 2:オーケストレーションと設定
言及されていない設定はデフォルト値のままにしてください。
ノードと変数に明確で説明的な名前を付けて、識別と参照が簡単になるようにします。
### 1. ユーザー入力を収集:ユーザー入力ノード
まず、コンテンツジェネレーターを実行するためにユーザーから収集する情報を定義する必要があります。ドラフトテキスト、ターゲットプラットフォーム、希望のトーン、参考資料などです。
ユーザー入力ノードは、これらを簡単に設定できる場所です。ここに追加する各入力フィールドは、すべての下流ノードが参照して使用できる変数になります。
ユーザー入力ノードをクリックして設定パネルを開き、次の入力フィールドを追加します。
* フィールドタイプ:`段落`
* 変数名:`draft`
* ラベル名:`ドラフト`
* 最大長:`2048`
* 必須:`はい`
* フィールドタイプ:`ファイルリスト`
* 変数名:`user_file`
* ラベル名:`ファイルをアップロード (≤ 10)`
* サポートファイルタイプ:`ドキュメント`、`画像`
* アップロードファイルタイプ:`両方`
* 最大アップロード数:`10`
* 必須:`いいえ`
* フィールドタイプ:`段落`
* 変数名:`voice_and_tone`
* ラベル名:`ボイス&トーン`
* 最大長:`2048`
* 必須:`いいえ`
* フィールドタイプ:`短いテキスト`
* 変数名:`platform`
* ラベル名:`ターゲットプラットフォーム (≤ 10)`
* 最大長:`256`
* 必須:`はい`
* フィールドタイプ:`選択`
* 変数名:`language`
* ラベル名:`言語`
* オプション:
* `English`
* `日本語`
* `简体中文`
* 必須:`はい`
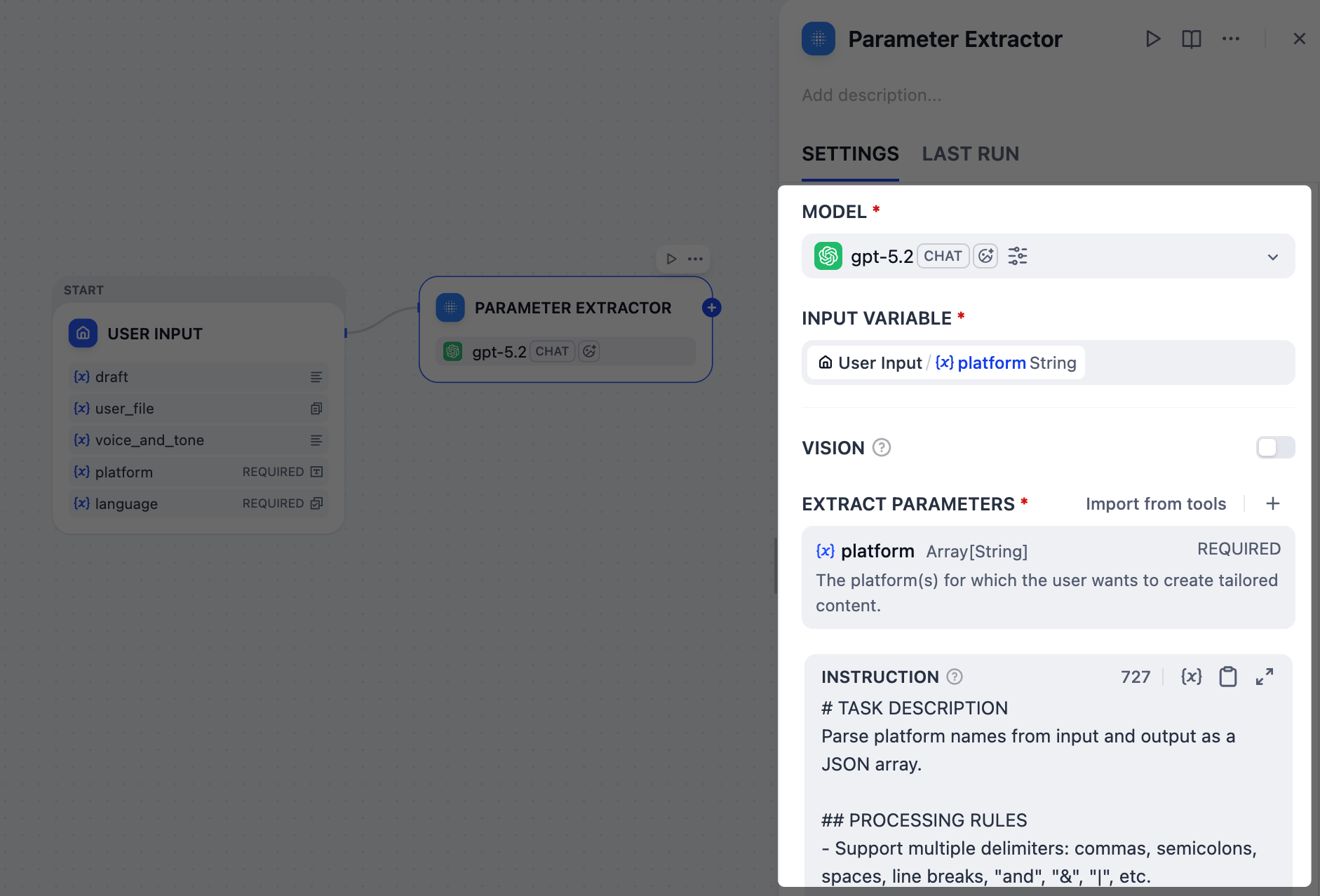
 ### 2. ターゲットプラットフォームの識別:パラメータ抽出器ノード
プラットフォームフィールドは自由形式のテキスト入力を受け入れるため、ユーザーは様々な方法で入力する可能性があります:`x and linkedIn`、`post on Twitter and LinkedIn`、さらには`Twitter + LinkedIn please`など。
しかし、下流ノードが確実に動作できる`["Twitter", "LinkedIn"]`のようなクリーンで構造化されたリストが必要です。
これはパラメータ抽出器ノードの完璧な仕事です。今回のケースでは、gpt-5.2 モデルを使用してユーザーの自然言語を分析し、これらすべてのバリエーションを認識し、標準化された配列を出力します。
ユーザー入力ノードの後に、パラメータ抽出器ノードを追加して設定します:
1. **入力変数** フィールドで、`User Input/platform`を選択します。
2. 抽出パラメータを追加します:
* 名前:`platform`
* タイプ:`Array[String]`
* 説明:`The platform(s) for which the user wants to create tailored content.`
* 必須:`はい`
3. **指示** フィールドに、LLM のパラメータ抽出をガイドする以下を貼り付けます:
```markdown INSTRUCTION theme={null}
# TASK DESCRIPTION
Parse platform names from input and output as a JSON array.
## PROCESSING RULES
- Support multiple delimiters: commas, semicolons, spaces, line breaks, "and", "&", "|", etc.
- Standardize common platform name variants (twitter/X→Twitter, insta→Instagram, etc.)
- Remove duplicates and invalid entries
- Preserve unknown but reasonable platform names
- Preserve the original language of platform names
## OUTPUT REQUIREMENTS
- Success: ["Platform1", "Platform2"]
- No platforms found: [No platforms identified. Please enter a valid platform name.]
## EXAMPLES
- Input: "twitter, linkedin" → ["Twitter", "LinkedIn"]
- Input: "x and insta" → ["Twitter", "Instagram"]
- Input: "invalid content" → [No platforms identified. Please enter a valid platform name.]
```
無効な入力に対して特定のエラーメッセージを出力するよう LLM に指示したことに注意してください。これは次のステップでワークフローの終了トリガーとして機能します。
### 2. ターゲットプラットフォームの識別:パラメータ抽出器ノード
プラットフォームフィールドは自由形式のテキスト入力を受け入れるため、ユーザーは様々な方法で入力する可能性があります:`x and linkedIn`、`post on Twitter and LinkedIn`、さらには`Twitter + LinkedIn please`など。
しかし、下流ノードが確実に動作できる`["Twitter", "LinkedIn"]`のようなクリーンで構造化されたリストが必要です。
これはパラメータ抽出器ノードの完璧な仕事です。今回のケースでは、gpt-5.2 モデルを使用してユーザーの自然言語を分析し、これらすべてのバリエーションを認識し、標準化された配列を出力します。
ユーザー入力ノードの後に、パラメータ抽出器ノードを追加して設定します:
1. **入力変数** フィールドで、`User Input/platform`を選択します。
2. 抽出パラメータを追加します:
* 名前:`platform`
* タイプ:`Array[String]`
* 説明:`The platform(s) for which the user wants to create tailored content.`
* 必須:`はい`
3. **指示** フィールドに、LLM のパラメータ抽出をガイドする以下を貼り付けます:
```markdown INSTRUCTION theme={null}
# TASK DESCRIPTION
Parse platform names from input and output as a JSON array.
## PROCESSING RULES
- Support multiple delimiters: commas, semicolons, spaces, line breaks, "and", "&", "|", etc.
- Standardize common platform name variants (twitter/X→Twitter, insta→Instagram, etc.)
- Remove duplicates and invalid entries
- Preserve unknown but reasonable platform names
- Preserve the original language of platform names
## OUTPUT REQUIREMENTS
- Success: ["Platform1", "Platform2"]
- No platforms found: [No platforms identified. Please enter a valid platform name.]
## EXAMPLES
- Input: "twitter, linkedin" → ["Twitter", "LinkedIn"]
- Input: "x and insta" → ["Twitter", "Instagram"]
- Input: "invalid content" → [No platforms identified. Please enter a valid platform name.]
```
無効な入力に対して特定のエラーメッセージを出力するよう LLM に指示したことに注意してください。これは次のステップでワークフローの終了トリガーとして機能します。
 ### 3. プラットフォーム抽出結果の検証:IF/ELSE ノード
ユーザーが `ohhhhhh` や `BookFace` のような無効なプラットフォーム名を入力した場合はどうなるでしょうか?無駄なコンテンツを生成するために時間とトークンを無駄にしたくありません。
そのような場合、IF/ELSE ノードを使用してワークフローを早期に停止する分岐を作成できます。パラメータ抽出器ノードからのエラーメッセージをチェックする条件を設定し、そのメッセージが検出された場合、ワークフローは直接出力ノードにルーティングされます。
### 3. プラットフォーム抽出結果の検証:IF/ELSE ノード
ユーザーが `ohhhhhh` や `BookFace` のような無効なプラットフォーム名を入力した場合はどうなるでしょうか?無駄なコンテンツを生成するために時間とトークンを無駄にしたくありません。
そのような場合、IF/ELSE ノードを使用してワークフローを早期に停止する分岐を作成できます。パラメータ抽出器ノードからのエラーメッセージをチェックする条件を設定し、そのメッセージが検出された場合、ワークフローは直接出力ノードにルーティングされます。
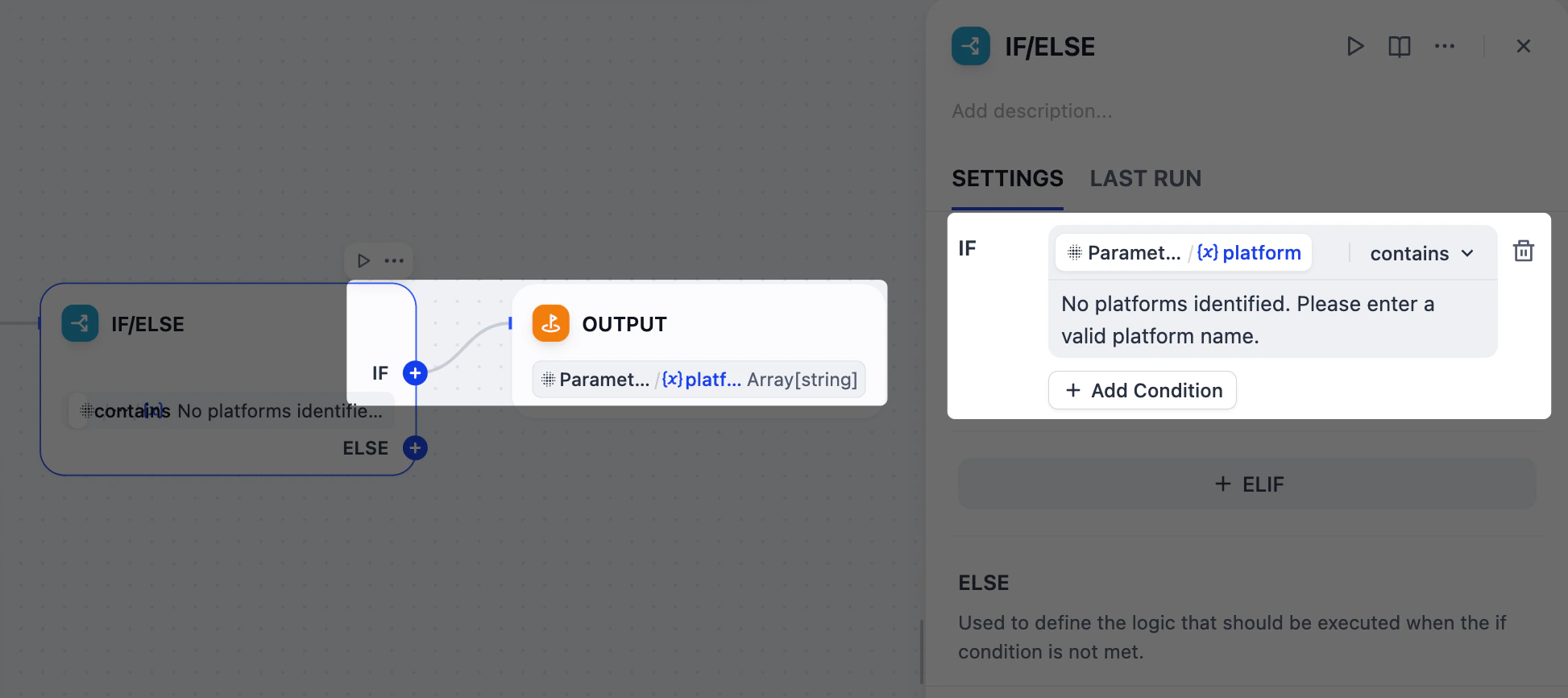 1. パラメータ抽出器ノードの後に、IF/ELSE ノードを追加します。
2. IF/ELSEノードのパネルで、**IF** 条件を定義します:
**IF** `Parameter Extractor/platform` **含む** `No platforms identified. Please enter a valid platform name.`
3. IF/ELSEノードの後、IFブランチに出力ノードを追加します。
4. 出力ノードのパネルで、`Parameter Extractor/platform`を出力変数として設定します。
### 4. アップロードされたファイルをタイプ別に分離:リスト演算子ノード
ユーザーは参考資料として画像とドキュメントの両方をアップロードできますが、`gpt-5.2` ではこの 2 つのタイプは異なる処理が必要です:画像はビジョン機能を通じて直接解釈できますが、ドキュメントはモデルが処理できるようにまずテキストに変換する必要があります。
これを管理するために、2 つのリスト演算子ノードを使用して、アップロードされたファイルをフィルタリングし、別々のブランチに分割します(1 つは画像用、1 つはドキュメント用)。
1. パラメータ抽出器ノードの後に、IF/ELSE ノードを追加します。
2. IF/ELSEノードのパネルで、**IF** 条件を定義します:
**IF** `Parameter Extractor/platform` **含む** `No platforms identified. Please enter a valid platform name.`
3. IF/ELSEノードの後、IFブランチに出力ノードを追加します。
4. 出力ノードのパネルで、`Parameter Extractor/platform`を出力変数として設定します。
### 4. アップロードされたファイルをタイプ別に分離:リスト演算子ノード
ユーザーは参考資料として画像とドキュメントの両方をアップロードできますが、`gpt-5.2` ではこの 2 つのタイプは異なる処理が必要です:画像はビジョン機能を通じて直接解釈できますが、ドキュメントはモデルが処理できるようにまずテキストに変換する必要があります。
これを管理するために、2 つのリスト演算子ノードを使用して、アップロードされたファイルをフィルタリングし、別々のブランチに分割します(1 つは画像用、1 つはドキュメント用)。
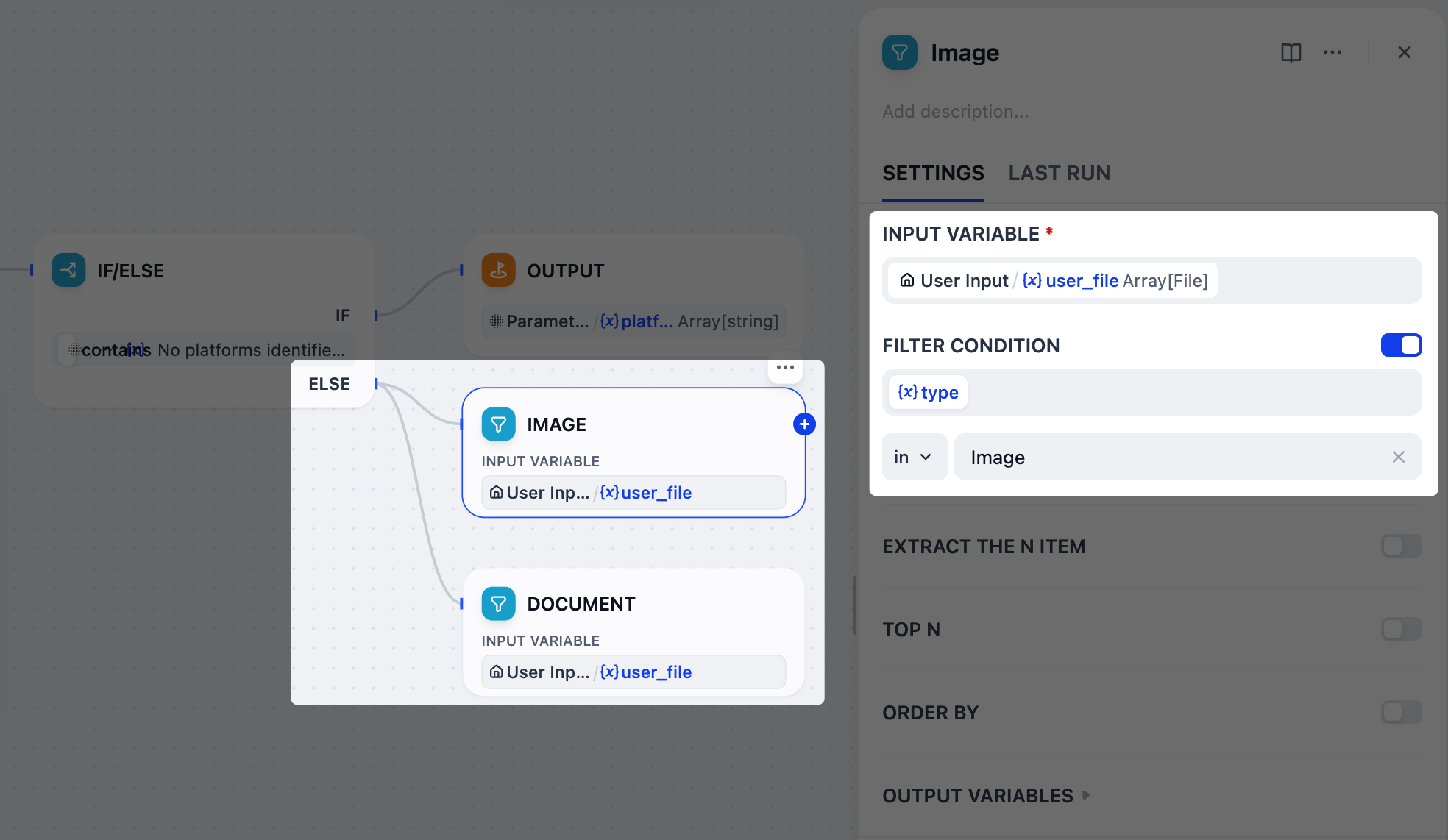 1. IF/ELSEノードの後、ELSEブランチに **2 つ** の並列リスト演算子ノードを追加します。
2. 1 つのノードを`画像`、もう 1 つを`ドキュメント`に名前を変更します。
3. 画像ノードを設定します:
1. `User Input/user_file`を入力変数として設定します。
2. **フィルタ条件** を有効にします:`{x}type` **に** `Image`。
4. ドキュメントノードを設定します:
1. `User Input/user_file`を入力変数として設定します。
2. **フィルタ条件** を有効にします:`{x}type` **に** `Doc`。
### 5. ドキュメントからテキストを抽出:テキスト抽出ノード
`gpt-5.2` は PDF や DOCX などのアップロードされたドキュメントを直接読むことはできないため、まずプレーンテキストに変換する必要があります。
これがまさにテキスト抽出ノードが行うことです。ドキュメントファイルを入力として受け取り、次のステップのためにクリーンで使用可能なテキストを出力します。
1. IF/ELSEノードの後、ELSEブランチに **2 つ** の並列リスト演算子ノードを追加します。
2. 1 つのノードを`画像`、もう 1 つを`ドキュメント`に名前を変更します。
3. 画像ノードを設定します:
1. `User Input/user_file`を入力変数として設定します。
2. **フィルタ条件** を有効にします:`{x}type` **に** `Image`。
4. ドキュメントノードを設定します:
1. `User Input/user_file`を入力変数として設定します。
2. **フィルタ条件** を有効にします:`{x}type` **に** `Doc`。
### 5. ドキュメントからテキストを抽出:テキスト抽出ノード
`gpt-5.2` は PDF や DOCX などのアップロードされたドキュメントを直接読むことはできないため、まずプレーンテキストに変換する必要があります。
これがまさにテキスト抽出ノードが行うことです。ドキュメントファイルを入力として受け取り、次のステップのためにクリーンで使用可能なテキストを出力します。
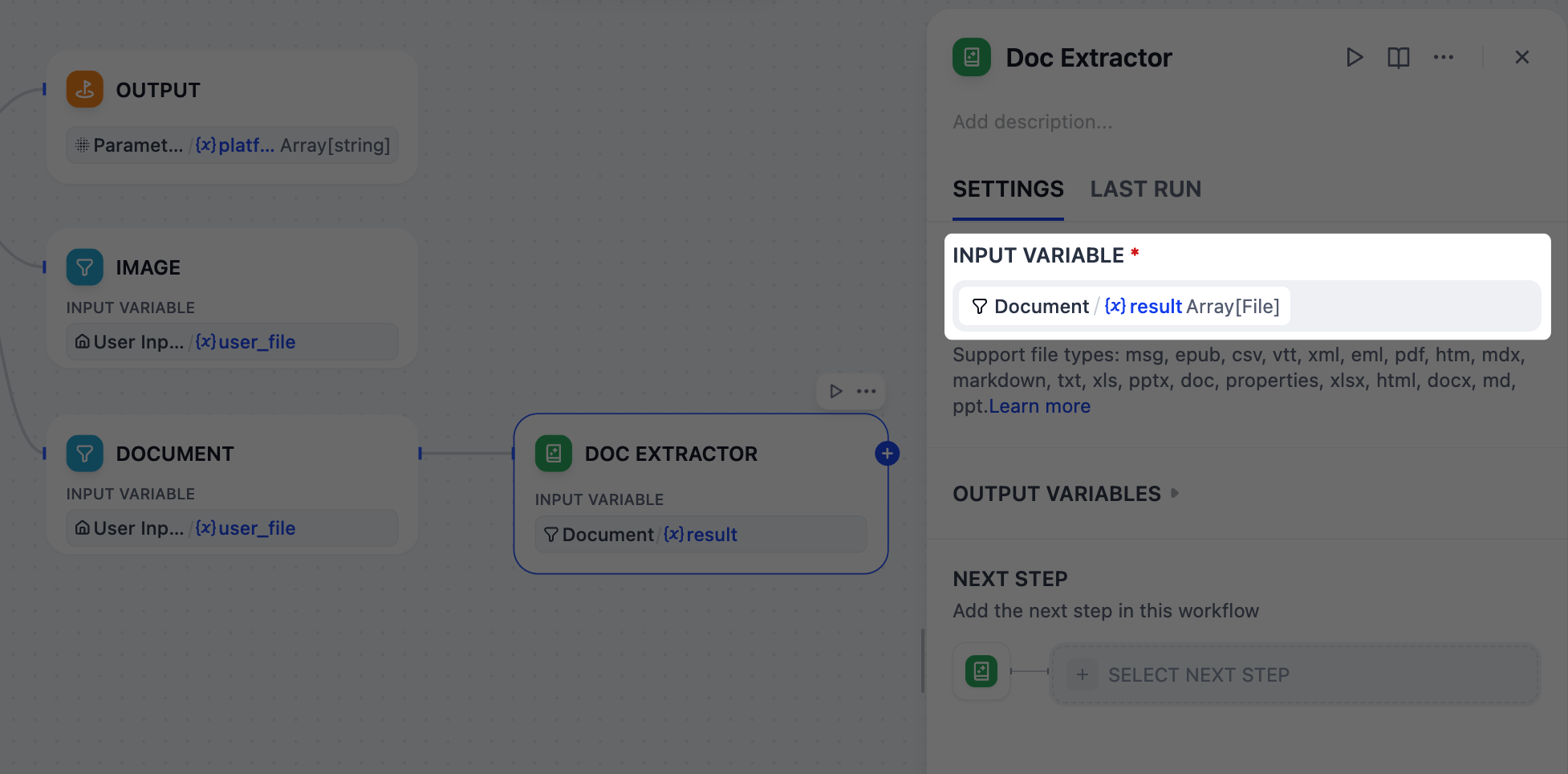 1. ドキュメントノードの後に、テキスト抽出ノードを追加します。
2. テキスト抽出ノードのパネルで、`Document/result`を入力変数として設定します。
### 6. すべての参考資料を統合:LLM ノード
ユーザーが複数の参考タイプ(ドラフトテキスト、ドキュメント、画像)を同時に提供する場合、それらを一つのまとまった要約に統合する必要があります。
LLM ノードは、すべての散在する部分を分析してこのタスクを処理し、後続のコンテンツ生成をガイドする包括的なコンテキストを作成します。
1. ドキュメントノードの後に、テキスト抽出ノードを追加します。
2. テキスト抽出ノードのパネルで、`Document/result`を入力変数として設定します。
### 6. すべての参考資料を統合:LLM ノード
ユーザーが複数の参考タイプ(ドラフトテキスト、ドキュメント、画像)を同時に提供する場合、それらを一つのまとまった要約に統合する必要があります。
LLM ノードは、すべての散在する部分を分析してこのタスクを処理し、後続のコンテンツ生成をガイドする包括的なコンテキストを作成します。
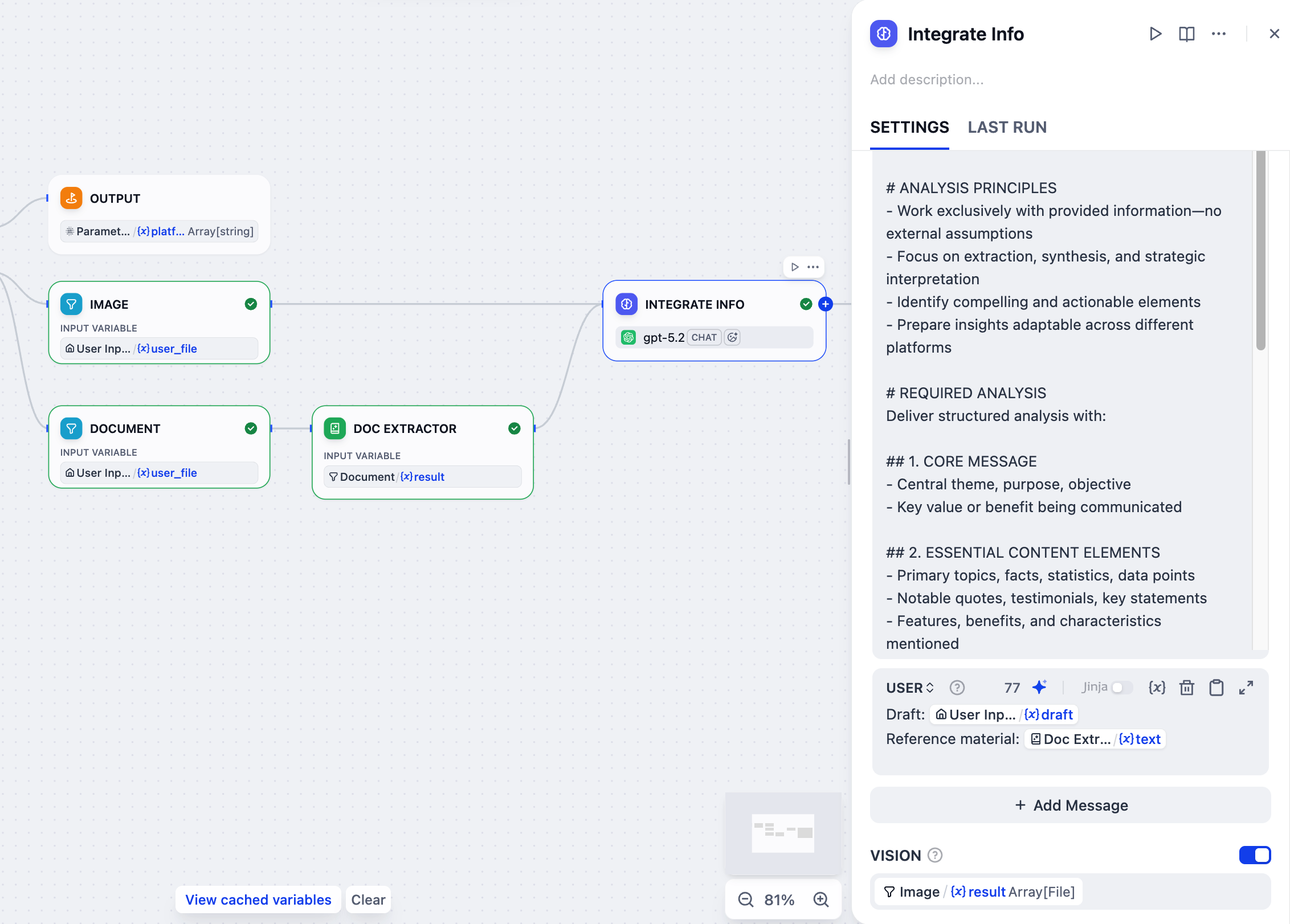 1. テキスト抽出ノードの後に、LLM ノードを追加します。
2. 画像ノードもこの LLM ノードに接続します。
3. LLM ノードをクリックして設定します:
1. `情報統合`に名前を変更します。
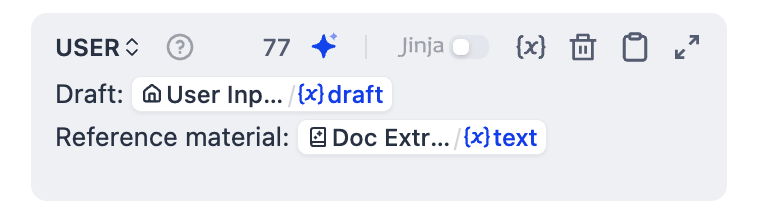
2. **VISION** を有効にし、`Image/result`をビジョン変数として設定します。
3. システム指示フィールドに、以下を貼り付けます:
```markdown wrap theme={null}
# ROLE & TASK
You are a content strategist. Analyze the provided draft and reference materials (if any), then create a comprehensive content foundation for multi-platform social media optimization.
# ANALYSIS PRINCIPLES
- Work exclusively with provided information—no external assumptions
- Focus on extraction, synthesis, and strategic interpretation
- Identify compelling and actionable elements
- Prepare insights adaptable across different platforms
# REQUIRED ANALYSIS
Deliver structured analysis with:
## 1. CORE MESSAGE
- Central theme, purpose, objective
- Key value or benefit being communicated
## 2. ESSENTIAL CONTENT ELEMENTS
- Primary topics, facts, statistics, data points
- Notable quotes, testimonials, key statements
- Features, benefits, characteristics mentioned
- Dates, locations, contextual details
## 3. STRATEGIC INSIGHTS
- What makes content compelling/unique
- Emotional/rational appeals present
- Credibility factors, proof points
- Competitive advantages highlighted
## 4. ENGAGEMENT OPPORTUNITIES
- Discussion points, questions emerging
- Calls-to-action, next steps suggested
- Interactive/participation opportunities
- Trending themes touched upon
## 5. PLATFORM OPTIMIZATION FOUNDATION
- High-impact: Quick, shareable formats
- Professional: Business-focused discussions
- Community: Interaction and sharing
- Visual: Enhanced with strong visuals
## 6. SUPPORTING DETAILS
- Metrics, numbers, quantifiable results
- Direct quotes, testimonials
- Technical details, specifications
- Background context available
```
4. **メッセージを追加** をクリックしてユーザーメッセージを追加し、以下を貼り付けます。`{`または`/`を入力して、`Doc Extractor/text`と`User Input/draft`をリスト内の対応する変数に置き換えます。
```markdown USER theme={null}
Draft: User Input/draft
Reference material: Doc Extractor/text
```
1. テキスト抽出ノードの後に、LLM ノードを追加します。
2. 画像ノードもこの LLM ノードに接続します。
3. LLM ノードをクリックして設定します:
1. `情報統合`に名前を変更します。
2. **VISION** を有効にし、`Image/result`をビジョン変数として設定します。
3. システム指示フィールドに、以下を貼り付けます:
```markdown wrap theme={null}
# ROLE & TASK
You are a content strategist. Analyze the provided draft and reference materials (if any), then create a comprehensive content foundation for multi-platform social media optimization.
# ANALYSIS PRINCIPLES
- Work exclusively with provided information—no external assumptions
- Focus on extraction, synthesis, and strategic interpretation
- Identify compelling and actionable elements
- Prepare insights adaptable across different platforms
# REQUIRED ANALYSIS
Deliver structured analysis with:
## 1. CORE MESSAGE
- Central theme, purpose, objective
- Key value or benefit being communicated
## 2. ESSENTIAL CONTENT ELEMENTS
- Primary topics, facts, statistics, data points
- Notable quotes, testimonials, key statements
- Features, benefits, characteristics mentioned
- Dates, locations, contextual details
## 3. STRATEGIC INSIGHTS
- What makes content compelling/unique
- Emotional/rational appeals present
- Credibility factors, proof points
- Competitive advantages highlighted
## 4. ENGAGEMENT OPPORTUNITIES
- Discussion points, questions emerging
- Calls-to-action, next steps suggested
- Interactive/participation opportunities
- Trending themes touched upon
## 5. PLATFORM OPTIMIZATION FOUNDATION
- High-impact: Quick, shareable formats
- Professional: Business-focused discussions
- Community: Interaction and sharing
- Visual: Enhanced with strong visuals
## 6. SUPPORTING DETAILS
- Metrics, numbers, quantifiable results
- Direct quotes, testimonials
- Technical details, specifications
- Background context available
```
4. **メッセージを追加** をクリックしてユーザーメッセージを追加し、以下を貼り付けます。`{`または`/`を入力して、`Doc Extractor/text`と`User Input/draft`をリスト内の対応する変数に置き換えます。
```markdown USER theme={null}
Draft: User Input/draft
Reference material: Doc Extractor/text
```
 ### 7. 各プラットフォーム向けにカスタマイズされたコンテンツを作成:イテレーションノード
統合された参照とターゲットプラットフォームの準備ができたので、イテレーションノードを使用して各プラットフォーム向けにカスタマイズされた投稿を生成しましょう。
このノードはプラットフォームのリストをループし、各プラットフォーム用のサブワークフローを実行します:まず特定のプラットフォームのスタイルガイドラインとベストプラクティスを分析し、次に利用可能なすべての情報に基づいて最適化されたコンテンツを生成します。
### 7. 各プラットフォーム向けにカスタマイズされたコンテンツを作成:イテレーションノード
統合された参照とターゲットプラットフォームの準備ができたので、イテレーションノードを使用して各プラットフォーム向けにカスタマイズされた投稿を生成しましょう。
このノードはプラットフォームのリストをループし、各プラットフォーム用のサブワークフローを実行します:まず特定のプラットフォームのスタイルガイドラインとベストプラクティスを分析し、次に利用可能なすべての情報に基づいて最適化されたコンテンツを生成します。
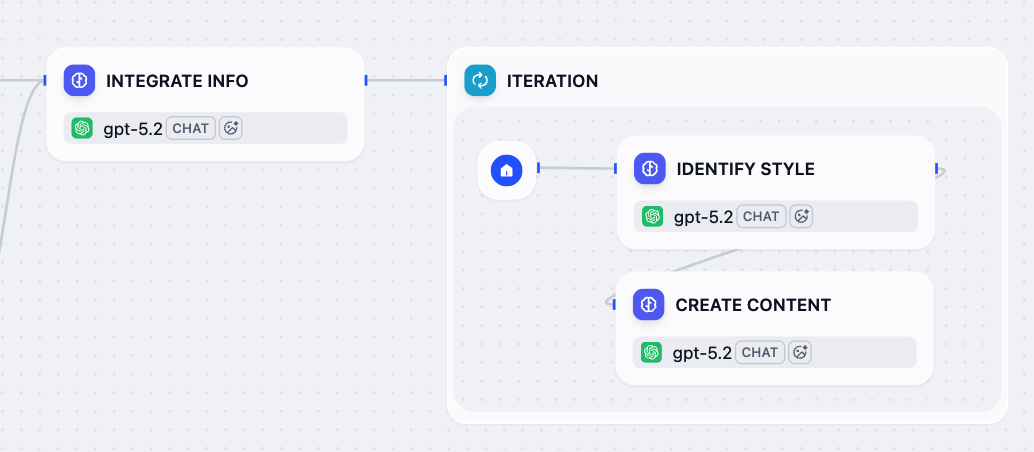 1. 情報統合ノードの後に、イテレーションノードを追加します。
2. イテレーションノード内に、LLM ノードを追加して設定します:
1. `スタイル識別`に名前を変更します。
2. システム指示フィールドに、以下を貼り付けます:
```markdown wrap theme={null}
# ROLE & TASK
You are a social media expert. Analyze the platform and provide content creation guidelines.
# ANALYSIS REQUIRED
For the given platform, provide:
## 1. PLATFORM PROFILE
- Platform type and category
- Target audience characteristics
## 2. CONTENT GUIDELINES
- Optimal content length (characters/words)
- Recommended tone (professional/casual/conversational)
- Formatting best practices (line breaks, emojis, etc.)
## 3. ENGAGEMENT STRATEGY
- Hashtag recommendations (quantity and style)
- Call-to-action best practices
- Algorithm optimization tips
## 4. TECHNICAL SPECS
- Character/word limits
- Visual content requirements
- Special formatting needs
## 5. PLATFORM-SPECIFIC NOTES
- Unique features or recent changes
- Industry-specific considerations
- Community engagement approaches
# OUTPUT REQUIREMENTS
- For recognized platforms: Provide specific guidelines
- For unknown platforms: Base recommendations on similar platforms
- Focus on actionable, practical advice
- Be concise but comprehensive
```
3. **メッセージを追加** をクリックしてユーザーメッセージを追加し、以下を貼り付けます。`{`または`/`を入力して、`Current Iteration/item`をリスト内の対応する変数に置き換えます。
```markdown USER theme={null}
Platform: Current Iteration/item
```
3. スタイル識別ノードの後に、別の LLM ノードを追加して設定します:
1. `コンテンツ作成`に名前を変更します。
2. システム指示フィールドに、以下を貼り付けます:
```markdown wrap theme={null}
# ROLE & TASK
You are an expert social media content creator. Generate publication-ready content that matches platform guidelines, incorporates source information, and follows specified voice/tone and language requirements.
# LANGUAGE REQUIREMENT
- Generate ALL content exclusively in the target language specified in the user message. You MUST write the entire post in that language, regardless of the language of any source materials.
- No mixing of languages whatsoever
- Adapt platform terminology to the target language
# CONTENT REQUIREMENTS
- Follow platform guidelines exactly (format, length, tone, hashtags)
- Integrate source information effectively (key messages, data, value props)
- Apply voice & tone consistently (if provided)
- Optimize for platform-specific engagement
- Ensure cultural appropriateness for the specified language
# OUTPUT FORMAT
- Generate ONLY the final social media post content. No explanations or meta-commentary. Content must be immediately copy-paste ready.
- Maximum heading level: ## (H2) - never use # (H1)
- No horizontal dividers: avoid ---
# QUALITY CHECKLIST
✅ Platform guidelines followed
✅ Source information integrated
✅ Voice/tone consistent (when provided)
✅ Language consistency maintained
✅ Engagement optimized
✅ Publication ready
```
3. **メッセージを追加** をクリックしてユーザーメッセージを追加し、以下を貼り付けます。`{`または`/`を入力して、すべての入力をリスト内の対応する変数に置き換えます。
```markdown USER theme={null}
Platform Name: Current Iteration/item
Target Language: User Input/language
Platform Guidelines: Identify Style/text
Source Information: Integrate Info/text
Voice & Tone: User Input/voice_and_tone
```
4. 構造化出力を有効にします。
これにより、LLM の応答から特定の情報をより信頼性の高い方法で抽出できます。これは次のステップで最終出力をフォーマットする際に重要です。
1. 情報統合ノードの後に、イテレーションノードを追加します。
2. イテレーションノード内に、LLM ノードを追加して設定します:
1. `スタイル識別`に名前を変更します。
2. システム指示フィールドに、以下を貼り付けます:
```markdown wrap theme={null}
# ROLE & TASK
You are a social media expert. Analyze the platform and provide content creation guidelines.
# ANALYSIS REQUIRED
For the given platform, provide:
## 1. PLATFORM PROFILE
- Platform type and category
- Target audience characteristics
## 2. CONTENT GUIDELINES
- Optimal content length (characters/words)
- Recommended tone (professional/casual/conversational)
- Formatting best practices (line breaks, emojis, etc.)
## 3. ENGAGEMENT STRATEGY
- Hashtag recommendations (quantity and style)
- Call-to-action best practices
- Algorithm optimization tips
## 4. TECHNICAL SPECS
- Character/word limits
- Visual content requirements
- Special formatting needs
## 5. PLATFORM-SPECIFIC NOTES
- Unique features or recent changes
- Industry-specific considerations
- Community engagement approaches
# OUTPUT REQUIREMENTS
- For recognized platforms: Provide specific guidelines
- For unknown platforms: Base recommendations on similar platforms
- Focus on actionable, practical advice
- Be concise but comprehensive
```
3. **メッセージを追加** をクリックしてユーザーメッセージを追加し、以下を貼り付けます。`{`または`/`を入力して、`Current Iteration/item`をリスト内の対応する変数に置き換えます。
```markdown USER theme={null}
Platform: Current Iteration/item
```
3. スタイル識別ノードの後に、別の LLM ノードを追加して設定します:
1. `コンテンツ作成`に名前を変更します。
2. システム指示フィールドに、以下を貼り付けます:
```markdown wrap theme={null}
# ROLE & TASK
You are an expert social media content creator. Generate publication-ready content that matches platform guidelines, incorporates source information, and follows specified voice/tone and language requirements.
# LANGUAGE REQUIREMENT
- Generate ALL content exclusively in the target language specified in the user message. You MUST write the entire post in that language, regardless of the language of any source materials.
- No mixing of languages whatsoever
- Adapt platform terminology to the target language
# CONTENT REQUIREMENTS
- Follow platform guidelines exactly (format, length, tone, hashtags)
- Integrate source information effectively (key messages, data, value props)
- Apply voice & tone consistently (if provided)
- Optimize for platform-specific engagement
- Ensure cultural appropriateness for the specified language
# OUTPUT FORMAT
- Generate ONLY the final social media post content. No explanations or meta-commentary. Content must be immediately copy-paste ready.
- Maximum heading level: ## (H2) - never use # (H1)
- No horizontal dividers: avoid ---
# QUALITY CHECKLIST
✅ Platform guidelines followed
✅ Source information integrated
✅ Voice/tone consistent (when provided)
✅ Language consistency maintained
✅ Engagement optimized
✅ Publication ready
```
3. **メッセージを追加** をクリックしてユーザーメッセージを追加し、以下を貼り付けます。`{`または`/`を入力して、すべての入力をリスト内の対応する変数に置き換えます。
```markdown USER theme={null}
Platform Name: Current Iteration/item
Target Language: User Input/language
Platform Guidelines: Identify Style/text
Source Information: Integrate Info/text
Voice & Tone: User Input/voice_and_tone
```
4. 構造化出力を有効にします。
これにより、LLM の応答から特定の情報をより信頼性の高い方法で抽出できます。これは次のステップで最終出力をフォーマットする際に重要です。
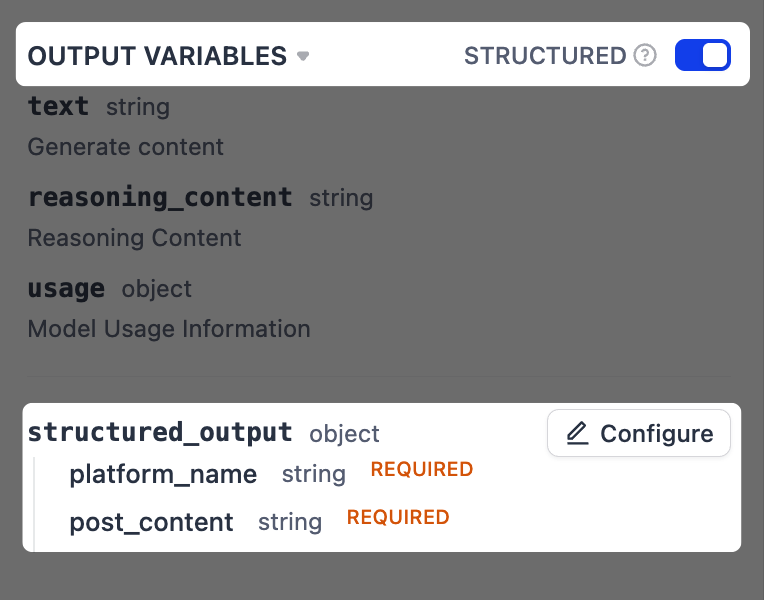 1. **出力変数** の横で、**構造化** をオンに切り替えます。`structured_output`変数が下に表示されます。**設定** をクリックします。
2. ポップアップスキーマエディタで、右上隅の **JSON からインポート** をクリックし、以下を貼り付けます:
```json theme={null}
{
"platform_name": "string",
"post_content": "string"
}
```
1. **出力変数** の横で、**構造化** をオンに切り替えます。`structured_output`変数が下に表示されます。**設定** をクリックします。
2. ポップアップスキーマエディタで、右上隅の **JSON からインポート** をクリックし、以下を貼り付けます:
```json theme={null}
{
"platform_name": "string",
"post_content": "string"
}
```
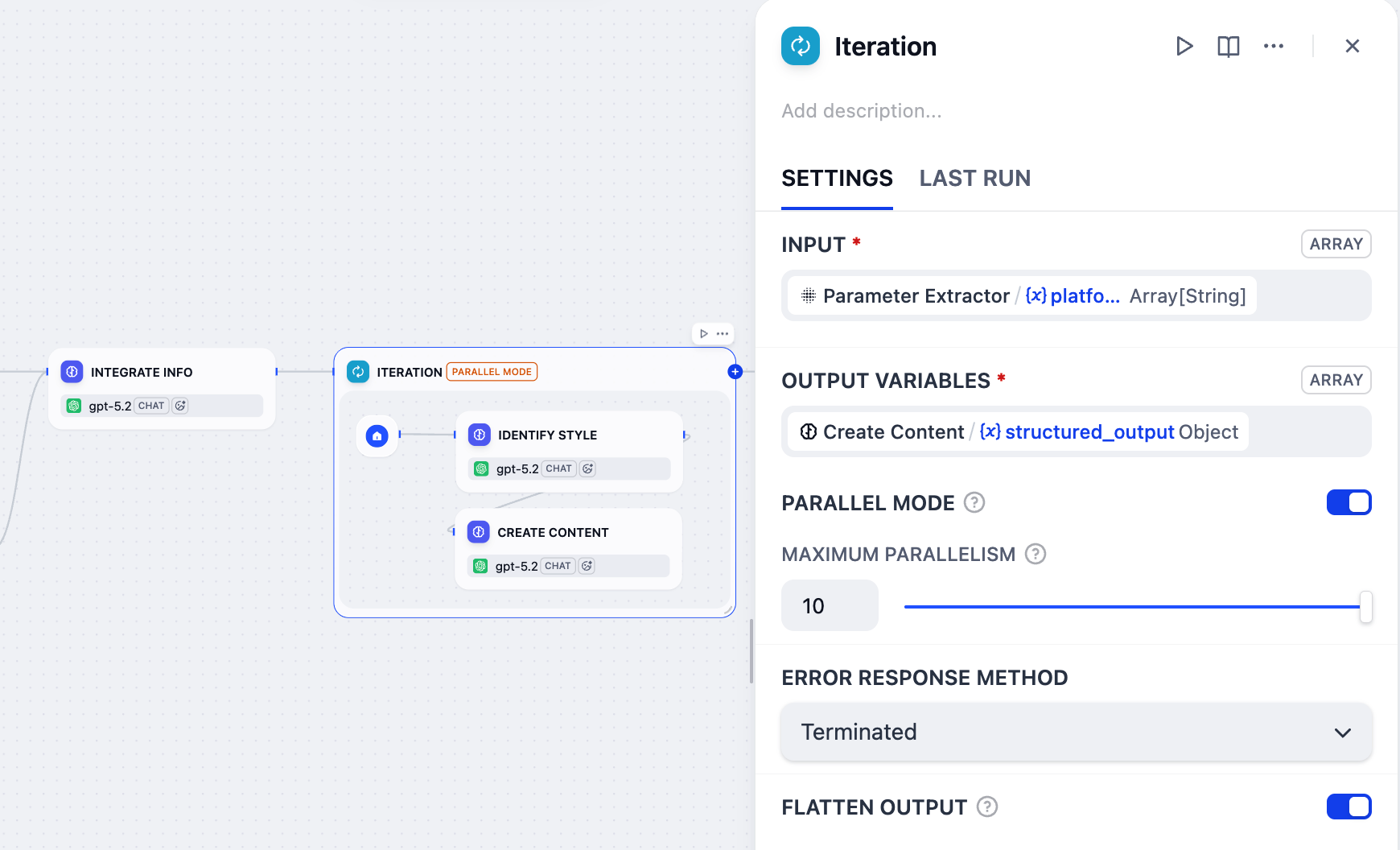
 4. イテレーションノードをクリックして設定します:
1. `Parameter Extractor/platform`を入力変数として設定します。
2. `Create Content/structured_output`を出力変数として設定します。
3. **並列モード** を有効にし、最大並列数を`10`に設定します。
これが、ユーザー入力ノードのターゲットプラットフォームフィールドのラベル名に`(≤10)`を含めた理由です。
4. イテレーションノードをクリックして設定します:
1. `Parameter Extractor/platform`を入力変数として設定します。
2. `Create Content/structured_output`を出力変数として設定します。
3. **並列モード** を有効にし、最大並列数を`10`に設定します。
これが、ユーザー入力ノードのターゲットプラットフォームフィールドのラベル名に`(≤10)`を含めた理由です。
 ### 8. 最終出力をフォーマット:テンプレートノード
イテレーションノードは各プラットフォーム用の投稿を生成しますが、その出力は生のデータ配列(例:`[{"platform_name": "Twitter", "post_content": "..."}]`)であり、あまり読みやすくありません。結果をより明確な形式で提示する必要があります。
ここでテンプレートノードが登場します。[Jinja2](https://jinja.palletsprojects.com/en/stable/) テンプレートを使用してこの生データを整理されたテキストにフォーマットでき、最終出力がユーザーフレンドリーで読みやすいことを保証します。
### 8. 最終出力をフォーマット:テンプレートノード
イテレーションノードは各プラットフォーム用の投稿を生成しますが、その出力は生のデータ配列(例:`[{"platform_name": "Twitter", "post_content": "..."}]`)であり、あまり読みやすくありません。結果をより明確な形式で提示する必要があります。
ここでテンプレートノードが登場します。[Jinja2](https://jinja.palletsprojects.com/en/stable/) テンプレートを使用してこの生データを整理されたテキストにフォーマットでき、最終出力がユーザーフレンドリーで読みやすいことを保証します。
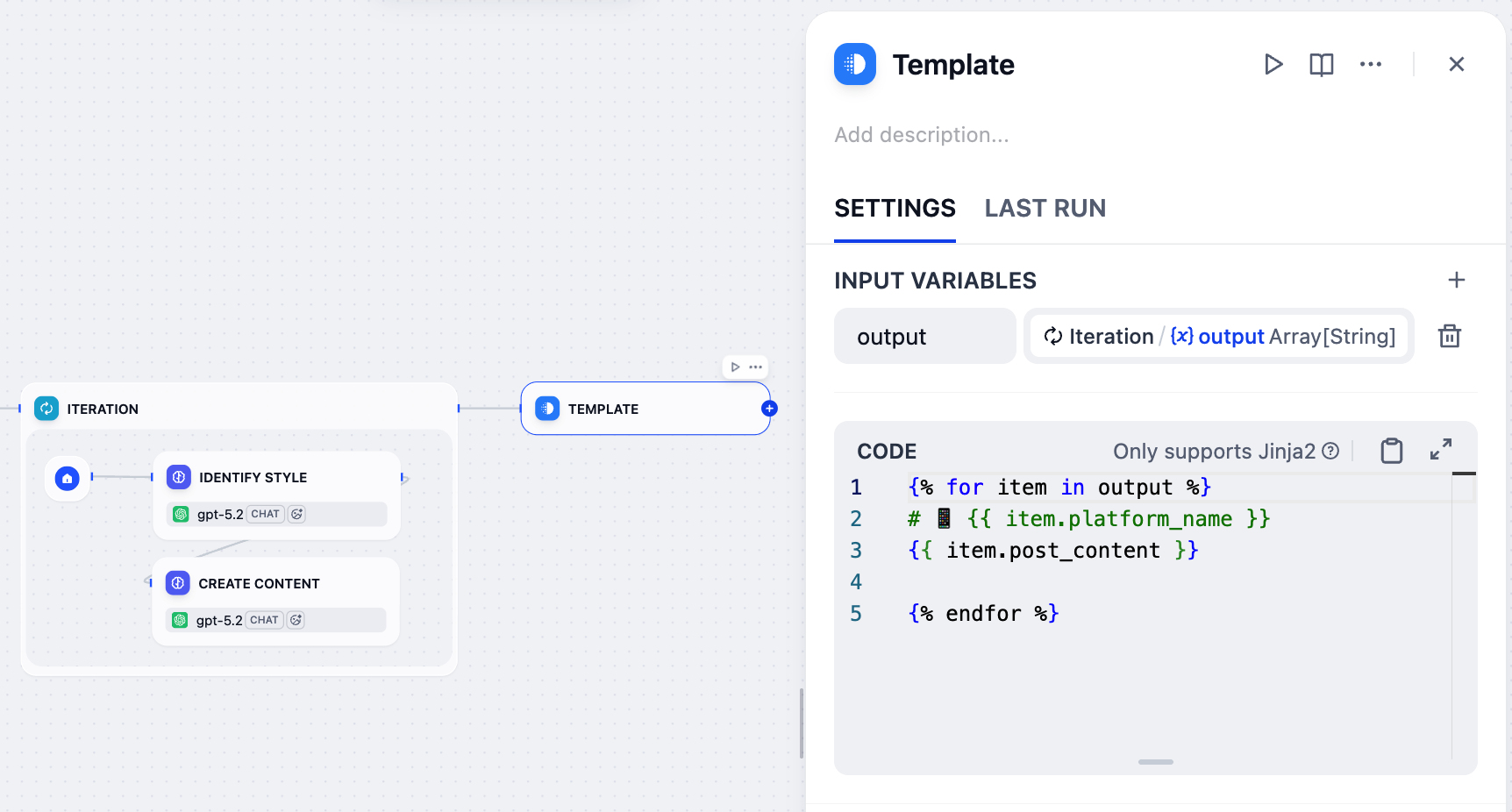 1. イテレーションノードの後に、テンプレートノードを追加します。
2. テンプレートノードのパネルで、`Iteration/output`を入力変数として設定し、`output`と名前を付けます。
3. 以下の Jinja2 コードを貼り付けます:
```
{% for item in output %}
# 📱 {{ item.platform_name }}
{{ item.post_content }}
{% endfor %}
```
* `{% for item in output %}` / `{% endfor %}`:入力配列の各プラットフォーム - コンテンツペアをループします。
* `{{ item.platform_name }}`:電話絵文字付きの H1 見出しとしてプラットフォーム名を表示します。
* `{{ item.post_content }}`:そのプラットフォーム用に生成されたコンテンツを表示します。
* `{{ item.post_content }}`と`{% endfor %}`の間の空行は、最終出力でプラットフォーム間にスペースを追加します。
LLM も出力フォーマットを処理できますが、その出力は一貫性がなく予測不可能な場合があります。推論を必要としないルールベースのフォーマットについては、テンプレートノードがゼロトークンコストでより安定した信頼性の高い方法で処理します。
LLM は非常に強力ですが、適切なツールを使用するタイミングを知ることが、より信頼性が高くコスト効果の高い AI アプリケーションを構築する鍵です。
### 9. 結果をユーザーに返す:出力ノード
1. テンプレートノードの後に、出力ノードを追加します。
2. 出力ノードのパネルで、`Template/output`を出力変数として設定します。
## ステップ 3:テスト
ワークフローが完成しました!テストしてみましょう。
1. チェックリストがクリアされていることを確認します。
1. イテレーションノードの後に、テンプレートノードを追加します。
2. テンプレートノードのパネルで、`Iteration/output`を入力変数として設定し、`output`と名前を付けます。
3. 以下の Jinja2 コードを貼り付けます:
```
{% for item in output %}
# 📱 {{ item.platform_name }}
{{ item.post_content }}
{% endfor %}
```
* `{% for item in output %}` / `{% endfor %}`:入力配列の各プラットフォーム - コンテンツペアをループします。
* `{{ item.platform_name }}`:電話絵文字付きの H1 見出しとしてプラットフォーム名を表示します。
* `{{ item.post_content }}`:そのプラットフォーム用に生成されたコンテンツを表示します。
* `{{ item.post_content }}`と`{% endfor %}`の間の空行は、最終出力でプラットフォーム間にスペースを追加します。
LLM も出力フォーマットを処理できますが、その出力は一貫性がなく予測不可能な場合があります。推論を必要としないルールベースのフォーマットについては、テンプレートノードがゼロトークンコストでより安定した信頼性の高い方法で処理します。
LLM は非常に強力ですが、適切なツールを使用するタイミングを知ることが、より信頼性が高くコスト効果の高い AI アプリケーションを構築する鍵です。
### 9. 結果をユーザーに返す:出力ノード
1. テンプレートノードの後に、出力ノードを追加します。
2. 出力ノードのパネルで、`Template/output`を出力変数として設定します。
## ステップ 3:テスト
ワークフローが完成しました!テストしてみましょう。
1. チェックリストがクリアされていることを確認します。
 2. 最初に提供された参照図と照らし合わせてワークフローを確認し、すべてのノードと接続が一致していることを確認します。
3. 右上隅の **テスト実行** をクリックし、入力フィールドを入力して、**実行開始** をクリックします。
何を入力すればよいか分からない場合は、以下のサンプル入力を試してみてください:
* **ドラフト**:`We just launched a new AI writing assistant that helps teams create content 10x faster.`
* **ファイルをアップロード**:空のまま
* **ボイス&トーン**:`Friendly and enthusiastic, but professional`
* **ターゲットプラットフォーム**:`Twitter and LinkedIn`
* **言語**:`English`
成功した実行では、各プラットフォームに個別の投稿を含むフォーマットされた出力が生成されます:
2. 最初に提供された参照図と照らし合わせてワークフローを確認し、すべてのノードと接続が一致していることを確認します。
3. 右上隅の **テスト実行** をクリックし、入力フィールドを入力して、**実行開始** をクリックします。
何を入力すればよいか分からない場合は、以下のサンプル入力を試してみてください:
* **ドラフト**:`We just launched a new AI writing assistant that helps teams create content 10x faster.`
* **ファイルをアップロード**:空のまま
* **ボイス&トーン**:`Friendly and enthusiastic, but professional`
* **ターゲットプラットフォーム**:`Twitter and LinkedIn`
* **言語**:`English`
成功した実行では、各プラットフォームに個別の投稿を含むフォーマットされた出力が生成されます:
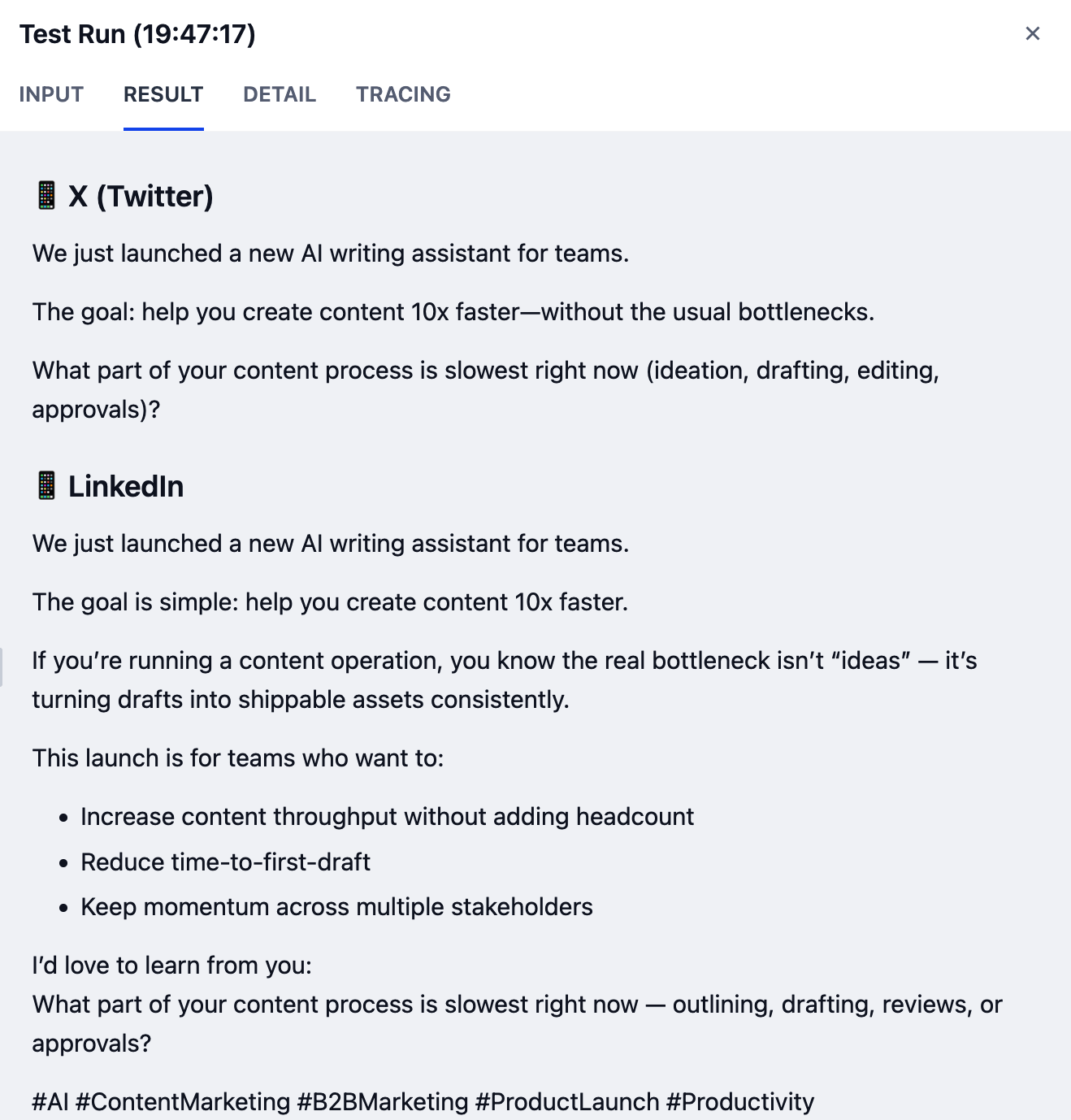 使用するモデルによって結果が異なる場合があります。より高い能力を持つモデルは、一般的により高品質な出力を生成します。
前のノードからの異なる入力に対するノードの反応をテストするには、ワークフロー全体を再実行する必要はありません。キャンバスの下部にある **キャッシュされた変数を表示** をクリックし、リストから変更したい変数を見つけて、その値を編集するだけです。
エラーが発生した場合は、対応するノードの **最後の実行** ログをチェックして、問題の正確な原因を特定します。
## ステップ 4:公開と共有
ワークフローが期待通りに実行され、結果に満足したら、**公開** > **更新を公開**をクリックして、ライブで共有可能にします。
後で変更を加えた場合は、更新が有効になるように必ず再度公開することを忘れないでください。
使用するモデルによって結果が異なる場合があります。より高い能力を持つモデルは、一般的により高品質な出力を生成します。
前のノードからの異なる入力に対するノードの反応をテストするには、ワークフロー全体を再実行する必要はありません。キャンバスの下部にある **キャッシュされた変数を表示** をクリックし、リストから変更したい変数を見つけて、その値を編集するだけです。
エラーが発生した場合は、対応するノードの **最後の実行** ログをチェックして、問題の正確な原因を特定します。
## ステップ 4:公開と共有
ワークフローが期待通りに実行され、結果に満足したら、**公開** > **更新を公開**をクリックして、ライブで共有可能にします。
後で変更を加えた場合は、更新が有効になるように必ず再度公開することを忘れないでください。